Modular structure of human olfactory
receptor codes reflects the bases of odor perception
Ji Hyun Bak
1
,
Seogjoo J. Jang
2,3
, Changbong Hyeon
1
1
Korea Institute for Advanced Study
,
Seoul 02455,
Korea
2
Department of Chemistry
and Biochemistry, Queens College, City University of New York, New York
11367,USA
3
PhD programs in
Chemistry and Physics, and Initiative for Theoretical Sciences, Graduate
Center, City University of New York, New York 10016,USA
doi: https://doi.org/10.1101/525287
嗅觉信号的回路让人联想到复杂的计算设备。
嗅觉受体代码是嗅觉感知神经计算的有效输入代码,它代表了嗅觉刺激引起的受体反应
。在这里,我们分析了人类嗅觉受体
(ORs)
的气味依赖反应的最新数据集,我们发现人类嗅觉受体代码的空间被划分为一个模块结构,其中受体组被“标记”为关键的嗅觉特征。我们的分析
揭示了人类气味感知空间的低维结构,以受体群为基础代表感知气味空间的主要特征
。这些发现提供了一个新的证据,表明一些基本的嗅觉特征已经在
ORs
水平上硬编码,与更高水平的神经回路分开。
嗅觉是一种通过一系列嗅觉受体
(ORs)
检测分子刺激来捕捉环境信号的感觉过程
。虽然嗅觉信息的完整处理是在复杂的神经回路中实现的[1],但嗅觉感知的第一步涉及到气味物质与同源
ORs
的选择性结合,这在本质上是生化的[2]。这种结合在相应的嗅觉受体神经元
(olfactory receptor neurons, ORN)
中引发一系列下游反应[3]。被编码到
ORs
或
ORN
中的反应模式被称为
嗅觉受体代码
[4],它提供了气味的第一个神经表征,在嗅觉感知的早期阶段至关重要。
