(点击
上方蓝字
,快速关注我们)
编译:伯乐在线专栏作者 - 郑芸
如有好文章投稿,请点击 → 这里了解详情
导语
学习新技能最好的方法是实践!
本文是帮助 R 用户增强技能和为数据科学进阶而学习 Python (从零开始)。毕竟,R 和 Python 是数据科学从业者必需掌握的两门最重要的编程语言。

Python 是一门功能强大和多用途的编程语言,在过去几年取得惊人发展。它过去用于 Web 开发和游戏开发,现在数据分析和机器学习也要用到它。数据分析和机器学习是 Python 应用上相对新的分支。
作为初学者,学习 Python 来做数据分析是比较痛苦的。为什么?
在谷歌上搜索“Learn Python ”,你会搜到海量教程,但内容只是关于学习 Python 做 Web 开发应用。那你如何找到方法?
在本教程,我们将探讨 Python 在执行数据操作任务上的基础知识。同时,我们还将对比在 R 上是如何操作的。这种并行比较有助于你将 R 和 Python 上的任务联系起来。最后,我们将采用一个数据集来练习我们新掌握的 Python 技能。
注意:阅读这篇文章时最好具备一定的 R 基础知识。
内容概要
-
为什么学习 Python(即使你已经懂 R )
-
理解 Python 的数据类型和结构(与 R 对比)
-
用 Python 写代码(与 R 对比)
-
用一个数据集实践 Python
为什么学习 Python(即使你已经懂R)
毫无疑问,R 在它自身的领域是极其强大的,实际上,它最初是用来做统计计算和操作。强大的社区支持使得初学者可以很快掌握 R .
但是, Python 正迎头赶上,无论成熟公司还是初创公司对Python 的接受程度要远远大于 R 。
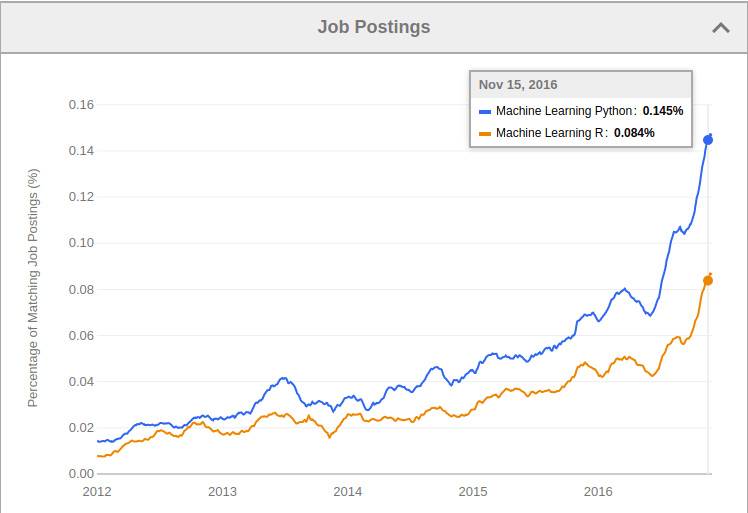
根据 indeed.com 提供的数据(2016年1月至2016年12月),“用 Python 做机器学习”的招聘信息数量要比“用 R 做机器学习” 增长快得多(约 123%)。这是因为:
-
Python 以更好的方式支持机器学习覆盖的全部范围。
-
Python 不仅支持模型构建,而且支持模型部署。
-
相比 R , Python 支持多种强大的诸如 keras、convnet,、theano 和 tensorflow 深度学习库。
-
Python的库相对独立,每个库都拥有数据科学工作者所需要的所有函数。你不需要像在 R 中一样在各种包之间来回查找一个函数。
理解 Python 数据类型和结构(与 R 对比)
编程语言是基于它的变量和数据类型来理解复杂的数据集。是的,假设你有一个 100 万行,50 列的数据集。编程语言会如何理解这些数据呢?
