欢迎加入创乎终身VIP会员和CEO私董会群
目前,能做出像 o1 一样的推理模型,被坊间成为留成大模型牌桌的一道门槛,当前市场主导的观点认为,推理能力是模型扩展定律的自然产物,换句话说,实现高效推理需要大型模型。
而 DeepSeek-R1 则打破了这一传统认知,通过巧妙的训练后处理流程,以极低的计算成本实现了与 GPT-o1 相当的性能。这无疑是一项令人惊叹的突破。
本文将深入探讨 DeepSeek-R1 架构和训练过程的技术细节,重点介绍关键创新和贡献。
01 DeepSeek-R1 简介及动机
大型语言模型 (LLM) 领域取得了显著的进步,但实现强大的推理能力仍然是一项重大挑战。许多模型依赖于广泛的监督微调 (SFT),这可能计算成本高昂,并且可能无法完全释放模型的自我改进潜力。DeepSeek-R1 及其前身 DeepSeek-R1-Zero 代表了对这种范式的背离,探索了强化学习 (RL) 的力量,以开发和增强 LLM 中的推理能力。
DeepSeek-R1 的开发目标是探索 LLM 的潜力,在不依赖监督数据的基础上发展推理技能。研究始于纯 RL 的想法,以允许模型自我进化。这种方法产生了 DeepSeek-R1-Zero,该模型展示了纯粹通过 RL 激励推理能力的可能性。
DeepSeek-R1 的创建是为了解决 DeepSeek-R1-Zero 中观察到的可读性差和语言混合问题,同时进一步提高推理性能。DeepSeek-R1 在 RL 之前结合了多阶段训练和冷启动数据方法。DeepSeek 项目的目标是创建更好的模型并与研究社区共享。
02 DeepSeek-R1-Zero:
一种纯粹的强化学习方法
DeepSeek-R1-Zero 是一款通过大规模强化学习 (RL) 训练的模型,无需任何事先监督微调 (SFT)。(这种方法旨在探索模型在推理中的自我进化能力。)
-
强化学习算法:
DeepSeek-R1-Zero 利用组相对策略优化 (GRPO)。GRPO 是一种具有成本效益的 RL 方法,它省略了 critic 模型的使用,而是根据组分数估计基线。给定一个问题 q,GRPO 从旧策略中抽取一组输出,并通过最大化定义的目标函数来优化策略。目标函数包括一个优势项,使用组产出的奖励和一个 Kullback-Leibler (KL) 背离项计算,以确保策略更新不会太大。
-
奖励建模:
DeepSeek-R1-Zero 的奖励系统侧重于准确性和格式。
-
准确率奖励
评估响应的正确性。例如,数学问题需要特定格式的精确答案,这允许基于规则的验证。
-
格式奖励
强制将模型的思维过程包含
在
和标签中。值得注意的是,DeepSeek-R1-Zero 不使用基于过程或结果神经的奖励模型。
-
培训模板:
一个简单的模板指导模型产生一个推理过程,然后是最终答案。该模板旨在消除特定于内容的偏差,以观察模型在 RL 期间的自然进展。
在训练期间,DeepSeek-R1-Zero 在 AIME 2024 基准测试中显示出显著的改进,pass@1从 15.6% 提高到 71.0%,与 OpenAI 的 o1-0912 相当。
在多数投票的情况下,其得分进一步提高到 86.7%。该模型还通过随着训练的进行增加其思考时间(响应长度)来展示自我进化,从而实现更复杂的问题解决策略,例如反思和探索替代方法。该模型还展示了一个 “顿悟时刻”,它学会了通过分配更多的思考时间来重新思考其最初的方法。
03 DeepSeek-R1:
整合冷启动数据和多阶段训练
虽然 DeepSeek-R1-Zero 展示了纯 RL 的潜力,但它存在可读性差和语言混合等问题。DeepSeek-R1 的开发是为了解决这些问题,并通过包含少量“冷启动”数据的多阶段训练管道进一步提高性能。
-
冷启动数据:
DeepSeek-R1 在 RL 训练之前对数千个长思维链 (CoT) 示例进行了微调,这充当了“冷启动”。这些示例是使用长 CoT 的 few-shot 提示、通过反射和验证直接提示模型获得详细答案、完善 DeepSeek-R1-Zero 的输出以及由人工注释者进行后处理等方法收集的。此冷启动数据通过使用可读的输出格式来帮助解决可读性问题,该格式在每个响应的末尾包含摘要,并筛选掉对用户不友好的响应。
-
输出格式
定义
为 :|special_token|
|special_token|,推理过程是查询的 CoT 和总结推理结果的摘要。
-
面向推理的强化学习:
