
本文简要介绍新近在
IEEE TPAMI 2020
发表的
论文
"
TE141K: Artistic Text Benchmark for Text Effect Transfer"
的主要工作
。该论文主要针对文字字效迁移问题,首先搜集了大规模成对的字效数据库
TE141K
,然后提出了
TET-GAN
字效迁移模型,最后在
14
种图像风格化模型上进行了性能比较,建立了文字字效迁移问题的基准
(Benchmark)
,以便于后续相关研究的性能评估和分析。

图
1. TE141K
数据库
数据集与
Benchmark
网站可长按如下二维码:

文字字效生成技术的目标是自动为文字增添诸如颜色、描边、阴影、反射和纹理等的艺术效果,使之看上去更生动更有吸引力。其中,字效迁移任务指为文字渲染指定的参考样例字效,可被广泛地应用于广告、杂志、海报等平面设计中。然而艺术字的人工制作过程繁琐,需要一定的技术。全自动字效生成方法具有巨大的商用价值。目前已有一些成熟的图像风格化算法在绘画风格迁移上取得优良的性能,并且围绕字效迁移也提出了诸如
T-Effect
、
UT-Effect
、
TET-GAN
等风格化模型。为了促进字效迁移相关研究的发展,亟待建立一个字效迁移的基准,提供可靠的数据和分析用以评价不同图像风格化模型在字效迁移任务上的性能。今天介绍的文章提出了新的大规模字效数据集,并建立了字效迁移的基准,其提出的字效迁移模型在不同的字效迁移任务中取得了不错的性能。
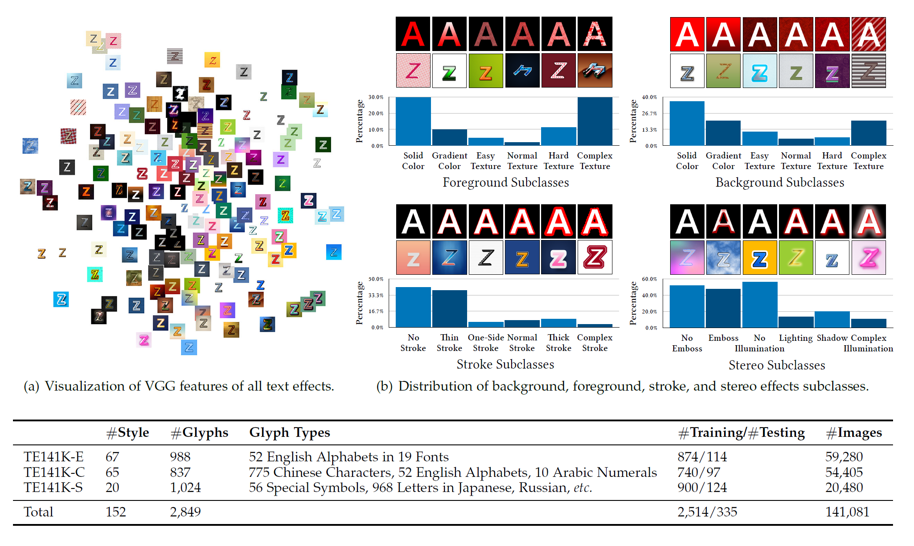
图
2. TE141K
数据库统计数据
如图2所示,
TE141K
总计包含
141,081
张成对的文字/字效图像,其中共计152种不同的字效风格,涵盖中英等不同的字形。根据字形,将整个数据库划分为三个子数据集:
TE141K-E
只包含英文字母,适合作为基础的训练集;
TE141K-C
训练集包含汉字,测试集既包含汉字又包含字母和数字,适合更进一步地考察风格化模型对字形的泛化性;
TE141K-S
包含中英文以外的小语种和特殊字符,在文章中用于作为单样本风格训练的数据考察模型对不同风格的适应性。
在风格方面,字效具有一定的多样性。在前、背景纹理方面涵盖了纯色、渐变色和复杂程度不同的纹理,在描边特效方面涵盖了不同粗细程度和规则与不规则的文字描边效果,在立体特效方面涵盖了浮雕、光照、阴影及其组合的
3D
效果。
该数据集的提出可以支持多种不同难易程度的字效迁移任务,其中这篇文章对以下3项任务在不同风格化模型上建立了基准。
1、监督的多风格字效迁移:模型在整个
TE141K
数据集上训练和测试。
2、监督的单样本字效迁移:模型可在
TE141
K-E和TE141K-C
上训练,在
TE141K-S
上测试,测试提供目标风格的一张字效图像及其对应的文字图像作为风格参考,允许模型在该样本上微调。
3、无监督的单样本字效迁移:模型可在
TE141K-E
和
TE141K-C
上训练,在
TE141K-S
上测试,测试提供目标风格的一张字效图像作为风格参考,不提供其对应的文字图像,允许模型在该样本上微调。
除此之外,
TE141K
还支持无监督/半监督的多风格字效迁移、少样本字效迁移等任务,可用于各类图像风格化模型的训练和测试。
这篇文章同时提出了一个文字特效迁移模型。采用字形编解码器和字效编解码器构建了一个字效迁移生成对抗网络
TET-GAN
,并通过字形编解码,艺术字去风格化和文字风格化三个方面训练网络学习字效和字形特征的解耦与组合,从而支持单一网络同时处理多种字效风格。此外,文章提出了一种自学习的微调方案,允许网络在单样本上扩展新风格。感兴趣的读者可以参阅对
TET-GAN
的解读推文(https://mp.weixin.qq.com/s/I5WfG2aCMakao3IF30rLGg)。
图3展示了用于比较的图像风格化算法,包含全局统计模型、局部图像块模型以及基于生成对抗网络的模型。评价指标包含传统的
PSNR、SSIM
,基于视觉感知的
Perceptual
Loss
和基于
Gram
矩阵的
Style Loss
,同时还包含主观的用户打分。