受体代码位于嗅觉信息流的关键节点,是分子空间和神经空间之间的桥梁
。分子空间中的嗅觉刺激,代表气味物质的物理化学性质,被翻译成受体代码空间,形成“输入代码”。然后,
这些信息通过高阶神经空间进行处理,最终唤起构成感知气味空间的嗅觉
(见图1)。最近对嗅觉信息处理的见解主要是基于非人类物种的嗅觉感知[5-7]或通过理论研究[8,9]获得的。一个独立的研究分支试图将分子空间与感知气味空间直接联系起来[10,11]。然而,
了解人类嗅觉计算原理的目标面临着一个根本的困难,因为我们对人脑神经回路的访问有限
。
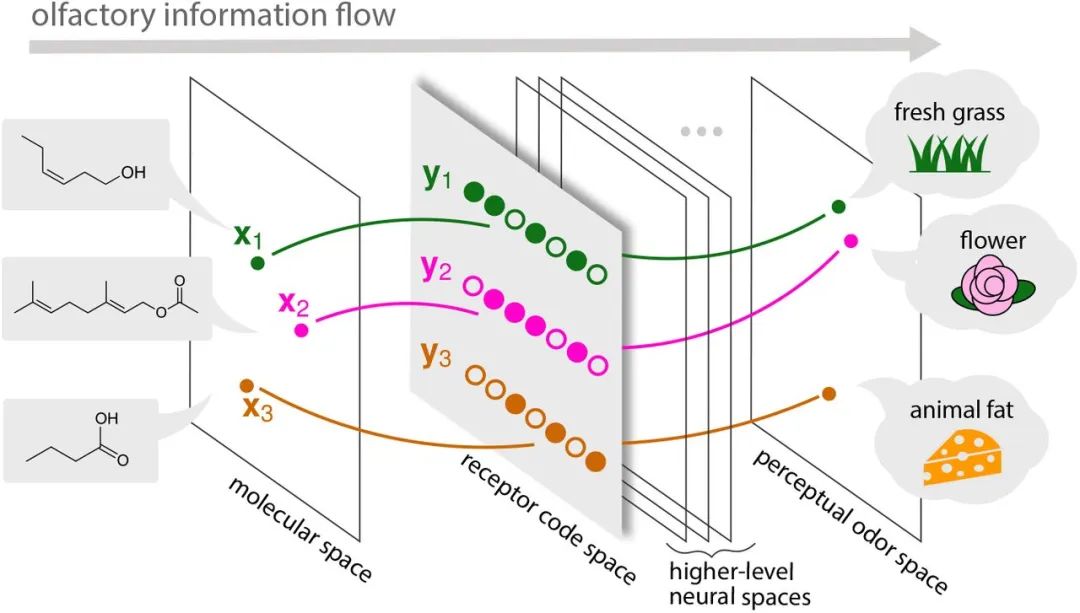
图1 嗅觉信息流示意图。
分子空间代表气味分子的物理化学特征,首先被OR库识别并编码到受体代码空间中。存储在受体编码中的信息经过高级神经空间的修改,最终投射到感知气味空间,被感知为气味。
在这里,我们表明,一个关键的进展仍然可以通过受体代码空间的系统分析。虽然已知
OR
曲目编码来自气味的输入信号,就像钢琴键盘组合产生各种音乐和弦一样[4],但可以进一步“格式化”以促进相关信息的处理,也许可以适当地反映感知气味空间的结构。具体来说,我们分析了一组不同气味的受体代码,这些代码是从人类嗅觉下游反应的生化测量中提取的[12-14]。由于受体代码是由气味剂和
ORs
之间的多对多成对相互作用实现的[4,15],我们将每个气味-受体对的相互作用视为“开”(响应)或“关”(不响应),并分析成对相互作用的二进制模式,将其视为受体代码的零阶表示。
我们对不同受体代码之间的重叠(受体代码冗余)的分析揭示了人类受体代码空间的内在结构,这也与感知气味空间中的粗粒度特征集有关
。这表明嗅觉信息的处理已经在受体空间中起作用了。
结果
我们对气味与受体相互作用的模式进行了定量分析,采用了一个数据集,报告了303种受体对89种气味的反应[14]。所有N = 303个受体的状态可以用N维二进制向量y表示,其中,如果第i个受体处于“开”状态,
y
i
= 1,如果处于“关”状态,
y
i
= 0。对于给定的气味x,对应的受体代码y表示n维二进制受体代码空间中的气味x。
我们收集了数据集中报告的所有535个成对相互作用,包括60个失活[16],并以相互作用网络的形式将受体代码可视化(图2a)。在这个相互作用网络中,每个节点要么是一个气味剂,要么是一个受体,每个边缘连接一个相互作用的气味-受体对。更详细的变参数交互网络如图S1所示。
