
编者按:深度学习顶级盛会 ICLR2017 最佳论文评选结果于近日新鲜出炉,其中一篇引争议;百度发布了 2016 年 Q4 财报,研发成本高达 101.5 亿人民币;Alexa 智能语音助手平台已经拥有超过 10000 项 “技能”(Skill);《MIT 科技评论》2017 十大突破技术榜单,AI 领域 3 家中国公司入选;百度引入 Ring Allreduce 算法,大规模提升模型训练速度;IBM 沃森或面临与世界顶级癌症研究机构解约。这里是本周 AI 圈大事件。
ICLR2017 最佳论文出炉引争议
受到万众瞩目的 2017 年 ICLR 即将于今年四月在法国召开。该大会是 Yann LeCun 、 Yoshua Bengio 等几位行业顶级专家于 2013 年发起,如今已成为深度学习领域一个至关重要的学术盛事。今年 4 月,雷锋网也会亲临 ICLR2017 大会,为大家从法国带来最新鲜的一手资料。
ICLR 论文评选结果于近日新鲜出炉。经过列为评委的火眼金睛,在 507 份论文中共有 15 篇论文成功进入口头展示阶段,181 篇进入海报展示阶段。
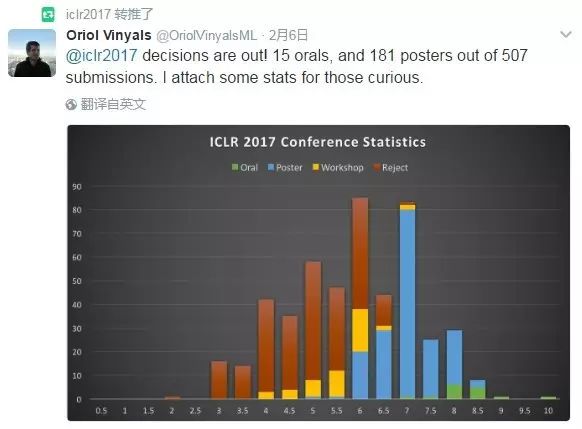
除了这些被选入 ICLR 2017 的论文,还有三篇论文成功当选为 ICLR 2017 最佳论文,分别是:
《用半监督知识迁移解决深度学习中训练隐私数据的问题》(Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data)
《通过递归实现神经编程架构通用化》(Making Neural Programming Architectures Generalize via Recursion)
《泛化——一个理解深度学习需要重新思考的问题》(Understanding deep learning requires rethinking generalization)
其中,三篇优秀论文中争议最大的莫过于这篇名为《Understanding Deep Learning Requires Rethinking Generalization》(《理解深度学习,需要重新思考泛化问题》)的论文。
这篇论文以 “重新思考泛化问题” 为主题,通过系统试验,展示传统方法无法解释大规模神经网络在实践中的泛化表现好的原因。而在实验中,研究者证明了用随机梯度训练、用于图像分类的 CNN 很容易拟合随机标签数据,而且本质上并不受显式正则化的影响。
这篇论文作者为 Chiyuan Zhang(MIT 博士生,师从 Tomaso Poggio)、Samy Bengio(谷歌大脑团队,深度学习三巨头 Yoshua Bengio 的亲兄弟)、Modiz Hardt(谷歌大脑团队)、Benjamin Racht(加州伯克利大学),Oriol Vinyals(谷歌 DeepMind)。从标题到阵容,不得不承认是非常豪华的。不过,观点在 OpenReview 上呈现两极分化,以纽约大学博士生张翔为代表的研究者认为此文被高估。从张翔的角度来看,他认为这篇论文归根结底可以总结为:在跟输入无关的随机标签下,模型的泛化能力很差。
“学术会议的论文评审是一个学界内部的民主过程,其结果需要大家都接受。但是不论什么论文都是可以有不同意见的。” 在谈论起论文的评审模式时,张翔向雷锋网如是说,他也希望能通过表达自己的不同意见,引起大家的讨论。
百度 Q4 财报发布,2 年 200 亿的研发费用都去哪儿了?

2 月 24 日,百度发布了 2016 年第四季度财报兼 2016 年全年财报,财报显示,2016 年全年营收 705.49 亿人民币,较 2015 年增长 6.3%。而雷锋网发现,在百度的财报里,其研发支出这一项就投入了 101.5 亿人民币。这一巨大的研发投入,与百度反复提到的 “人工智能” 词汇有莫大关系。
雷锋网翻看百度前几年的财报发现,从 2014 年开始,百度的研发成本开始猛增。
2014 年,研发费用为 69.81 亿人民币,比 2013 年增长了 70%
2015 年,研发投入突升为 101.76 亿人民币,比 2014 年又增长 45.8%
2016 年,研发费用为 101.5 亿人民币,比 2015 年减少 0.2%
针对这两年研发投入的疯狂增长,官方给出的理由也很直接:
“这部分增长主要是由于研发人员数量增加”。
我们发现,研发投入猛增是从 2014 年开始的,而 2014 年百度最重要的事件就是加大三大研发中心的人才引进力度,包括深度学习研究院(IDL)、硅谷 AI 实验室(SVAIL)和大数据实验室(BDL)。
所以,百度每年 100 多亿的研发投入,主要都花在了筹建和维护人才库上。2015 和 2016 两年,百度研发投入在 100 亿人民币左右浮动,说明到 2015 年底的时候,百度的研发团队招募工作已经基本完成,以百度的财力和体量,构造一套完整的 AI 人才库花费了 2 年时间。
Alexa 已经疯狂扩张到 10000 项技能
亚马逊周四宣布,旗下的 Alexa 智能语音助手平台已经拥有超过 10000 项 “技能”(Skill)。去年 1 月,这个数字还只有 130,到 11 月也才刚刚突破 5000,因此这个增速相当惊人。

