
1. 引言
正则表达式本身语法是一致,只是各编程语法对正则表达式的语法表现些区别。
本文主要是关于正则在 JavaScript 中的使用。若你对正则本身还不是很了解的话,强烈推荐先阅读我的上一篇正则文章——《Java 正则表达式详解》。
2. 创建正则表达式
在 JavaScript 中,我们有两种创建正则表达式的方式。
方式一,使用正则表达式字面量,它由两个斜杠包裹,如下所示:
var re = /ab+c/;
正则表达式字面量会在脚本加载后编译。当正则表达式是静态不变的,那么使用这种方式将会获得更好的性能。
方式二,调用 RegExp 对象的构造方法,如下所示:
var re = new RegExp('ab+c');
或:
var re = new RegExp(/ab+c/);
在使用构造方法时,正则表达式是在运行时编译的,适合正则表达式会动态改变的情况下使用。
3. 编写正则表达式
3.1 特殊字符
特殊字符 含义
\ 转义字符。反斜杠可以将后面跟着的第一个普通字符进行变成表示特殊含义的特殊字符。比如:/b/ 表示匹配一个小写字母 "b",但是 /\b/ 却不匹配任何字符,它变成了一个边界字符。反斜杠也可以将后面跟着的第一个特殊字符变成普通字符。比如: /a*/ 表示匹配 0 个或多个 "a",但是 /a\*/ 表示匹配 "a*"。
^ 表示匹配字符串的开头。 在多行模式下,表示匹配每行的开头。 ^ 如果出现在集合中的第一个字符,那么它的含义表示否定,比如:[^ab] 表示匹配不是 "a"或 "b" 的字符。
$ 表示匹配字符串的结束。 在多行模式下,表示 匹配每行的结束。
* 表示匹配前面的模式 0 次或多次,等同于 /{0,}/。
+ 表示匹配前面的模式 1 次或多次,等同于 /{1,}/。
? 表示匹配前面的模式 0 次或 1 次,等同于 {0,1}。 如果 ? 是限定符 * 或 + 或 ? 或 {} 后面的第一个字符,那么表示非贪婪模式(尽可能少的匹配字符),而不是默认的贪婪模式。 ? 也可使用在先行断言(lookahead)模式中。比如:此表格中的 x(?=y) 和 x(?!y)。
. 表示匹配一个除了换行符外的任意字符。
(x) 表示匹配分组 x,并保存匹配结果(反向引用(back references)),这组小括号被称为捕获括号(capturing parentheses)。比如:对于字符串 "good bad good bad" 的匹配模式 /(good) (bad) \1 \2/ 中,(good) 和 (bad) 分别匹配第一个和第二个单词同时生成对应组的反向引用,其中 \1 和 \2 分别匹配最后两个单词(但不生成反向引用)。对于 \1,\2,\n,是用来匹配正则表达式的一部分。在以正则表达式替换字符串的语法中,$1,$2,$n 分别表示组一的反向引用、组二的反向引用、组 n 的反向引用,其中 $& 表示匹配所有分组的字符(注意在 Java 中,是用 $0 表示)。比如:console.log('good bad good bad'.replace(/(good)\s(bad)/, '$1-$2')) 的结果为 "good-bad good bad"。
(?:x) 表示匹配分组 x 但不产生反向引用,这组小括号被称为非捕获括号,但可以使我们定义正则表达式的子表达式。比如:对于 /foo{1,2}/ 中的 {1,2} 表示匹配最后的字符 'o' 一次到两次。对于 (?:foo){1,2} 中的 {1,2} 表示匹配一组字符 "foo" 一次到两次。
x(?=y) 表示只匹配后面紧跟着分组 y 的字符 x ,这种模式称为先行断言(lookahead)。比如:Jack(?=Sprat|Frost) 表示只匹配后面跟着 "Sprat" 或 "Frost" 的 "Jack"。
x(?!y) 表示只匹配后面不是紧跟着分组 y 的字符 x,这模式称为否定先行断言(lookahead)。比如:/\d+(?!\.)/ 表示匹配没有小数点的数字。
x|y 表示匹配 x 或 y。
{n} 表示匹配前面的模式 n 次。
{n,m} 表示匹配前面的模式最少 n 次,最多 m 次。当不指定 m 时,相当于无空大。
[xyz] 字符集。表示匹配方括号中指定的任何一个字符,包括转义字符。其中特殊字符,如小数点 . 和星号 * 在字符集中不是特殊字符,因此不用转义。在方括号中,可以使用连字符 - 来指定字符范围。
[^xyz] 否定字符集。表示匹配不在方括号中指定的任何一个字符。可以使用 - 来指定字符范围。特殊字符的情况和 [xyz] 相同。
[\b] 表示匹配退隔符(backspace)。注意:不要和 \b 混淆。
\b 表示匹配字边界。字边界是指某个字符的前面和后面都没有其它单词字符(比如除了字符开始 或 字符结束 或 '.' 或 ',' 或 空格 等)。注意:匹配的字符边界不在匹配结果内,同时不要和 [\b] 混淆。比如:/\bm/ 匹配 'moon' 中的 'm'。
\B 表示匹配非字边界。
\d 表示匹配一个数字字符。相当于 [0-9]。
\D 表示匹配一个非数字字符。相当于 [^0-9]。
\s 表示匹配一个空格字符,包括 space, tab, form feed, line feed。相当于 [ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。
\S 表示匹配一个非空格字符。
\t 表示匹配一个 tab 字符。
\w 表示匹配一个数字或大小写字母或下划线。相当于 [A-Za-z0-9_]。
\W 表示匹配一个非数字或大小写字母或下划线的字符。相当于 [^A-Za-z0-9_]。
\n n 是一个正整数。一个反向引用(back reference),指向正则表达式中第 n 个括号(从左开始数)中匹配的子字符串。比如:正则表达式 apple(,)\sorange\1 匹配字符串 "apple, orange, cherry, peach." 中的字符 "apple, orange,"。
\uhhhh 表示匹配一个 unicode 编码(四个十六进制的数字)为 'hhhh'的字符。
4. 使用正则表达式
