大数据文摘作品,转载要求见文末
作者 | THINKMARIYA
编译 |
张礼俊,曹翔
人工智能空前火热。许多公司已经用IBM Watson系统取代了工人;人工智能算法甚至能比医生更准确地诊断病人。新的人工智能创业公司如雨后春笋,宣称可以使用机器学习来解决你所有个人问题和商业问题。
许多平时看似普通的物品,像是果汁机、Wi-Fi路由器,做广告时都说自己由人工智能驱动。又比如智慧书桌,不仅能记住你不同时段所需要的高度设置,还能帮你叫外卖。
许多喧嚣人工智能的报道其实是由那些从没亲手训练实现过一个神经网络的记者,或是那些还没解决任何实际商业问题却想招募天才工程师的初创公司写的。怪不得大众会对人工智能能做什么不能做什么有那么多误解。
神经网络早在六十年代就被发明,但最近大数据和计算能力的提升才使它在实际应用中取得效果。已经出现了一个名为“深度学习”的新学科,它可以应用复杂的神经网络架构,比以前更准确地对数据模型进行建模。
深度学习成果斐然。如今,深度学习可以识别图像和视频中的物体,可以将语音转化成文字,甚至比人做得更好。谷歌将谷歌翻译的结构替换成了神经网络,现在机器翻译的表现已经非常接近人类。
深度学习的实际应用同样让人兴奋。计算机可以比政府农业机构更准确地预测农作物产量;在诊断癌症上,甚至比最优秀的医师更加准确。
美国国防部高等研究计划署的主管John Launchbury描述了人工智能的三个浪潮:
1.人工选择的知识表达,或者像是IBM深蓝、沃森这样的专家系统。
2.统计学习,包括机器学习和深度学习。
3.内容适应,涉及到用稀疏数据给现实世界的现象构建可靠可解释的模型,像人类一样。
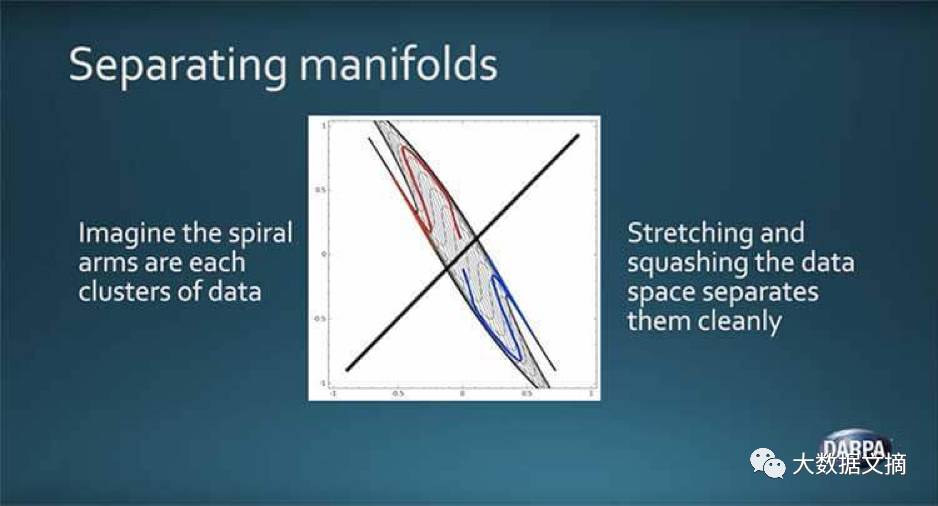
作为人工智能第二波的一部分, 深度学习算法效果很好,这是因为Launchbury所说的流形假设。简单来说,这是指出了在较低维度下可视化时,不同类型的高维自然数据如何趋于聚集和变形。

通过数学操作和分离数据块,深度学习能够区分不同的数据类型。虽然神经网络可以取得精确的分类及预测能力,这些本质上源于Launchbur
y所说的“增强版的电子表格”。
最近湾区人工智能创业者会议上,Francois Cholle强调说深度学习仅仅只是比之前的统计和机器学习方法更强大的模式识别方法。 Cholle是谷歌人工智能研究员,也是发明了深度学习Keras的著名开发者。他认为人工智能最关键的问题是抽象和推理。现如今的监督学习和强化学习需要太多数据,无法像人一样做推理规划,只是在做简单的模式识别。
相反,人类可以从非常少数的例子中学习,可以安排长期的计划,并且能够形成一种情形的抽象模型,并将这些模型用到更多不同的情况之中。
即便让深度学习算法学会非常简单的人类行为也是一件费劲的事! 想想看当你走在路上想要躲开撞向你的车时,如果你想通过监督学习决定下一步要怎么做,你需要大量标记了车辆情景和应该采取的行动的数据,像是“停止”或者“移动”。然后你要训练一个神经网络去学习情景和应该采取的行动之间的映射。
如果用强化学习的方式,给你的算法一个目标,然后让它自行决定最佳的行动是什么,在计算机学会不同道路情况下躲开汽车之前,可能早已经被车撞死几千次了
Chollet提醒人们不可能仅仅通过加强当今的深度学习算法来取得通用智能。
人类只要别人说一次就知道要避开车。我们有能力从少数例子来泛化我们学到的知识,并且可以想象从被车撞到后会有多糟糕。我们大多数人很快就能学会毫发无损的躲开汽车。
当神经网络在大规模数据上取得统计意义明显的成果时,个体数据上却是不可靠的,并且常常会犯人们不会犯的错误,比如把牙刷预测成棒球棍。

