作者:阿萨姆
普华永道|数据科学家
量子位 已授权编辑发布
0. 前言
我更喜欢把”思想”认为是一种“道”,而”模型”是一种”术”,也可类比为“外功”和“内功”。
本文有标题党之嫌,因为讨论的内容并非严格的哲学命题。但机器学习中有很多思想换个角度看和其他学科息息相关,甚至共通。在此总结了一些我觉得有意思的观察,供大家讨论。

△ 图为拉斐尔为梵蒂冈宫教皇绘制的哲学主题壁画《雅典学派》
1. 没有免费的午餐定理(No Free Lunch Theorem)
- 什么算法最好?
NFL定理由Wolpert在1996年提出,其应用领域原本为经济学。和那句家喻户晓的”天下没有免费的午餐”有所不同, NFL讲的是优化模型的评估问题。
而我们耳熟能详的“天下没有免费的午餐”最早是说,十九世纪初很多欧美酒吧和旅店为了提升销售额向顾客提供免费的三明治,而客人贪图免费的三明治却意外的买了很多杯酒,酒吧从而获利更多了,以此来教育大家不要贪小便宜吃大亏。
在机器学习领域,NFL的意义在于告诉机器学习从业者:”假设所有数据的分布可能性相等,当我们用任一分类做法来预测未观测到的新数据时,对于误分的预期是相同的。”
简而言之,NFL的定律指明,如果我们对要解决的问题一无所知且并假设其分布完全随机且平等,那么任何算法的预期性能都是相似的。
这个定理对于“盲目的算法崇拜”有毁灭性的打击。例如,现在很多人沉迷“深度学习”不可自拔,那是不是深度学习就比其他任何算法都要好?在任何时候表现都更好呢?
未必,我们必须要加深对于问题的理解,不能盲目的说某一个算法可以包打天下。然而,从另一个角度说,我们对于要解决的问题往往不是一无所知,因此大部分情况下我们的确知道什么算法可以得到较好的结果。
举例,我们如果知道用于预测的特征之间有强烈的相关性(strong dependency),那么我们可以推测Naive Bayes(简单贝叶斯分类器)不会给出特别好的结果,因为其假设就是特征之间的独立性。
在某个领域、特定假设下表现卓越的算法不一定在另一个领域也能是“最强者”。正因如此,我们才需要研究和发明更多的机器学习算法来处理不同的假设和数据。George Box早在上世纪八十年代就说过一句很经典的话:”All models are wrong, but some are useful(所有的模型的都是错的,但其中一部分还是蛮有用的).” 这种观点也是NFL的另一种表述。
周志华老师在《机器学习》一书中也简明扼要的总结:“NFL定理最重要的寓意,是让我们清楚的认识到,脱离具体问题,空泛的谈‘什么学习算法更好’毫无意义。”
2. 奥卡姆剃刀定理(Occam’s Razor - Ockham定理)
- 少即是多
奥卡姆剃刀是由十二世纪的英国教士及哲学家奥卡姆提出的:“ 如无必要,勿增实体”。

用通俗的语言来说,如果两个模型A和B对数据的解释能力完全相同,那么选择较为简单的那个模型。在统计学和数学领域,我们偏好优先选择最简单的那个假设,如果与其他假设相比其对于观察的描述度一致。
奥卡姆剃刀定理对于机器学习的意义在于它给出了一种模型选择的方法,对待过拟合(over-fitting)问题有指导意义。就像我以前的文章提到的,如果简单的线性回归和复杂的深度学习在某个问题上的表现相似(如相同的误分率),那么我们应该选择较为简单的线性回归。
Murphy在MLAPP中用Tenenbaum的强抽样假设(strong sampling assumption)来类比奥卡姆剃刀原理。首先他给出了下面的公式,Pr(D|h)代表了我们重置抽样(sampling with replacement)N次后得到集合D时,某种假设h为真的概率。
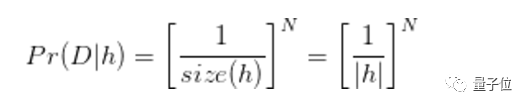