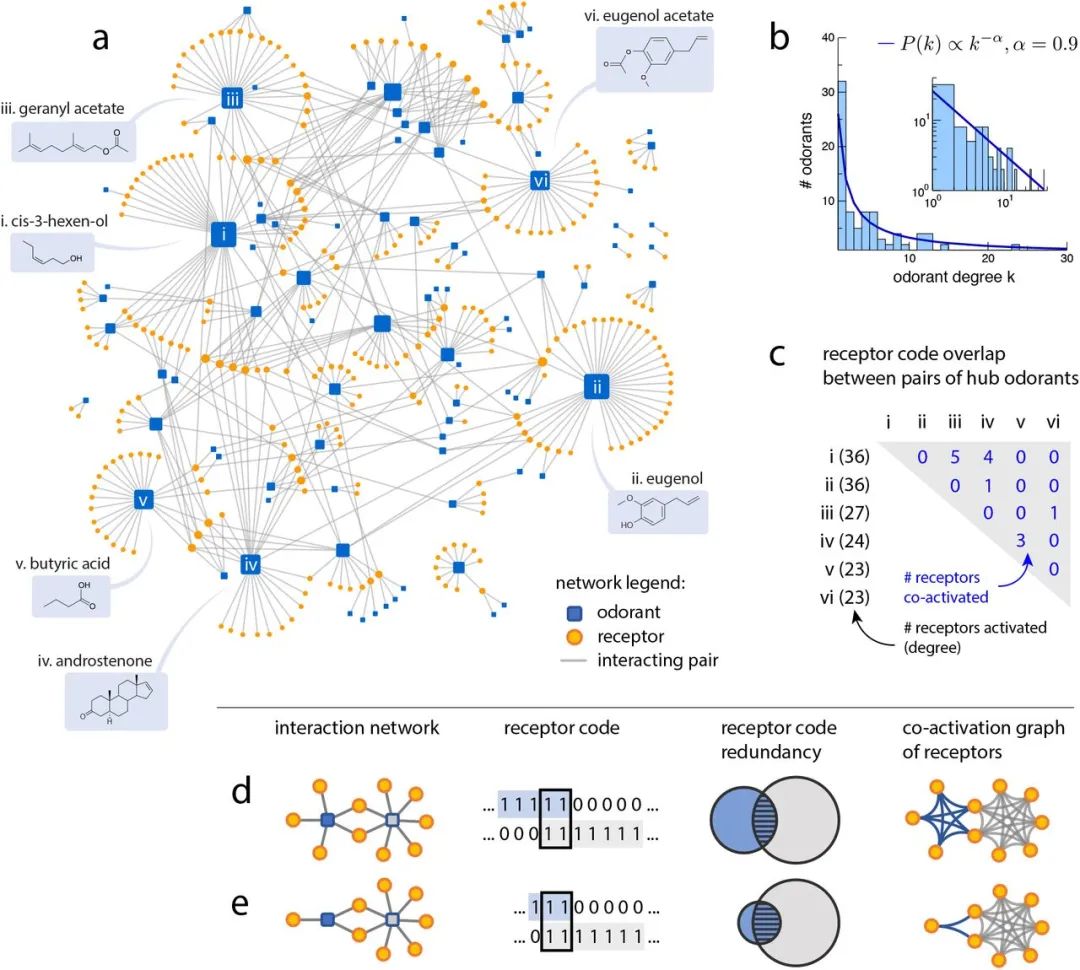
气味受体相互作用网络和受体代码。
(a)气味-受体相互作用网络,将数据集中89种气味剂(蓝色方块)和303种受体(橙色圆圈)之间的所有相互作用可视化[14]。当气味和感受器相互作用时,就会画出一条边缘。节点大小反映程度;六种最高程度的气味被标记出来。也请参见图S1,显示所有气味标签的扩展显示,以及成对交互属性的边缘属性。(b)气味度直方图。从对数P(k)vs的线性回归中,度分布拟合为
P
(
k
) ~
k
−
α
, α = 0.9 (
R
2
= 0.74)。log k),其平均值< k >≃6(也见图S2)。(c) a中识别的六种中心气味的受体代码之间的重叠(也见图S3)。(d-e)受体代码冗余思想的说明。前两列显示了受体代码空间的两个等效表示,作为一个交互网络和一组二进制向量。我们考虑目标气味(蓝色)相对于背景气味(灰色)的受体代码冗余。在第三列中,受体代码冗余用相互作用受体的维恩图说明。在背景气味存在的情况下,添加目标气味的冗余度表示为重叠的相对大小(条纹区域)相对于目标信号的总大小(蓝色阴影区域)。尽管在这两种情况下重叠受体的数量是相同的,但d中的规范化冗余(五分之二)比e中的规范化冗余(三分之二)要小。在最后一列中,相互作用网络被投射到受体的共激活图上。
相互作用网络揭示了具有非冗余受体代码的气味中枢
在气味-或相互作用网络中(图2a),附着在气味节点上的边的数量表明识别这种气味的受体的数量
。我们称这个数字为
气味节点的程度
,并用
k
λ
表示它,其中λ是气味的索引(参见方法)。
我们从气味度的统计中观察到两个特性。首先,单个气味物的受体空间表示是稀疏的:平均而言,在N = 303个受体中,只有6个
(〈
k
〉) ≃ 6)
或6个(占受体空间的2%)可以识别气味物。网络中观察到的稀疏性与之前的ORN响应报告一致[17,18]。其次,数据集中气味剂的度是非均匀分布的,有一个重尾,可以近似地拟合到
P
(
k
) ~
k
−
α
,α≈0.9(图2b)。这种分布使我们能够识别少量高度气味的“集线器”。六种最高度数的中心气味剂在图2a中标注。值得注意的是,中枢气味剂的受体代码彼此之间高度不冗余(图2c);在6种最高程度的气味中,所有15对中有10对具有完全不相交的受体编码。特别是,
