机器之心原创
作者:Yi Jin、Joni Chuang
参与:Panda
挪威科技大学 Didrik Nielsen 的硕士论文《使用 XGBoost 的树提升:为什么 XGBoost 能赢得「每一场」机器学习竞赛?(Tree Boosting With XGBoost - Why Does XGBoost Win "Every" Machine Learning Competition?)》研究分析了 XGBoost 与传统 MART 的不同之处以及在机器学习竞赛上的优势。机器之心技术分析师对这篇长达 110 页的论文进行了解读,提炼出了其中的要点和核心思想,汇成此篇。本文原文发表在机器之心英文官网上。
论文原文:https://brage.bibsys.no/xmlui/bitstream/handle/11250/2433761/16128_FULLTEXT.pdf
解读文章英文原文:https://syncedreview.com/2017/10/22/tree-boosting-with-xgboost-why-does-xgboost-win-every-machine-learning-competition/
引言
tree boosting(树提升)已经在实践中证明可以有效地用于分类和回归任务的预测挖掘。
之前很多年来,人们所选择的树提升算法一直都是 MART(multiple additive regression tree/多重累加回归树)。但从 2015 年开始,一种新的且总是获胜的算法浮出了水面:XGBoost。这种算法重新实现了树提升,并在 Kaggle 和其它数据科学竞赛中屡获佳绩,因此受到了人们的欢迎。
在《Tree Boosting With XGBoost - Why Does XGBoost Win "Every" Machine Learning Competition?》这篇论文中,来自挪威科技大学的 Didrik Nielsen 研究调查了:
XGBoost 与传统 MART 的不同之处
XGBoost 能赢得「每一场」机器学习竞赛的原因
这篇论文分成三大部分:
回顾统计学习的一些核心概念
介绍 boosting 并以函数空间中数值优化的方式对其进行解释;进一步讨论更多树方法以及树提升方法的核心元素
比较 MART 和 XGBoost 所实现的树提升算法的性质;解释 XGBoost 受欢迎的原因
统计学习的基本概念
这篇论文首先介绍了监督学习任务并讨论了模型选择技术。
机器学习算法的目标是减少预期的泛化误差,这也被称为风险(risk)。如果我们知道真实的分布 P(x,y),那么风险的最小化就是一个可以通过优化算法解决的最优化任务。但是,我们并不知道真实分布,只是有一个用于训练的样本集而已。我们需要将其转换成一个优化问题,即最小化在训练集上的预期误差。因此,由训练集所定义的经验分布会替代真实分布。上述观点可以表示成下面的统计学公式:

其中  是模型的真实风险 R(f) 的经验估计。L(.) 是一个损失函数,比如平方误差损失函数(这是回归任务常用的损失函数),其它损失函数可以在这里找到:http://www.cs.cornell.edu/courses/cs4780/2017sp/lectures/lecturenote10.html。n 是样本的数量。
是模型的真实风险 R(f) 的经验估计。L(.) 是一个损失函数,比如平方误差损失函数(这是回归任务常用的损失函数),其它损失函数可以在这里找到:http://www.cs.cornell.edu/courses/cs4780/2017sp/lectures/lecturenote10.html。n 是样本的数量。
当 n 足够大时,我们有:

ERM(经验风险最小化)是一种依赖于经验风险的最小化的归纳原理(Vapnik, 1999)。经验风险最小化运算 f hat 是目标函数的经验近似,定义为:

其中 F 属于某个函数类,并被称为某个模型类(model class),比如常数、线性方法、局部回归方法(k-最近邻、核回归)、样条函数等。ERM 是从函数集 F 中选择最优函数 f hat 的标准。
这个模型类和 ERM 原理可以将学习问题转变成优化问题。模型类可以被看作是候选的解决方案函数,而 ERM 则为我们提供了选择最小化函数的标准。
针对优化问题的方法有很多,其中两种主要方法是梯度下降法和牛顿法;MART 和 XGBoost 分别使用了这两种方法。
这篇论文也总结了常见的学习方法:
1. 常数
2. 线性方法
3. 局部最优方法
4. 基函数扩展:显式非线性项、样条、核方法等
5. 自适应基函数模型:GAM(广义相加模型)、神经网络、树模型、boosting
另一个机器学习概念是模型选择(model selection),这要考虑不同的学习方法和它们的超参数。首要的问题一直都是:增加模型的复杂度是否更好?而答案也总是与模型自身的泛化性能有关。如下图 1 所示,我们也许可以在模型更加复杂的同时得到更好的表现(避免欠拟合),但我们也会失去泛化性能(过拟合):