在 JavaScript 中,正则表达式是通过 RegExp 对象的 test和 exec 方法以及字符串 String 内置的 search,match,replace,split 方法使用的。
方法 描述
test RegExp 的一个根据正则验证字符串是否有存在匹配项的方法。匹配成功返回 true,反之返回 false。
exec RegExp 的一个根据正则检索字符串所有匹配项的方法,若有匹配的项则返回 array 数组对象,没有匹配项则返回 null。
search 字符串内置的一个根据正则验证字符串是否存在匹配项的方法。匹配成功返回匹配项的开始索引 index,反之返回 -1。
match 字符串内置的一个根据正则检索字符串所有匹配项的方法,若有匹配的项则返回 array 数组对象,没有匹配项则返回 null。
replace 字符串内置的一个根据正则替换字符串匹配项的方法。返回替换后的字符串。
split 字符串内置的一个根据正则或精确的字符切片字符的方法。返回字符串数组 array 对象。
当需要验证字符串是否存在某种模式的时候用 test 或 search 方法;当需要按某种模式截取字符串时用 exec 或 match 方法。
4.1 exec 和 match 的示例方法
下面的代码,使用了 exec 获取匹配的字符数组对象:
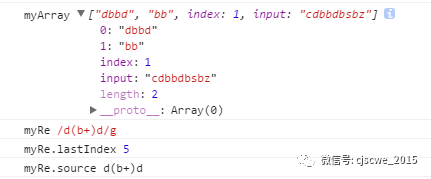
var myRe = /d(b+)d/g;
var myArray = myRe.exec('cdbbdbsbz');
console.log('myArray', myArray); // 结果数组
console.log('myRe', myRe); // 正则
console.log('myRe.lastIndex', myRe.lastIndex); // 下一个匹配开始时的索引
console.log('myRe.source', myRe.source); // 匹配模式文本
如果不需要访问正则表达式的属性,另一种写法为:
var myArray = /d(b+)d/g.exec('cdbbdbsbz');
console.log('myArray', myArray); // 结果数组
console.log('myRe', myRe); // 正则
console.log('myRe.lastIndex', myRe.lastIndex); // 下一个匹配开始时的索引
console.log('myRe.source', myRe.source); // 匹配模式文本
如果要通过构造方法创建正则,如下:
var myRe = new RegExp('d(b+)d', 'g');
var myArray = myRe.exec('cdbbdbsbz');
console.log('myArray', myArray); // 结果数组
console.log('myRe', myRe); // 正则
console.log('myRe.lastIndex', myRe.lastIndex); // 下一个匹配开始时的索引
console.log('myRe.source', myRe.source); // 匹配模式文本
运行结果:
下面调用字符串内置的 match 方法:
var myRe = /d(b+)d/g;
var myArray = 'cdbbdbsbz'.match(myRe);
console.log('myArray', myArray); // 结果数组
console.log('myRe', myRe); // 正则
console.log('myRe.lastIndex', myRe.lastIndex); // 下一个匹配开始时的索引
console.log('myRe.source', myRe.source); // 匹配模式文本
运行结果:
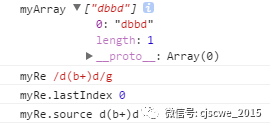
总结:对于 RegExp 的方法 exec 匹配成功时,会返回该数组并更新正则的全局检索属性(lastIndex);而字符串的方法 match 则不会更新全局检索属性。
4.2 分组与反向引用
对于正则表达式中的小括号会进行模式分组同时生成保存小括号匹配项的反向引用。比如:
var re = /(\w+)\s(\w+)/;
var str = 'John Smith';
var newstr = str.replace(re, '$2, $1');
console.log(newstr); // 运行结果:Smith, John
4.3 高级搜索与标志(flags)
正则表达式有五个可选标志,比如,允许全局和不区分大小写的匹配模式。这些标志可以以任何顺序单独使用或一起使用,并作为正则表达式的一部分。
标志(flags) 描述
g global,全局匹配(找到所有匹配,而不是在第一个匹配后停止)。
i insensitive,不区分大小写的匹配([a-zA-Z])。
m multi line,多行匹配,使 ^ 和 $ 匹配每行的开始和结束(不仅仅表示字符串的开始和结束)。
u unicode,将模式视为 Unicode 序列。
y sticky,强制模式从上一次匹配后的索引位开始匹配。
使用语法:
var re = /pattern/flags;
或者:
var re = new RegExp('pattern', 'flags');
5. 参考
Regular Expressions
(https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions#Advanced_searching_with_flags)
转自: https://segmentfault.com/a/1190000009169325
作者: 小无路
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
如果文章不错,请转发的朋友圈!

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>

==========阅读原文==========