尽管化学结构非常相似,但丁香酚和丁香酚乙酸酯之间没有共激活的OR,它们在单个官能团(芳香环中的羟基与乙酸)上不同
。中枢气味剂中受体代码的重叠明显小于受体代码覆盖相同数量的气味剂的随机混合所期望的(p < 0.02;参见方法和图S3)。
我们引入了受体代码冗余的概念,这是
两种不同气味的嗅觉反应之间(非)相似性的定量测量
。如果两种气味有完全相同的受体编码,它们就会被认为是相同的嗅觉信号。我们假设,当两种气味的受体代码具有较高的冗余度时,它们很难区分。例如,考虑一个歧视性任务,其目标是在恒定的背景气味存在下检测目标气味[19,20]。
当没有背景气味时,信号会引起
|
y
targ
|
受体的反应,其中
y
targ
是目标气味的受体代码
。但当一些受体也对背景
y
bg
有反应时,重叠受体的状态不会随着目标气味的加入而改变;受体代码重叠
|
y
targ
∩
y
bg
|
减少了响应的有效大小(参见图2d-e)。因此,我们根据分数
χ = |
y
targ
∩
y
bg
| / |
y
targ
|
来定义受体代码冗余。如果这个分数很小,如图2d所示,即使在背景气味存在的情况下,目标气味也被认为是明确检测到的。
综上所述,
单一气味在受体空间中的表现是稀疏和不均匀的,从而产生了高度的“中心”气味
。在这些中心气味剂中,受体代码几乎没有冗余,而在中心气味剂中具有更大受体代码冗余的气味剂则围绕其分组。如下所示,对受体代码冗余的分析使我们能够更定量地破译受体代码空间的结构。
受体代码空间自然分区,呈现模块化结构
当相互作用网络投射到受体空间时,组结构得到更好的体现。这里我们考虑受体的共激活图,它继承了
原始相互作用网络中的所有受体节点
;
如果两个受体节点在原始网络中具有相同的气味
,
则它们之间通过一条边连接
(图2d-e,最后一列)。在共激活图中特别有趣的是“
受体区块
”,或被相同气味共同激活的受体组。因为每一对与共享气味剂λ相互作用的受体在受体的共激活图中是相连的,所以所有与给定气味剂相互作用的受体总是形成一个集团。
考虑到相互作用网络的特殊结构,中枢气味剂具有大部分非冗余受体代码(图3a),受体的共激活图必然具有与中枢气味剂相关的大型且大多数不重叠的区块(图3b)