在对冷启动数据进行微调后,DeepSeek-R1 经历了与 DeepSeek-R1-Zero 相同的大规模 RL 训练。此阶段侧重于增强编码、数学、科学和逻辑推理任务的推理能力。引入了语言一致性奖励来减少 RL 训练期间的语言混合,尽管消融实验表明该奖励会导致性能小幅下降。
-
拒绝抽样和监督微调:
在面向推理的 RL 过程中达到收敛后,通过使用 RL 检查点的拒绝抽样生成 SFT 数据,并结合来自 DeepSeek-V3 的监督数据,例如写作和事实 QA。通过使用 DeepSeek-V3 的生成式奖励模型来判断真实情况和模型预测,数据扩展到基于规则的奖励评估之外。DeepSeek-V3 中还包含非推理数据,以增强模型的通用功能。
-
适用于所有场景的强化学习:
第二个 RL 阶段使模型与人类偏好保持一致,侧重于有用性和无害性。基于规则的奖励用于推理数据,而奖励模型则捕获一般数据中的偏好。
04 蒸馏和评估
DeepSeek-R1 的推理能力也通过蒸馏转移到更小、更高效的模型中。
-
蒸馏过程:
Qwen 和 Llama 等开源模型使用 DeepSeek-R1 中的 800k 样本直接进行了微调。这种方法可以有效地提高较小模型的推理能力。使用的基本模型包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。仅将 SFT 应用于蒸馏模型,没有 RL 阶段。
-
评估指标和基准:
模型根据一系列基准进行评估,包括 MMLU、MMLU-Redux、MMLU-Pro、C-Eval、CMMLU、IFEval、FRAMES、GPQA Diamond、SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench、Codeforces、中国全国高中数学奥林匹克竞赛 (CNMO 2024) 和 2024 年美国数学邀请赛考试 (AIME 2024)。此外,开放式生成任务是使用 LLM 来评判的,特别是 AlpacaEval 2.0 和 Arena-Hard。评估提示遵循 DeepSeek-V3 中的设置,使用 simple-evals 框架或其原始协议。
-
主要发现:
DeepSeek-R1 在一系列任务上实现了与 OpenAI-o1–1217 相当的性能。与 DeepSeek-V3 相比,它在 STEM 相关问题中表现出卓越的性能,证明了大规模强化学习的有效性。DeepSeek-R1 还展示了强大的文档分析能力以及基于事实的查询能力。该模型在编写任务和开放域问答方面也表现出色。在数学任务上,DeepSeek-R1 与 OpenAI-o1–1217 相当。提炼模型显示出显着的改进,DeepSeek-R1-7B 的性能优于 GPT-4o-0513。此外,DeepSeek-R1–14B 在所有指标上都超过了 QwQ-32B-Preview。蒸馏的 32B 和 70B 模型在大多数基准测试中明显优于 o1-mini,突出了蒸馏的有效性。
05 主要贡献、讨论和未来方向
DeepSeek-R1 的开发突出了几个关键贡献:
-
用于推理的纯 RL:
它验证了 LLM 中的推理能力可以纯粹通过 RL 来激励,而无需 SFT。
-
有效的多阶段 RL 训练管道:
该方法结合了两个 RL 和两个 SFT 阶段,以改进推理模式并与人类偏好保持一致。
-
推理的提炼:
DeepSeek-R1 表明,可以将较大模型的推理模式提炼成较小的模型,从而提高性能。
R1 论文还讨论了一些不成功的尝试,包括流程奖励模型 (PRM) 和 Monte Carlo Tree Search (MCTS)。
未来的研究方向包括:
-
一般能力增强:
扩展了 DeepSeek-R1 在函数调用、多轮交互、复杂角色扮演和 JSON 输出方面的能力。
-
语言混合缓解:
解决处理英语和中文以外的语言的查询时的语言混合问题。
-
提示工程:
提高模型对提示变化的鲁棒性,超越其对小样本提示的敏感性。
-
软件工程任务:
通过实施拒绝抽样或异步评估以提高效率,将 RL 扩展到软件工程任务。
Last but not least
DeepSeek-R1 代表了具有增强推理能力的大语言模型开发的一项重要突破。通过创新地结合强化学习技术、多阶段训练管道和高效的蒸馏方法,DeepSeek-R1 不仅展现出卓越的性能,还为 AI 的自我进化与知识迁移潜力提供了重要启示。其模型及提炼版本的开源,将为学术研究和行业应用带来深远影响,进一步推动这一领域的快速发展。
DeepSeek,牛逼!