根据 VoiceLab 的报告,目前最受欢迎的技能种类主要是新闻、游戏、教育、生活方式等几大类别。问题是,目前 Alexa 平台已经拥有超过 10000 项技能,除了排在榜单前列的技能之外,其他技能真的有人在使用吗?
实际上,在亚马逊 Alexa Skills 商店里,大部分的技能都没有任何评价,而且实用性存疑。根据 CIRP 的报告,截至 2017 年 1 月,亚马逊 Echo 系列(包括 Echo、EchoDot 和 Tap)用户已达到 820 万。随着 Echo 的使用者越来愈多,Alexa 平台越来越壮大,很难不让人把它与早期的 App Store 相比较。其实早期 App Store 的畅销榜单上也充斥着各种低质量、或者没有任何实际作用的应用,比如数不清的模拟放屁声音的恶作剧应用。
《MIT 科技评论》2017 十大突破技术榜单,AI 领域 3 家中国公司入选

2 月 21 日,美国权威杂志《MIT 科技评论》(MIT Technology Review) 公布了 2017 年度全球十大突破技术,有多家中国公司入选榜单(key players)。
“十大突破技术”(10 Breakthrough Technologies)是《MIT 科技评论》的年度技术评选榜单。自 2002 年起,《麻省理工科技评论》每年遴选并公布 10 项即将对人们工作生活产生深远影响的重大技术,这十大技术有一个基本的标准,那就是 “该项技术已经达到一个里程碑式的阶段或即将到达这一阶段”,所以我们在看到这十大技术的相关报告里,都会给出一个 “成熟期”(Availability),来说明这项技术离成熟应用于实际生活还要花费多长时间。
与 2016 年的十大突破相比,今年人工智能相关技术明显增多,有强化学习、自动驾驶货车和刷脸支付这三大项。这三大项上榜的公司分别是(英文版和中文版榜单略有不同,此文参考官网发布的英文版):
强化学习技术: DeepMind、Mobieye、OpenAI、Google 和 Uber(成熟期:1-2 年)
自动驾驶货车技术:Otto、沃尔沃、戴姆勒和 Peterbilt(成熟期:5-10 年)
刷脸支付技术:Face++、百度和阿里巴巴(成熟期:现在)
尤其值得一提的是,在刷脸支付这项技术里,中国公司被重点报道,而且中国公司占有决定性的领导地位,入选榜单的三家公司均为中国公司,分别是:Face++、百度和阿里巴巴。
三星计划投入 10 亿美元收购 AI 公司
近日,消息人士称三星正寻求收购人工智能公司,并将投入 10 亿美元的巨额预算,成立一支投资并购人工智能科技公司的专项资金。
近些年,三星的一系列动作均可看出其人工智能战略:据统计,三星近些年共收购、投资了十几家 AI 公司。三星在去年年底收购的汽车零部件供应商哈曼国际手中手上就持有多个 AI 项目,如智能城市、语音控制等。除此之外,三星还完成对虚拟助理 Viv 的收购。
与此同时,三星高层曾公开表达过对 AI 技术的强烈兴趣,三星软件研发部门主管去年称:他们认为 AI 不再是一个选择,而是一个必须品。
百度引入 Ring Allreduce 算法,大规模提升模型训练速度
美国西部时间 2 月 21 日,百度硅谷人工智能实验室(SVAIL)宣布将 Ring Allreduce 算法引进深度学习领域,这让基于 GPU 训练的神经网络模型的训练速度显著提高。

Ring Allreduce 是高性能计算(HPC)领域内一个众所周知的算法,但在深度学习领域内的应用相对较少。
深度学习在多个 GPU 上训练神经网络通常比较困难,因为大家普遍采用的方法是,让多个 GPU 把数据发送给一个 reducer GPU 上,这会造成一种通信瓶颈,整个训练速度会因此拖慢。而且要训练的数据越多,则带宽瓶颈问题就显得越严重。
而 ring allreduce 算法移除了这种瓶颈,减少 GPU 发送数据花费的时间,而把时间更多用在处理有用工作上。SVAIL 发布的博文中这样说道:
“ring allreduce 是这样一种算法——其通信成本是恒定的,与系统中的 GPU 的数量无关,并且仅由系统中的 GPU 之间的最慢连接来确定。事实上,如果在通信成本上你只考虑带宽这一因素(并忽略延迟),那么 ring allreduce 就是一个最佳的通信算法 。
算法的进行分两步:第一步,scatter-reduce;第二步,allgather。在第一步中,GPU 将交换数据,使得每个 GPU 最终都有一个最终结果的数据块。在第二步中,GPU 将交换那些块,使得所有 GPU 最终得到完整的最后结果。”
IBM 沃森或面临与世界顶级癌症研究机构解约
一向风光的 AI 界明星 IBM 沃森,近几日似乎有点烦。
2013 年 10 月,IBM 宣布德克萨斯大学癌症中心 MD Anderson 正在使用 IBM 沃森认知计算系统共同消灭癌症。即便在沃森陷入挫折时,MD Anderson 也力挺这位 “治癌新星”。
可惜好景不长,日前 MD Anderson 宣布该项目暂停,并证实从去年年底开始,癌症中心已积极要求其他供应商投标,在未来工作中取代 IBM 沃森。“这对 IBM 来说是一个不舒服的时刻”,Forbes 记者 Matthew Herper 如是说。
雷锋网了解到,解约的原因由德克萨斯大学的一位审计员给出,他在报告中指出,该项目超支 6200 万美元,但尚未达成目标。