。我们使用受体区块将受体空间划分为不重叠的组,这样每个受体组都与共享的气味相关联;
当一个受体是多个受体区块的一部分时,它被分配到较大的区块
(图3c)。

受体代码划分的原理图
。(a)给定具有中心气味剂特定统计的相互作用网络,(b)在受体的共激活模式中更清楚地揭示了模块化结构。(c)我们从气味中心周围的受体群中表征局部结构,(d)合并局部组以获得受体代码的最佳划分。更详细的说明请参见图S4。
受体组可以根据它们的受体代码来对气味进行分组
。这个想法是构建气味组,这样一个气味λ属于一个气味组Λ,如果它的受体代码冗余相对于组Λ,
χ
λ|Λ
= |
y
λ
∩
y
Λ
| / |
y
λ
|
,是大的(见方法)。首先,我们使用受体组来确定气味组的参考受体代码(
y
Λ
’s
)。具体来说,对于每个受体组Λ(请注意,组索引在受体和气味剂之间共享),我们制作一个二元向量
y
Λ
,使得[
y
Λ
]i = 1当且仅当受体i属于组Λ。然后我们将每个气味分配到受体代码冗余
χ
λ|Λ
最大化的组Λ。
这导致气味剂和受体的同时分配(图3d,局部组)
。
局部区块自然地从具有中心气味的受体编码的特定统计中出现,并捕获局部共激活模式;如果受体被同一种气味共同激活,它们就会被归类在一起。
然而,如果我们要根据组来描述受体编码空间的整体结构,那么没有分组在一起的对也携带着重要的信息。在我们的例子中,如果同一组中的受体对同一组气味有反应,而不同组中的受体对不同的气味有反应,那么一组就是“好”的。
现在我们进一步根据共激活模式获得受体代码空间的最佳分组:我们通过识别受体团合并上述获得的初级组来进行受体的二级分组
。当它们在共激活矩阵中的重叠大于阈值时,我们合并一对主组(详见方法),其中确定合并阈值以最大化分组的优度(图S5)。由于我们同时划分了气味剂和受体,因此受体组的合并会自动导致相应气味组的合并(图3d)。
将分组程序应用于人类嗅觉受体代码,得到图4中排序的交互矩阵,其中每一行代表给定气味的受体代码。
相互作用矩阵的行和列按照各自气味/受体组的顺序排序
(图4a-b)。相互作用矩阵具有大致的块对角线形式(图4c),非对角线元素的贡献要小得多。请注意,我们已经安排了交互网络布局来表示分组结构,如图5所示,其中彩色区域(组1-6)代表了受体代码空间的最佳划分。