基本上,R 和 Python 都有未定义数据类型。独立和非独立变量都有着不同的数据类型。解释器根据数据类型分配内存。Python 支持的数据类型包括:
-
数值型(Numbers)
——存储数值。这些数值可以存储为4种类型:整型,长整型,浮点型,复数型。让我们分别理解。
-
整型(Integer)—— 它指的是整数类型,比如 10 、13 、91、102 等。相当于 R 中的整型(
integer
)。
-
长整型(Long)——它指的是用八进制或者十六进制表示的长整数,在 R 中,用 64 位包读取十六进制值。
-
浮点型(Float)——指的是小数值,比如 1.23 , 9.89 等, R 中浮点数包含在数值型(
numeric
)。
-
复数型(Complex)——它指的是复数值,比如 as 2 + 3i, 5i 等。不过这种数据类型在数据中不太常见。
布尔型(Boolean)
——布尔型只存储两个值(True 和 False)。在 R 中,它可以存储为因子(factor)类型或字符(character)类型。R 和 Python 的布尔值之间存在着微小的差别。在 R 中,布尔型存储为 TRUE 和 FALSE。在 Python 中,它们存储为 True 和 False 。字母的情况有差异。
字符串(Strings)
——它存储文本(字符)数据,如“elephant,”lotus,”等,相当于R的字符型(character)。
列表
——它与 R 的列表数据类型相同。它能够存储多种变量类型的值,如字符串、整数、布尔值等。
元组
—— R 中没有元组类型,把元组看成是 R 中的向量,它的值不能改变。即它是不可变的。
字典
—— 它提供支持 key-value 对的二维结构。简而言之,把键(key )看作是列名,对(pair)看作是列值。
因为 R 是统计计算语言,所有操作数据和读取变量的函数都是固有的。而另一方面,Python 数据的分析、处理、可视化函数都是从外部库调用。Python 有多个用于数据操作和机器学习的库。以下列举最重要的几个:
-
Numpy——在Python中它用于进行数值计算。它提供了庞大的诸如线性代数、统计等的数学函数库。它主要用于创建数组。在 R 中,把数组看作列表。它包含一个类(数字或字符串或布尔)或多个类。它可以是一维或多维的。
-
Scipy ——在Python中它用于进行科学计算。
-
Matplotlib——在 Python 中它用于进行数据可视化。在 R,我们使用著名的 ggplot2 库。
-
Pandas ——对于数据处理任务它极其强大。在 R 中,我们使用 dplyr,data.table 等包。
-
Scikit Learn—— 它是实现机器学习算法的强大工具。实际上,它也是 python 中用来做机器学习的最好工具。它包含建模所需的所有函数。
在某种程度上,对于数据科学工作者来说,最主要的是要掌握上面提到的 Python 库。但人们正开始使用的高级 Python 库有太多。因此,为了实际目标,你应该记住以下这些:
-
数组(Array)
——这与 R 的列表类似。它可以是多维的。它可以包含相同或多个类的数据。在多个类的情况下,会发生强制类型转换。
-
列表(List)
—— 相当于 R 中的列表。
-
数据框(Data Frame)
——它是一个包含多个列表的二维结构。R中有内置函数 data.frame,Python则从 pandas库中调用 Dataframe 函数。
-
矩阵(Matrix)
——它是二维(或多维)结构,包含同一类(或多个类)的所有值。把矩阵看成是向量的二维版。在R中,我们使用 matrix 函数。在Python中,我们使用 numpy.column_stack 函数。
到这里,我希望你已经明白了R和Python中数据类型和数据结构的基本知识。现在,让我们开始应用它们。
用Python写代码(对比R)
我们现在来使用在前面部分学到的知识,明白它们实际的含义。但在此之前,你要先通过Anaconda的 jupyter notebook 安装 Python(之前称为ipython notebook)。你可以点击这里下载(https://www.continuum.io/downloads)。你还可以下载其他 python IDEs 做数据分析。我希望你已经在电脑上安装了 R Studio 。
创建列表
在 R 中,创建列表使用的是 list 函数
my_list
list
(
'monday'
,
'specter'
,
24
,
TRUE
)
typeof
(
my_list
)
[
1
]
"list"
在 Python 中,创建列表使用的是方括号 [ ] 。
my_list
=
[
'monday'
,
'specter'
,
24
,
True
]
type
(
my_list
)
list
在 pandas 库中也可以得到相同的输出,在 pandas 中,列表称为序列。在 Python 中安装 pandas,写下:
#importing pandas library as pd notation (you can use any notation) #调用 pandas 库
import pandas
as
pd
pd_list
=
pd
.
Series
(
my_list
)
pd_list
0
monday
1
specter
2
24
3
True
数字(0,1,2,3)表示数组索引。你注意到什么了吗?Python 索引是从 0 开始,而 R 的索引从 1 开始。让我们继续了解列表子集在 R 和 Python 的区别。
#create a list # 创建一个列表
new_list
list
(
roll_number
=
1
:
10
,
Start_Name
=
LETTERS
[
1
:
10
])
把 new_list 看作一列火车。这列火车有两个名为 roll_number 和 Start_Name 的车厢 。在每个车厢中,有10人。所以,在列表构建子集中,我们可以提取车厢的值,车厢中的人等,等等。
#extract first coach information #提取第一个车厢信息
new_list
[
1
]
#or
df
[
'roll_number'
]
$
roll
_
number
[
1
]
1
2
3
4
5
6
7
8
9
10
#extract only people sitting in first coach #提取坐在第一个车厢中的人
new_list
[[
1
]]
#or
df
$
roll_number
#[1] 1 2 3 4 5 6 7 8 9 10
如果你查询一下 new_list [ 1 ] 的类型,你会发现它是一个列表,而 new_list [ [ 1 ] ] 类型是一个字符。类似地,在 Python 中,你可以提取列表组件:
#create a new list #创建一个新列表
new_list
=
pd
.