你的结果只会和你的数据一样好。给神经网络不准确或者不完整的数据只会得到错误的结果。这些结论既很尴尬,还很危险!两次公关危机中,谷歌错误得把黑人识别成大猩猩,微软的系统仅仅用推特的数据训练几小时后就学会种族歧视,女性歧视的言论了。
我们的输入数据中潜藏着不希望的偏差。谷歌庞大的词向量系统建立在谷歌新闻的三百万条新闻之上。数据集会自己做出像父亲是医生母亲是护士的联系,反映了我们语言中的性别偏见。波士顿大学的研究人员Tolga Bolukbasi借助了亚马逊Mechanical Turk众筹平台,利用人们的评分来尝试去除这些偏见的联系。
Bolukbasi认为这个思路是至关重要的,因为词向量不仅会反映成见,还会放大成见。如果医生更多的和男性联系在一起,那么算法会优先将男性工作申请者匹配到医师的职位上去。
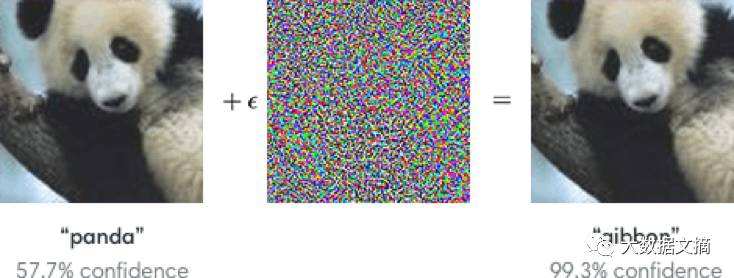
最后,生成式对抗性网络的发明人Ian Goodfellow展示了神经网络会被反例给欺骗。给图像做一些人眼看不出来的操作之后,复杂的攻击者欺骗了神经网络使其无法正确识别出物体。
我们如何克服深度学习的局限性并通向通用智能呢?Chollet最早的计划是从数学证明领域开始使用超越人类的模式识别,比如深度学习来帮助增强搜索和形式系统。
自动定理证明器通常暴力搜索每一种可能的情形,实际应用中很快就会遇到组合爆炸的问题(搜索时间指数性上涨)。在深度数学项目中,Chollet和他的同事使用深度学习来协助定理搜索的过程,模拟数学家关于哪些引理会是有用的直觉。
另一种方式是开发更易于解释的模型。手写识别中,神经网络通常要有成千上万的数据才能达到还不错的分类结果。相比着眼于像素,Launchbury认为生成式模型可以学会任意一个文字的笔划,然后用这些笔划信息来区分相似的数字,比如9和4。
卷积神经网络的创始人兼脸书人工智能研究总监Yann LeCun提出了一种基于能量的模型来克服深度学习中的局限性。通常而言,我们只会训练神经网络产生一个输出,像是一个图像的标签或者一句话的翻译。LeCun的基于能量的模型则给出了所有可能输出的集合,比如说一句话所有可能的翻译方式,以及每种翻译方式对应的评分。
深度学习之父Geoffrey Hinton想用块状结构 来取代神经网络中的神经元结果。他相信这样能更准确地反映人类大脑的生理学模型。生物进化必然已经发现了一种能高效地在初级神经感知回路进行特征调整的方式,这些调整会对后续神经回路特征表达非常有用。Hinton希望块状的神经网络结构能够更有效的应对之前Goodfellow提出的对抗训练。
也许所有这些克服深度学习局限性的方法都有自己的价值,也许都没有。只有时间和人工智能领域的持续投入才能告诉我们答案。

扫码
报名
Strata Data Conference大会
大数据文摘
专享优惠截至5月5日
来源:https://venturebeat.com/2017/04/02/understanding-the-limits-of-deep-learning/