图3.
比较算法概览
图4-6分别展示了不同图像风格化模型在监督的多风格字效迁移,监督的单样本字效迁移,无监督的单样本字效迁移三个任务上的定量评价结果与主观视觉比较。
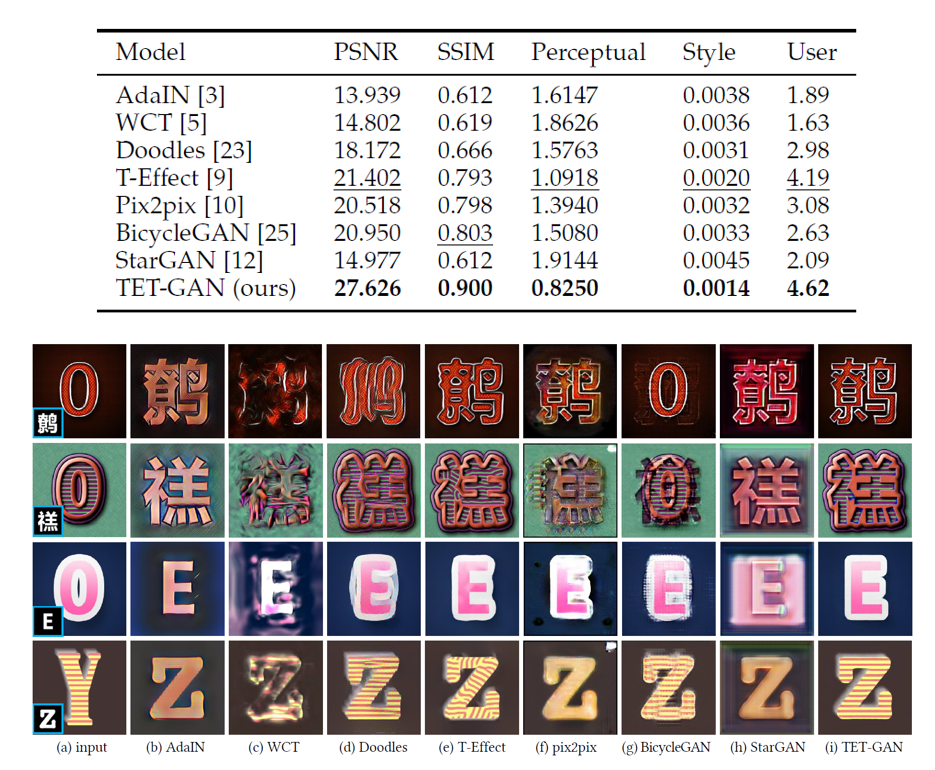
图4.
监督的多风格字效迁移的定量评价与视觉比较
在监督的多风格字效迁移任务中,
AdaIN
[2]和
WCT
[3]无法生成纹理细节,在主观评价和客观评价上都取得较低的分数。
Doodles
[7]
难以保持文字字形,
T-Effect[8]
则出现纹理在全局的不一致性。
Pix2p
ix[10]
和
BicycleGAN
[11]
无法完全将样例图像中的风格调整到新的文字上,产生了许多鬼影。
StarGAN[12]
无法生成纹理细节。
TET-GAN
在各个指标上都取得了最优的分数
。


图5.
监督的单样本字效迁移的定量评价与视觉比较
在监督的单样本字效迁移任务中,
Analogy
[4]
和
Dood
les
[7]
无法保持文字字形,
Pix2pix
[10]
则出现色偏,
T-Effect
[8]
和
TET-GAN
取得最佳表现。
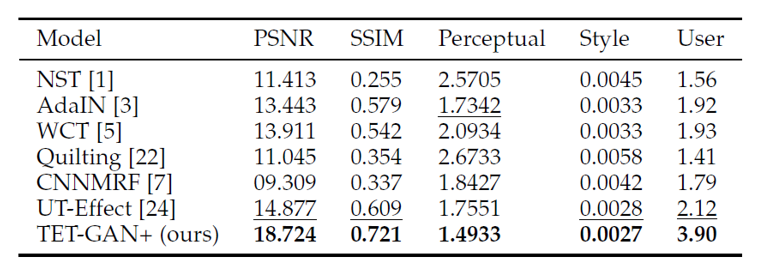

图6.
无监督的单样本字效迁移的定量评价与视觉比较
在更困难的无监督的单样本字效迁移任务上,
NST[1]、AdaIN[2]、WCT[3]、Quiting[5]、CNNMRF[6]、UT-Effect[9]
等都无法有效建立风格与内容之间的映射关系,因此具有明显的风格差异。
此外,文章还分析了字效迁移的难度(以用户主观打分的分数衡量)与字效风格本身的关系,通过对用户打分与图2(b)中的字效种类进行回归分析,发现非对称的文字描边效果以及背景图中的复杂纹理是字效迁移的难点,而对于各类模型都最容易处理的特效为普通的文字描边效果,为后续字效迁移的改进方向指明了要点。

图7.
联合字形风格迁移与字效风格迁移的文字风格化
图7展示了将
TET-GAN
扩展到字形风格迁移的结果,通过将在字效数据集上训练的模型和在字形数据集上训练的模型组合使用,
TET-GAN
能同时迁移参考风格图像中的字形和字效风格,从而获得更一致的风格化结果。
1.
搜集了一个大规模的字效数据集
TE1
41K
,能用于字效迁移、多领域迁移、图像转换等多种问题的研究。
2. 提出了一种基于字形字效特征解耦与重组的字效迁移方法,构建了字效迁移生成对抗网络
TET-GAN