 大家
确定
加入在加我
主
微信
大家
确定
加入在加我
主
微信
创乎合伙人【
老李企业家私董会
】,群里的
240位老板。
他们
都是给我打过款的客户,打款几千、几万、到几十万不等。
如果你在创业,或者想寻找“创业者优质客户”,欢迎加入我的社群。
如果您想打造个人IP加我
微信:chuanghuceo
手把手教你打造个人品牌 一步一步带你做个赚钱的IP
如何让你的IP价值百万
如何从默默无闻,到身价百倍
个人品牌是未来最大的商业入口和增长引擎
也是私域流量的集合体
这个时候,普通人最正确的逆袭方式就是打造创始人IP+小团队+高利润+私域高质量用户就是这个时代最正确的赚钱方式。


项目2:百度聚合名片打造
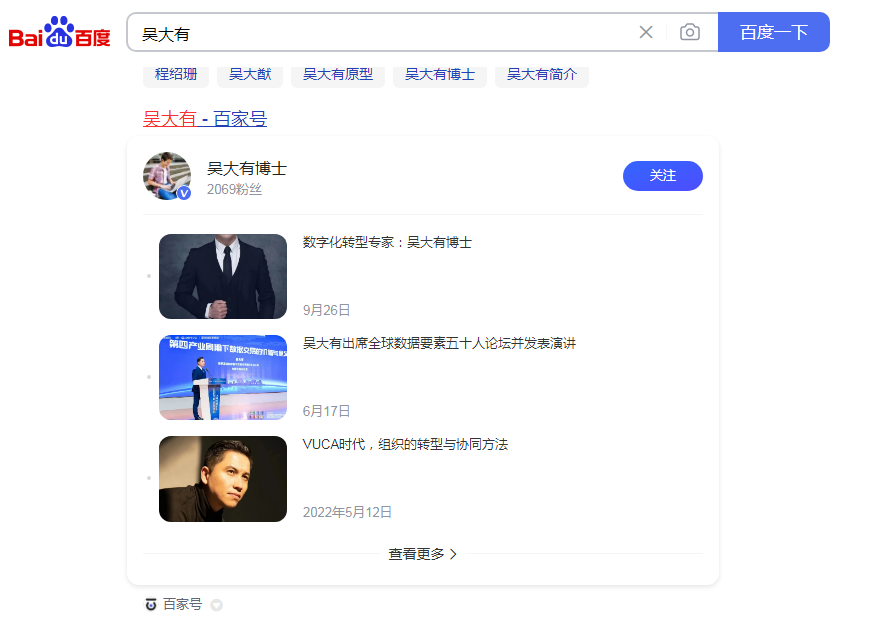
个人百度名片
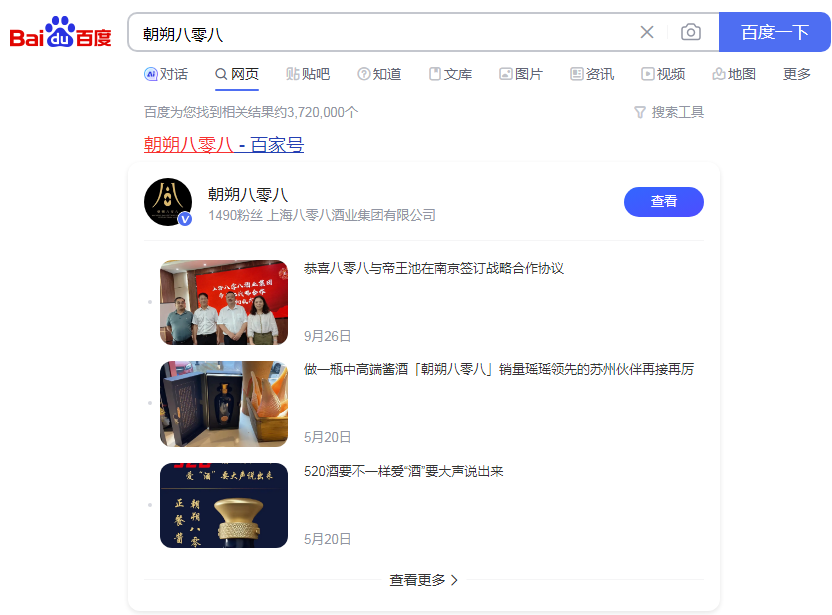
品牌百度名片