举例,我们有0~99共100个数字,每次从其中随机抽出一个数字并放回,重复抽取N次。若随机抽了并放回了5次,我们抽出了{2,4,8,16,32},于是我们想要推断(induct)抽取到底遵循什么规则。我们有两种假设:
h1: 我们是从{0,2,4,6,8,...,98}中抽取的,即从偶数中抽取
h2: 我们是从{2n}中抽取的
根据上文给出的公式进行计算,我们发现Pr(D|h1)远大于Pr(D|h2),即我们相信D={2,4,8,16,32}从h1:{2n}中产生的可能更大,但是h2:{0,2,4,6,8,...,98}似乎也能解释我们的结果。这个时候我们就应选择概率更高的那个。
从奥卡姆剃刀角度思考的话,h1:{2n}在0~99中只有5个满足要求的元素,而h2:{0,2,4,6,8,...,98}却有50个满足要求的元素。那么h1更加简单,更加符合尝试,选择它:)
提供这个例子的原因是为了提供一个量化方法来评估假设,其与奥卡姆剃刀有相同的哲学内涵。有兴趣的读者应该会发现奥卡姆剃刀的思想与贝叶斯推断是一致的,更细致的讨论可以看一篇关于贝叶斯推断的介绍。
文章链接:
http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/
但读者应该注意,奥卡姆剃刀定理只是一种对于模型选择的指导方向,不同的选择方向如集成学习(Ensemble Learning)就给出了近似相反的选择标准。现实世界是非常复杂的,切勿滥用。
3. 集成学习(Ensemble Learning) - 三个臭皮匠的智慧
集成学习的哲学思想是“众人拾柴火焰高”,和其他机器学习模型不同,集成学习将多个较弱的机器学习(臭皮匠)模型合并起来来一起决策(诸葛亮)。比较常见的方法有多数投票法(majority vote),即少数服从多数。
如果我们有10个”子分类器”通过一个人的疾病史来推断他能活多大,其中8个说他会活过200岁,其中2个说他在200岁前会死,那么我们相信他可以活过200岁。
集成学习的思想无处不在,比较著名的有随机森林等。从某种意义上说,神经网络也是一种集成学习,有兴趣小伙伴可以想想为什么…
相信敏锐的读者已经发现,集成学习似乎和前面提到的奥卡姆剃刀定理相违背。明明一个分类模型就够麻烦了,现在为什么要做更多?这其实说到了一个很重要观点,就是奥卡姆剃刀定理并非不可辩驳的真理,而只是一种选择方法。
从事科学研究,切勿相信有普遍真理。周孝正教授曾说:”若一件事情不能证实,也不能证伪,就要存疑。” 恰巧,奥卡姆定理就是这样一种不能证实也不能证伪的定理。
而集成学习的精髓在于假设“子分类器”的错误相互独立,随着集成中子分类器的数目上升,集成学习后的”母分类器”的误差将会以指数级别下降,直至为0。
然而,这样的假设是过分乐观的,因为我们无法保证”子分类器”的错误是相互独立的。以最简单的Bagging为例,如果为了使k个子分类器的错误互相独立,那么我们将训练数据N分为k份。
显然,随着k值上升,每个分类器用于训练的数据量都会降低,每个子训练器的准确性也随之下降。即使我们允许训练数据间有重采样,也还是无法避免子分类器数量和准确性之间的矛盾。
周志华老师曾这样说:”个体学习的准确性和多样性本身就存在冲突,一般的,准确性很高后,要增加多样性就需牺牲准确性。事实上,如何产生并结合好而不同个体学习器,恰是集合学习的研究核心。”
而为什么集成学习有效,就不得不提Bias-Variance Tradeoff。在带你读机器学习经典(一): An Introduction to Statistical Learning (Chapter 1&2),我曾介绍过一个学习模型的泛化误差(Generalization Error)由偏差(Bias),方差(Variance)及内在噪音(Intrinsic Noise)共同决定。
《带你读机器学习经典(一)》链接:
https://zhuanlan.zhihu.com/p/27556007
大部分模型很难同时通过降低bias和variance来达到较好的泛化效果,而集成学习不同,这也是其优势所在。从理论上说,集成学习往往可以同时有效的降低bias和variance,或者在控制一方的前提下降低另一方。此处按下不表。
4. 频率学派(Frequentists)和贝叶斯学派(Bayesian)
- 剑宗与气宗之争
每次学术讨论的茶余饭后,总会有人开玩笑问起,你是哪一派的?这似乎是一种信仰。
相信很多统计学习领域的小伙伴们都会无意间听到类似的说法。对于不熟悉的读者来说,无论是机器学习还是统计学习都是一种寻找一种映射,或者更广义的说,进行参数估计。以线性回归为例,我们得到结果仅仅是一组权重。
如果我们的目标是参数估计,那么有一个无法回避的问题…参数到底存不存在?换句话说,茫茫宇宙中是否到处都是不确定性(Uncertainty)。
频率学派相信参数是客观存在的,虽然未知,但不会改变。因此频率学派的方法一直都是试图估计“哪个值最接近真实值”,相对应的我们使用最大似然估计(Maximum Likelihood Estimation),置信区间(Confidence Level), 和p-value。因此这一切都是体现我们对于真实值估算的自信和可靠度。
而贝叶斯学派相信参数不是固定的,我们需要发生过的事情来推测参数,这也是为什么总和先验(Prior)及后验(Posterior)过不去,才有了最大后验(Maximum a Posteriori)即MAP。
贝叶斯学派最大的优势在于承认未知(Uncertainty)的存在,因此感觉更符合我们的常识“不可知论”。从此处说,前文提到的周孝正教授大概是贝叶斯学派的(周教授是社会学家而不是统计学家)。
据我不权威观察,统计学出身的人倾向于频率学派而机器学习出身的人更倾向于贝叶斯学派。比如著名的机器学习书籍PRML就是一本贝叶斯学习,而Murphy在MLAPP中曾毫无保留的花了一个小节指明频率学派的牵强。
就像豆腐脑是甜的还是咸的,这样的问题还是留给读者们去思考。需要注意的是,两种思想都在现实中都有广泛的应用,切勿以偏概全。更多的思考可以看这篇有关贝叶斯学派与频率学派有何不同的讨论。
文章链接:
https://www.zhihu.com/question/20587681
5. 后记 - 无处不在的妥协

接触机器学习的早期阶段,时间往往都花在了研究算法上。随着学习的深入,相信大家会慢慢发现其实算法思想的精髓是…无处不在的妥协。本文只能涉及到几种“矛盾”和“妥协”,更多的留给大家慢慢发掘和思考:)
比如,本文未敢涉及到“统计学习”和“机器学习”之间的区别,也是一种妥协—模型可解释性与有效性的妥协。无处不在的妥协还包含“模型精度”和“模型效率”的妥协,“欠拟合”和“过拟合”的平衡等。
大部分科学,比如数学还是物理,走到一定程度,都是妥协,都有妥协带来的美感。这给我们的指导是:当我们听到不同的想法的时候,反驳之前先想一想,不要急着捍卫自己的观点。
伊夫林•霍尔曾说过:”我不同意你的说法,但我誓死捍卫你说话的权利。” 我觉得这不仅仅可以作为探讨科学的态度,也大可以作为我们指导人生的一种思路。
——与君共勉
点击左下角“阅读原文”处,解锁更多作者文章
看看他的炼丹炉是什么样子的~
一则通知
量子位读者5群开放申请,对人工智能感兴趣的朋友,可以添加量子位小助手的微信qbitbot2,申请入群,一起研讨人工智能。
另外,量子位大咖云集的自动驾驶技术群,仅接纳研究自动驾驶相关领域的在校学生或一线工程师。申请方式:添加qbitbot2为好友,备注“自动驾驶”申请加入~
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容