分组的可行性反映了受体编码的特殊结构;这种清晰的分组不是从具有相同统计度的随机网络中得到的
。具体来说,我们将相互作用矩阵随机化,同时保留(i)相互作用的数量,(ii)
每种气味(度)的相互作用数量和(iii)主要分组结构
。在这三种情况下,找到一个与我们从人类受体代码数据中观察到的一样好或更好的分组是极不可能的(p≤0.002;见方法和图S6)。
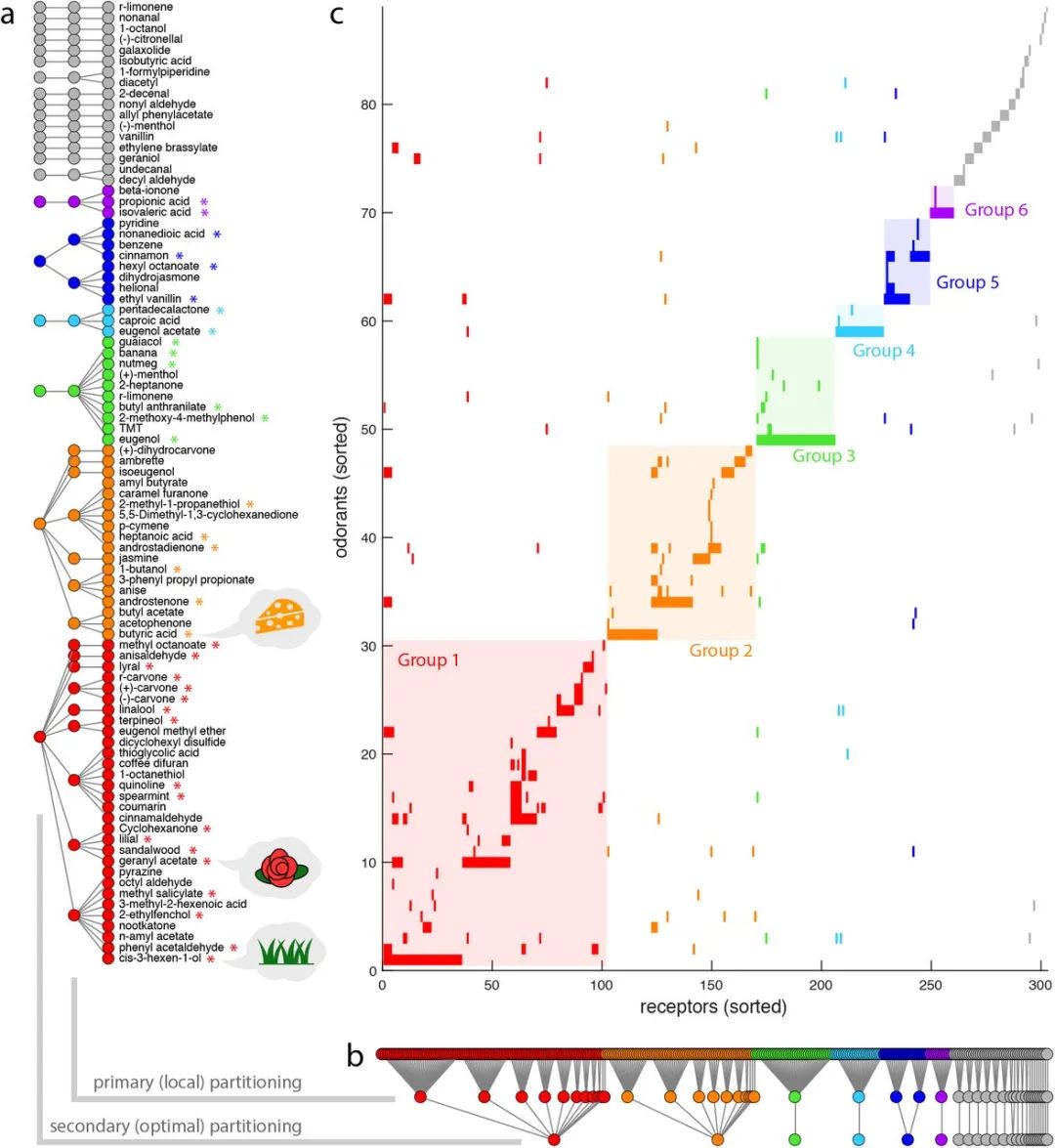
基于共激活模式和受体代码冗余的气味和受体的同时分配。(a)气味剂和(b)受体的一级和二级基团显示,其中指数同时按基团等级排序。同样参见图s5和图s6进行验证。(c)因此,相互作用矩阵的行和列按气味和受体指数排序。每一行代表对应气味的受体代码。六个最大的次要组在所有面板上都有颜色。在相互作用矩阵中添加对角线块阴影,以便更好地可视化气味剂和受体的同时分配。在(a)中,气味品质与相应次级组的特征嗅觉特征一致的气味剂(第1组为植物状;第2组和第6组为类动物;适用于第3、4及5组的烹调)均以星号标示。参见表S1。

气味感受器网络中的区域。
六个最大的全球群体,按群体中受体的数量排列,以不同的颜色显示。子结构(局部组),如果有的话,也以浅色显示。
同一组的气味者往往具有相似的嗅觉特征
到目前为止,我们的分析只涉及测试气味的受体代码;我们没有使用任何关于气味剂的其他信息。另一方面,由于数据集的构建包含了先前心理学研究中考虑的气味[13,14],因此每个测试气味都具有已知的感知质量;也就是说,它对人类的气味。
事实证明,最大的受体编码组(第1组)中的两个中心气味代表了植物相关气味的两个亚类:
新割草的典型“绿色”气味
(
顺-3-己烯-1-醇
)和许多天然精油中遇到的
典型“花香”气味
(
乙酸香叶酯
)。此外,第1组中还有许多其他气味属于类似的感知类别,即
绿色
(
苯乙醛
,
檀香醇
,
松油醇
);
花
(
芳樟醇
,
丁香
,
铃兰醛
,
茴香醛
);还有
薄荷
(
水杨酸甲酯
、
绿薄荷
和
香芹酮
)。在第二组中,所有三种中心气味都与体味有关。汗液或唾液中含有
雄烯酮
和
雄二烯酮
(“人类信息素”);
丁酸
具有特有的汗味,是人体内通过发酵自然形成的,
牛奶和黄油中也含有丁酸
。在较小程度的气味剂中,