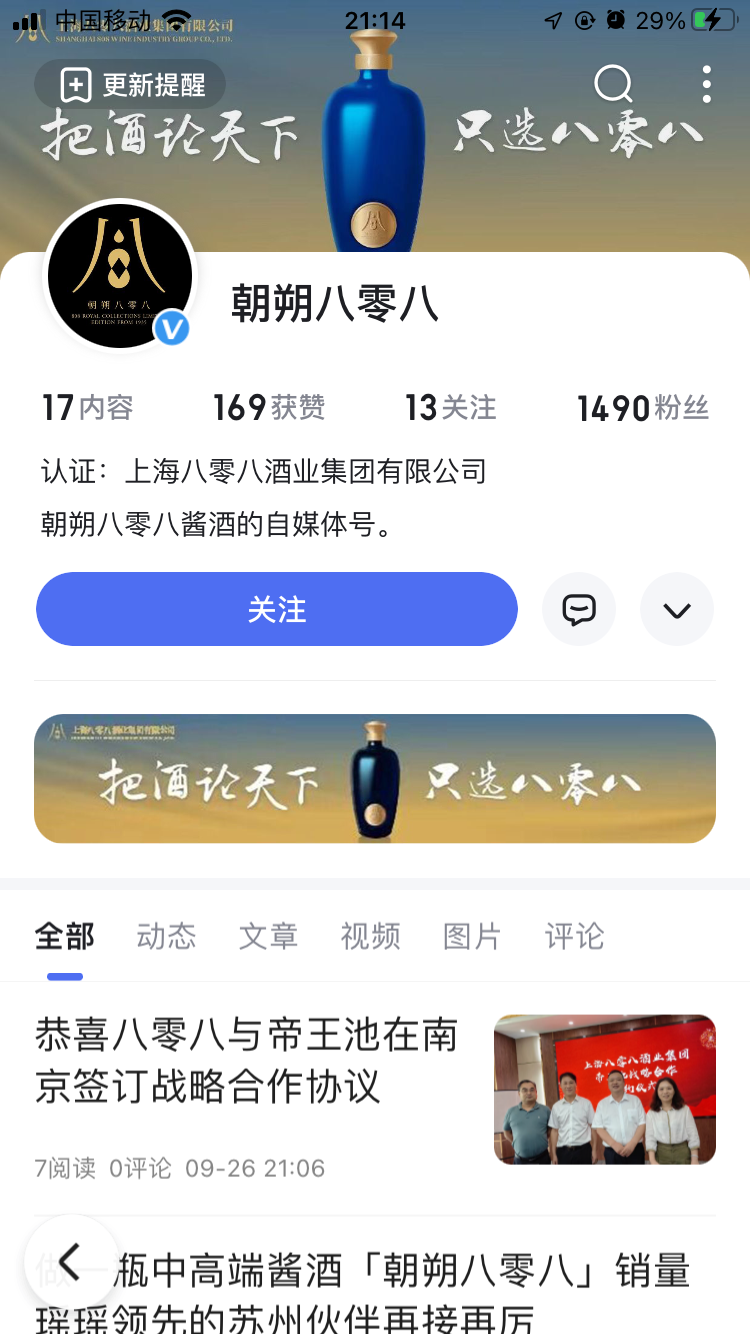
手机端展示
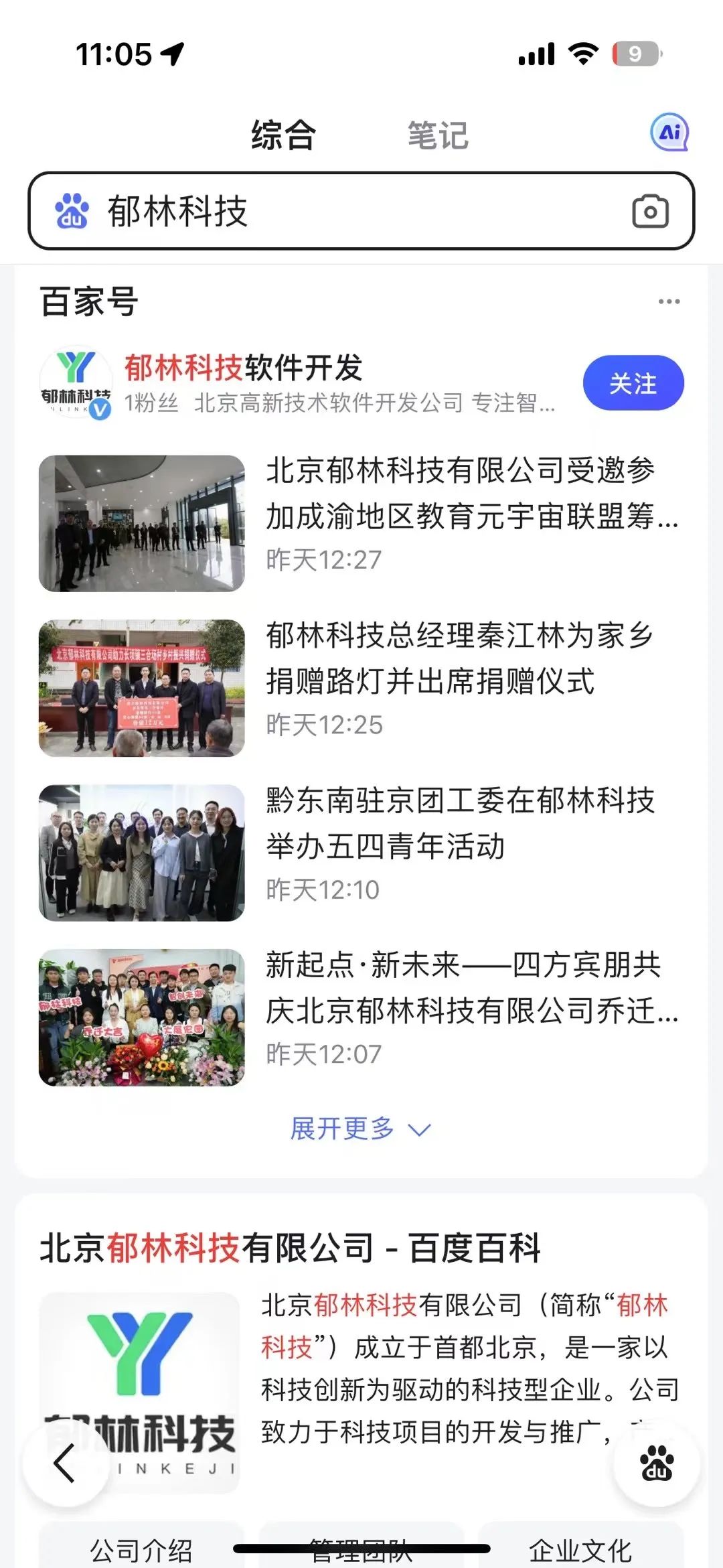
企业百度名片
从不同位置,去突显了“聚合名片”的价值。
通过聚合名片,实现了官网、自媒体、电话、小程序、新产品等信息,在同一个页面聚合。同时实现涨粉。
聚合名片的权重排名,仅次于百度花钱的竞价广告。见图2
所以,这是一个永久的免费广告位,价值巨大。