Series
({
'Roll_number'
:
range
(
1
,
10
),
'Start_Name'
:
map
(
chr
,
range
(
65
,
70
))})
Roll
_
number
[
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
]
Start
_
Name
[
A
,
B
,
C
,
D
,
E
]
dtype
:
object
#extracting first coach #提取第一个车厢
new_list
[[
'Roll_number'
]]
#or
new_list
[[
0
]]
Roll
_
number
[
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
]
dtype
:
object
#extract people sitting in first coach #提取坐在第一个车厢中的人
new_list
[
'Roll_number'
]
#or
new_list
.
Roll
_
number
[
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
]
R 和 Python 的列表索引有一个让人困惑的区别。如果你注意到在 R 中 [[ ]] 表示获取车厢的元素, 然而[[ ]] 在 Python 中表示获取车厢本身。
2. Matrix 矩阵
矩阵是由向量(或数组)组合而成的二维结构。一般来说,矩阵包含同一类的元素。然而,即使你混合不同的类(字符串,布尔,数字等)中的元素,它仍会运行。R 和 Python 在矩阵中构建子集的方法很相似,除了索引编号。重申,Python 索引编号从 0 开始,R 索引编号从 1 开始。
在 R 中,矩阵可以这么创建:
my_mat
matrix
(
1
:
10
,
nrow
=
5
)
my_mat
#to select first row #选取第一行
my_mat
[
1
,]
#to select second column #选取第二列
my_mat
[,
2
]
在Python中,我们会借助 NumPy 数组创建一个矩阵。因此,我们先要加载 NumPy 库。
import numpy
as
np
a
=
np
.
array
(
range
(
10
,
15
))
b
=
np
.
array
(
range
(
20
,
25
))
c
=
np
.
array
(
range
(
30
,
35
))
my_mat
=
np
.
column_stack
([
a
,
b
,
c
])
#to select first row #选取第一行
my_mat
[
0
,]
#to select second column #选取第二列
my_mat
[
:
,
1
]
3. 数据框(Data Frames)
数据框为从多来源收集而来的松散的数据提供了一个急需的骨架。它类似电子表格的结构给数据科学工作者提供了一个很好的图片来展示数据集是什么样子。在R中,我们使用 data.frame() 函数创建一个数据框。
data_set
data
.
frame
(
Name
=
c
(
"Sam"
,
"Paul"
,
"Tracy"
,
"Peter"
),
Hair_Colour
=
c
(
"Brown"
,
"White"
,
"Black"
,
"Black"
),
Score
=
c
(
45
,
89
,
34
,
39
))
那么,我们知道一个数据框是由向量(列表)的组合创建的。在 Python 中创建数据框,我们将创建一个字典(数组的组合),并且在 pandas 库的 Dataframe()函数中附上字典。
data_set
=
pd
.
DataFrame
({
'Name'
:
[
"Sam"
,
"Paul"
,
"Tracy"
,
"Peter"
],
'Hair_Colour'
:
[
"Brown"
,
"White"
,
"Black"
,
"Black"
],
'Score'
:
[
45
,
89
,
34
,
39
]})
现在,让我们看下操作 dataframe 最关键的部分,构建子集。实际上,大部分数据操作都包含从各个可能的角度切割数据框。让我们逐个看下任务:
#select first column in R #在 R 中选取第一行
data_set
$
Name
# or
data_set
[[
"
Name
]]
#or
data_set
[
1
]
#select first column in Python #在 Python 中选取第一列
data_set
[
'Name'
]
#or
data_set
.
Name
#or
data_set
[[
0
]]
#select multiple columns in R # 在 R 中选取多列
data_set
[
c
(
'Name'
,
'Hair_Colour'
)]
#or
data_set
[,
c
(
'Name'
,
'Hair_Colour'
)]
#select multiple columns in Python #在 Python 中选取多行
data_set
[[
'Name'
,
'Hair_Colour'
]]
#or
data_set
.
loc
[
:
,[
'Name'
,
'Hair_Colour'
]]
.loc 函数用于基于标签的索引
到这里我们大致明白了 R 和 Python 中的数据类型、结构和格式。让我们用一个数据集来探索 python 中数据的其他面。
用一个数据集实践 Python
强大的 scikit-learn 库包含一个内建的数据集库。为了我们实践的目的,我们将采用波士顿住房数据集(Boston housing data set)。做数据分析时,它是一个很流行的数据集。
#import libraries #调用库
import numpy
as
np
import pandas
as
pd
from
sklearn
.
datasets import
load_boston
#store in a variable #存储在一个变量中
boston
=
load_boston
()
变量boston是一个字典。回顾一下,字典是key-value对的组合,让我看下键(key)的信息:
boston
.
keys
()
[
'data'
,
'feature_names'
,
'DESCR'
,
'target'
]
现在我们知道我们需要的数据集驻留在key数据中。我们也看到,对于功能名称有一个单独的key。我认为数据集不会分配列名。让我们来检查下我们要处理的列名。
print
(
boston
[
'feature_names'
])
[
'CRIM'
'ZN'
'INDUS'
'CHAS'
'NOX'
'RM'
'AGE'
'DIS'
'RAD'