庚酸
带有
腐臭的汗味
,
2-甲基-1-丙硫醇
与
肉味或啤酒味有关
。在第3、4和5组中,我们发现了香辛料的成分。第3组和第4组的两种中心气味剂是
丁香油
的主要成分(
丁香酚
和
丁香酚醋酸酯
);第5组的两种中心气味剂是常见的
食品调味剂
(
乙基香兰素
和
肉桂
)。第3组包括更多与香料或食物相关的气味:
肉豆蔻
和
香蕉
有它们典型的味道,
愈创木酚
被认为能给
威士忌
和
烤咖啡
带来特有的味道,
2-庚酮
与
戈尔根佐拉奶酪
的典型气味有关。
这些观察导致了一个假设,尽管我们的分析仅基于受体代码及其冗余,但它导致了一组感知上相似的气味在一起。为了使这个想法更加量化,我们将每种气味标记为五类(
植物类
、
动物类
、
烹饪类
、
柑橘类
和
其他类
)中的粗粒度气味特征。更具体地说,我们首先使用从以前的工作[21]中确定的
八种感知气味类别
(主要气味类别)来标记气味剂,然后合并一些显示如下所述的类似共现模式的类别(次要气味类别);参见图S7c和表S1。请注意,在本文中,我们将使用术语“
嗅觉特征
”专门指
由一组离散类别标记的感知气味品质
。标记程序的细节在方法中描述。因此,每种气味都被分配了两个独立确定的标签:
一个用于受体编码组
(“
区块
”),
另一个用于感知气味类别
(
嗅觉“特征”
)。与受体代码组类似,在本分析中,我们将考虑
提供感知气味空间更简洁表示的次级气味类别
。
我们在89种测试气味剂中抽样了受体编码组和嗅觉特征的联合分布,其中每种气味剂按其程度加权,以便考虑其对受体空间的影响(见方法)
。
如果在联合分布中观察到两个标签对的频率高于从单个标签的边缘分布中预期的频率,我们可以说,在给定的群体中,一种嗅觉特征是丰富的。特别是,
我们
用加权对数似然比
(图6a)对它们的联合富集进行了量化,其总和给出了两个标签之间的互信息(见方法)。我们发现,
在第1组中植物类气味丰富,在第2组和第6组中有动物类气味,在第3、4和5组中有烹饪(与食物相关)气味,支持上述假设
。我们还发现柑橘富含所有小类群的联合,类群大小排序指数在7及以上。我们采用G检验和卡方检验来评估该说法的统计学显著性,两种方法的p < 0.001(对于24个自由度,
G
= 57.5,
χ
2
= 62.2;详情请参阅方法)。
