相似性搜索的规模和速度一直是研究者努力想要克服的难题。近日,Facebook 人工智能研究团队在 arXiv 发布的新论文《Billion-scale similarity search with GPUs》宣称在这一问题上取得了重大进展,在 GPU 上实现了十亿规模级的相似性搜索。该团队已经将相关实现的代码进行了开源。机器之心在此对该研究论文及其代码项目进行了简单介绍。

摘要
相似性搜索(similarity search)可以在用于图像或视频等复杂数据处理的专用数据库系统中寻找应用,这些复杂数据通常是用高维特征表示的,而且往往需要特定的索引结构(indexing structure)。本论文解决了让这种任务更好地利用 GPU 的问题。尽管 GPU 擅长数据并行任务,但之前的方法会在并行性不高的算法(如 k-min selection)上遇到瓶颈或不能有效利用内存的层次结构。我们提出了一种用于 k-selection 的设计,其可以以高达理论峰值性能 55% 的速度进行运算,从而实现了比之前最佳的 GPU 方法快 8.5 倍的最近邻搜索。我们通过为基于积量化(product quantization)的暴力计算、近似和压缩域搜索(compressed-domain search)提出优化过的设计,从而将其应用到了不同的相似性搜索场景中。在所有这些场景中,我们的方法的表现都远远超越了之前的最佳表现。我们的实现可以在 35 分钟内从 Yfcc100M 数据集的 9500 万张图像上构建一个高准确度的 k-NN 图(graph),也可以在 12 个小时内在 4 个 Maxwell Titan X GPU 上构建一个连接了 10 亿个向量的图。我们已经开源了我们的方法,以便人们进行比较和重复利用。
WarpSelect 简介
我们的 k-selection 实现名叫 WarpSelect,其完全在寄存器(register)中维持状态,且仅需要在数据上进行单次通过,从而避免了 cross-warp synchronization。其使用了 merge-odd 和 sort-odd 作为原语(primitive)。因为寄存器文件能比共享内存提供远远更多的存储,所以它支持 k ≤ 1024。每一个 warp 都专用于 k-selection 的 n 个数组 [ai] 中的单一一个。如果 n 足够大,那么每个 [ai] 一个 warp 会导致 GPU 被完全占用。如果 l 是预先已知的,每个 warp 的大 l 会通过递归分解(recursive decomposition)进行处理。
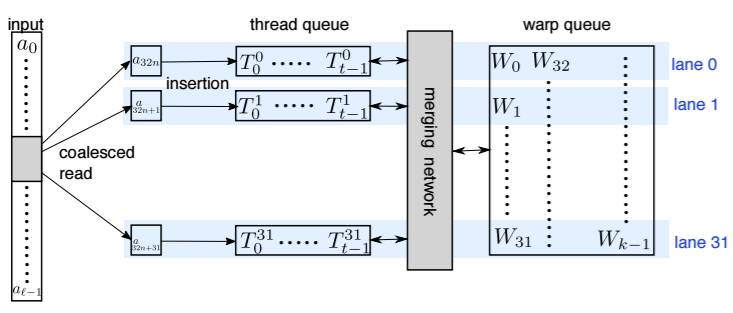
图 2:WarpSelect 概览。输入值从左边流入,右边的 warp queue 保存其输出结果

算法 3:WarpSelect 的伪代码
以下是对 FAIR 开源的相关项目 Faiss 的 README.md 文件的编译介绍:
项目地址:https://github.com/facebookresearch/faiss
Faiss 是一个用于有效的相似性搜索和密集向量聚类的库。其包含了在任何大小(甚至可以大到装不进 RAM)的向量集中进行搜索的算法。其也包含用于评估和参数调整的支持性代码。Faiss 是用 C++ 编写的,且带有用于 Python/numpy 的完整封装器(wrapper)。其中一些最有用的算法是在 GPU 上实现的。Faiss 由 Facebook AI Research 开发。
介绍
Faiss 包含几种用于相似性搜索的方法。其假定其实例可以被表示成向量且可以通过整数识别,然后这些向量可以与 L2 实例或点积进行比较。类似于一个查询向量(query vector)的向量是那些有最低 L2 实例或最高点积的带有查询向量的向量。其也支持余弦相似性(cosine similarity),因为这是在归一化的向量上的点积。
这里的大多数方法都和那些基于二元向量和紧凑的量化代码类似,仅使用了一种对向量的压缩过的表示,也不要求保持原始向量。这通常会导致搜索准确度下降,但这些方法可以在单个向量上在主内存中扩展到数十亿个向量。
该 GPU 实现可以接受来自 CPU 或 GPU 内存的输入。在一个带有 GPU 的服务器上,其 GPU 索引可以被用作其 CPU 索引的插入替换(比如,使用 GpuIndexFlatL2 替代 IndexFlatL2),且来自或发往 GPU 内存的副本可以被自动地处理。
构建
该库基本上是通过 C++ 实现的,带有可选的通过 CUDA 的 GPU 支持和一个可选的 Python 接口。它使用了一个 Makefile 进行编译。参见 INSTALL 了解详情:https://github.com/facebookresearch/faiss/blob/master/INSTALL
Faiss 的工作方式
Faiss 是围绕一种存储了一个向量集的索引类型(index type)而构建的,并且提供了一个使用 L2 和/或点积向量比较在其中进行搜索的函数。一些索引类型是简单的基线,比如精准搜索。大部分可用的索引结构都对应了与以下方面的权衡:
搜索时间
搜索质量
每个索引向量所用的内存
训练时间
无监督学习时对外部数据的需求
Faiss 的完整文档
以下链接可访问文档:
完整文档(包括一个教程)请参阅这个 wiki 页面:http://github.com/facebookresearch/faiss/wiki
doxygen 文档给出了每个类的信息:http://rawgithub.com/facebookresearch/faiss/master/docs/html/annotated.html
要重现这篇研究论文的结果,请参考基准 README:https://github.com/facebookresearch/faiss/blob/master/benchs/README.md
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