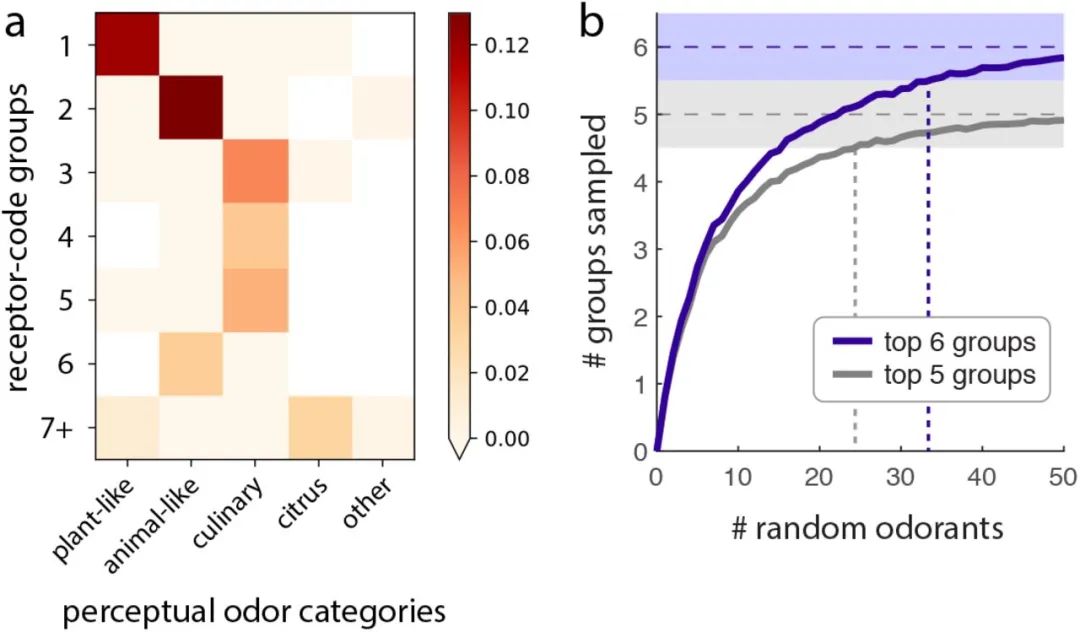
链接到感知气味类别。(a)受体编码组和感知气味标签之间的联合富集,以加权对数似然比衡量。也见图S7。(b)随着气味剂数量的变化,6个主要群体中随机混合气味剂覆盖的平均数量(紫色)。在m≤33时,群落盖度接近于6,而不是5。结果基于每m 500个独立采样,标准误差小于线宽。如果我们考虑多达五组,则截止值为m > 25(灰色)。
气味空间中的群体解释了“嗅觉白”
最后,我们表明我们的结果可以与报道的“嗅觉白”现象联系在一起[22],在这种现象中,
如果在气味空间中随机混合超过30-40种气味,人类受试者就无法区分气味混合物
。然而,“
跨越气味空间
”的想法仍然停留在与低维度感官模式(如色觉或音调听觉)的定性类比的水平上。在这项研究中,
我们发现嗅觉空间可以在受体编码和感知特征的水平上被理解为少数(六)组
。现在我们更定量地探索嗅觉白色的概念,通过询问气味空间,根据受体代码确定的六个主要组划分,何时完全被气味混合物覆盖。
我们从我们的测试数据集中随机抽取m种气味剂,并计算采样集中至少有一种气味剂的主要组的数量(从六个组中)。在改变混合物大小m的同时重复采样,我们检查混合物覆盖的平均组数(图6b)。结果表明,随机抽样m
~
33种气味剂足以对6个主要群体中的每一个群体进行至少一次抽样,因为平均群体覆盖率> 5.5。另一方面,由m
~
34种随机气味剂组成的混合物的平均受体覆盖率(在混合物中至少识别一种气味的受体数量)相当于6种中心气味剂的覆盖率(图S3b)。因此,我们可以说,
30-40种气味的随机混合相当于气味空间的完全跨越(最多六个主要群体),就群体覆盖范围(跨越的碱基数量)以及受体覆盖范围而言
。
我们对人类嗅觉空间的表征,就受体编码组而言,提供了构建感知趋同气味混合物(“嗅觉白”)所需的随机气味剂数量的定量说明
。
讨论
通过识别嗅觉受体(ORs)的相关反应模式,我们发现了受体代码的自然划分
。同样的程序也可以识别具有相似受体代码的气味组。虽然分组时除了受体代码外没有任何外部标签,但我们发现
同一组中的气味者倾向于携带相似的嗅觉特征,这表明在受体代码空间中存在“标记组”
。下面我们将详细阐述这一观点,并从人类气味感知的更广泛角度讨论其含义。
受体群作为感知气味空间的基础