图 1:泛化性能 vs 训练误差
为平方损失使用预期条件风险的经典的偏置-方差分解(bias-variance decomposition),我们可以观察风险相对于复杂度的变化:

图 2:预期风险 vs 方差 vs 偏置
为此通常使用的一种技术是正则化(regularization)。通过隐式和显式地考虑数据的拟合性和不完善性,正则化这种技术可以控制拟合的方差。它也有助于模型具备更好的泛化性能。
不同的模型类测量复杂度的方法也不一样。LASSO 和 Ridge(Tikhonov regularization)是两种常用于线性回归的测量方法。我们可以将约束(子集化、步进)或惩罚(LASSO、Ridge)直接应用于复杂度测量。
理解 Boosting、树方法和树提升
Boosting
boosting 是一种使用多个更简单的模型来拟合数据的学习算法,它所用的这些更简单的模型也被称为基本学习器(base learner)或弱学习器(weak learner)。其学习的方法是使用参数设置一样或稍有不同的基本学习器来自适应地拟合数据。
Freund 和 Schapire (1996) 带来了第一个发展:AdaBoost。实际上 AdaBoost 是最小化指数损失函数,并迭代式地在加权的数据上训练弱学习器。研究者也提出过最小化对数损失的二阶近似的新型 boosting 算法:LogitBoost。
Breiman (1997a,b 1998) 最早提出可以将 boosting 算法用作函数空间中的数值优化技术。这个想法使得 boosting 技术也可被用于回归问题。这篇论文讨论了两种主要的数值优化方法:梯度提升和牛顿提升(也被称为二阶梯度提升或 Hessian boosting,因为其中应用了 Hessian 矩阵)。下面,让我们一步一步了解 boosting 算法。
boosting 拟合同一类的集成模型(ensemble model):

其可以被写成自适应基函数模型:

其中 f_0(x)=θ_0 且 f_m(x)=θ_m*Φ_m(x),m=1,…,M,Φm 是按顺序累加的基本函数,可用于提升当前模型的拟合度。
因此,大多数 boosting 算法都可以看作是在每次迭代时或准确或近似地求解

所以,AdaBoost 就是为指数损失函数求解上述等式,其约束条件为:Φm 是 A={-1,1} 的分类器。而梯度提升或牛顿提升则是为任意合适的损失函数近似求解上述等式。
梯度提升和牛顿提升的算法如下:


最常用的基本学习器是回归树(比如 CART),以及分量形式的线性模型(component-wise linear model)或分量形式的平滑样条(component-wise smoothing spline)。基本学习器的原则是要简单,即有很高的偏置,但方差很低。
boosting 方法中的超参数有:
迭代次数 M:M 越大,过拟合的可能性就越大,因此需要验证集或交叉验证集。
学习率 η :降低学习率往往会改善泛化性能,但同时也会让 M 增大,如下图所示。
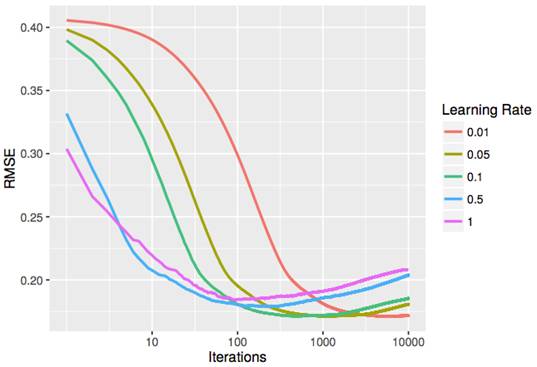
在 Boston Housing 数据集上的不同学习率的样本外(out-of-sample)RMSE
树方法
树模型是简单和可解释的模型。它们的预测能力确实有限,但将多个树模型组合到一起(比如 bagged trees、随机森林或在 boosting 中),它们就可以变成一种强大的预测模型。
我们可以将树模型看作是将特征空间分割成几个不同的矩形和非重叠区域集合,然后它可以拟合一些简单的模型。下图给出了使用 Boston Housing 数据得到的可视化结果:

终端节点的数量和树的深度可以看作是树模型的复杂度度量。为了泛化这种模型,我们可以在复杂度度量上轻松地应用一个复杂度限制,或在终端节点的数量或叶权重的惩罚项上应用一个惩罚(XGBoost 使用的这种方法)。
因为学习这种树的结构是 NP 不完全的,所以学习算法往往会计算出一个近似的解。这方面有很多不同的学习算法,比如 CART(分类和回归树)、C4.5 和 CHAID。这篇论文描述了 CART,因为 MART 使用的 CART,XGBoost 也实现了一种与 CART 相关的树模型。
CART 以一种自上而下的方式生长树。通过考虑平行于坐标轴的每次分割,CART 可以选择最小化目标的分割。在第二步中,CART 会考虑每个区域内每次平行的分割。在这次迭代结束时,最好的分割会选出。CART 会重复所有这些步骤,直到达到停止标准。
给定一个区域 Rj,学习其权重 wj 通常很简单。令 Ij 表示属于区域 Rj 的索引的集合,即 xi∈Rj,其中 i∈Ij。
其权重是这样估计的:

对于一个树模型 f_hat,经验风险为:

其中我们令 L_j hat 表示节点 j 处的累积损失。在学习过程中,当前树模型用 f_before hat 和 f_after hat 表示。
我们可以计算所考虑的分割所带来的增益:
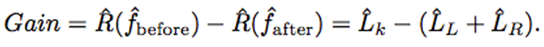
对于每一次分割,每个可能节点的每个可能分割都会计算这种增益,再取其中最大的增益。
现在让我们看看缺失值。CART 会使用替代变量(surrogate variable)来处理缺失值,即对于每个预测器,我们仅使用非缺失数据来寻找分割,然后再基于主分割寻找替代预测因子,从而模拟该分割。比如,假设在给定的模型中,CART 根据家庭收入分割数据。如果一个收入值不可用,那么 CART 可能会选择教育水平作为很好的替代。
但 XGBoost 是通过学习默认方向来处理缺失值。XGBoost 会在内部自动学习当某个值缺失时,最好的方向是什么。这可以被等价地看作是根据训练损失的减少量而自动「学习」缺失值的最佳插补值。
根据类别预测器,我们可以以两种方式处理它们:分组类别或独立类别。CART 处理的是分组类别,而 XGBoost 需要独立类别(one-hot 编码)。
这篇论文以列表的形式总结了树模型的优缺点:
优点(Hastie et al., 2009; Murphy, 2012):
• 容易解释
• 可以相对快地构建
• 可以自然地处理连续和分类数据
• 可以自然地处理缺失数据
• 对输入中的异常值是稳健的
• 在输入单调变换时是不变的
• 会执行隐式的变量选择
• 可以得到数据中的非线性关系
• 可以得到输入之间的高阶交互
• 能很好地扩展到大型数据集
缺点(Hastie et al., 2009; Kuhn and Johnson, 2013; Wei-Yin Loh, 1997; Strobl et al., 2006):
• 往往会选择具有更高数量的不同值的预测器
• 当预测器具有很多类别时,可能会过拟合
• 不稳定,有很好的方差
• 缺乏平滑
• 难以获取叠加结构
• 预测性能往往有限
树提升
在上述发展的基础上,现在我们将 boosting 算法与基本学习器树方法结合起来。
提升后的树模型可以看作是自适应基函数模型,其中的基函数是回归树:

提升树模型(boosting tree model)是多个树 fm 的和,所以也被称为树集成(tree ensemble)或叠加树模型(additive tree model)。因此它比单个树模型更加平滑,如下图所示:

拟合 Boston Housing 数据的叠加树模型的可视化
在提升树模型上实现正则化的方法有很多:
1. 在基函数扩展上进行正则化
2. 在各个树模型上进行正则化
3. 随机化
一般来说,提升树往往使用很浅的回归树,即仅有少数终端节点的回归树。相对于更深度的树,这样的方差较低,但偏置更高。这可以通过应用复杂度约束来完成。
XGBoost 相对于 MART 的优势之一是复杂度的惩罚,这对叠加树模型而言并不常见。目标函数的惩罚项可以写成:

其中第一项是每个单个树的终端节点的数量,第二项是在该项权重上的 L2 正则化,最后一项是在该项权重上的 L1 正则化。
Friedman(2002) 最早引入了随机化,这是通过随机梯度下降实现的,其中包括在每次迭代时进行行子采样(row subsampling)。随机化有助于提升泛化性能。子采样的方法有两种:行子采样与列子采样(column subsampling)。MART 仅包含行子采样(没有替代),而 XGBoost 包含了行子采样和列子采样两种。
正如前面讨论的那样,MART 和 XGBoost 使用了两种不同的 boosting 算法来拟合叠加树模型,分别被称为 GTB(梯度树提升)和 NTB(牛顿树提升)。这两种算法都是要在每一次迭代 m 最小化:

其基函数是树:

其一般步骤包含 3 个阶段:
1. 确定一个固定的候选树结构的叶权重 ;
2. 使用前一阶段确定的权重,提出不同的树结构,由此确定树结构和区域;
3. 一旦树结构确定,每个终端节点中的最终叶权重(其中 j=1,..,T)也就确定了。
算法 3 和 4 使用树作为基函数,对算法 1 和 2 进行了扩展:


XGBoost 和 MART 的差异
最后,论文对两种树提升算法的细节进行了比较,并试图给出 XGBoost 更好的原因。
算法层面的比较
正如之前的章节所讨论的那样,XGBoost 和 MART 都是要通过简化的 FSAM(Forward Stage Additive Modelling/前向阶段叠加建模)求解同样的经验风险最小化问题:

即不使用贪婪搜索,而是每次添加一个树。在第 m 次迭代时,使用下式学习新的树:

XGBoost 使用了上面的算法 3,即用牛顿树提升来近似这个优化问题。而 MART 使用了上面的算法 4,即用梯度树提升来做这件事。这两种方法的不同之处首先在于它们学习树结构的方式,然后还有它们学习分配给所学习的树结构的终端节点的叶权重的方式。
再看看这些算法,我们可以发现牛顿树提升有 Hessian 矩阵,其在确定树结构方面发挥了关键性的作用,XGBoost:
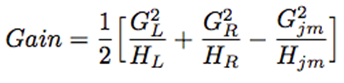
而使用了梯度树提升的 MART 则是:

然后,XGBoost 可以直接这样定义牛顿树提升的叶权重:

使用梯度树提升的 MART 则这样定义:

总结一下,XGBoost 使用的 Hessian 是一种更高阶的近似,可以学习到更好的树结构。但是,MART 在确定叶权重上表现更好,但却是对准确度更低的树结构而言。
在损失函数的应用性方面,牛顿树提升因为要使用 Hessian 矩阵,所以要求损失函数是二次可微的。所以它在选择损失函数上要求更加严格,必须要是凸的。
当 Hessian 每一处都等于 1 时,这两种方法就是等价的,这就是平方误差损失函数的情况。因此,如果我们使用平方误差损失函数之外的任何损失函数,在牛顿树提升的帮助下,XGBoost 应该能更好地学习树结构。只是梯度树提升在后续的叶权重上更加准确。因此无法在数学上对它们进行比较。
尽管如此,该论文的作者在两个标准数据集上对它们进行了测试:Sonar 和 Ionosphere(Lichman, 2013)。这个实证比较使用了带有 2 个终端节点的树,没有使用其它正则化,而且这些数据也没有分类特征和缺失值。梯度树提升还加入了一个线搜索(line search),如图中红色线所示。

这个比较图说明这两种方法都能无缝地执行。而且线搜索确实能提升梯度提升树的收敛速度。
正则化比较
正则化参数实际上有 3 类:
1.boosting 参数:树的数量 M 和学习率η
2. 树参数:在单个树的复杂度上的约束和惩罚
3. 随机化参数:行子采样和列子采样
两种 boosting 方法的主要差别集中在树参数以及随机化参数上。
对于树参数,MART 中的每个树都有同样数量的终端节点,但 XGBoost 可能还会包含终端节点惩罚 γ,因此其终端节点的数量可能会不一样并且在最大终端节点数量的范围内。XGBoost 也在叶权重上实现了 L2 正则化,并且还将在叶权重上实现 L1 正则化。
在随机化参数方面,XGBoost 提供了列子采样和行子采样;而 MART 只提供了行子采样。
为什么 XGBoost 能赢得「每一场」竞赛?
通过使用模拟数据,论文作者首次表明树提升可以被看作是自适应地确定局部邻域。
使用
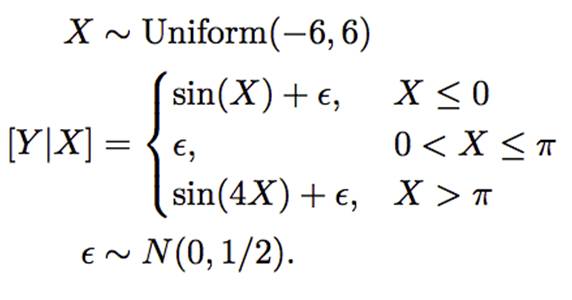
生成

然后使用局部线性回归(使用了两种不同灵活度的拟合)来拟合它:

然后使用平滑样条函数(使用了两种不同灵活度的拟合)来拟合它:

现在我们尝试提升的树桩(boosted tree stump)(两个终端节点)拟合:
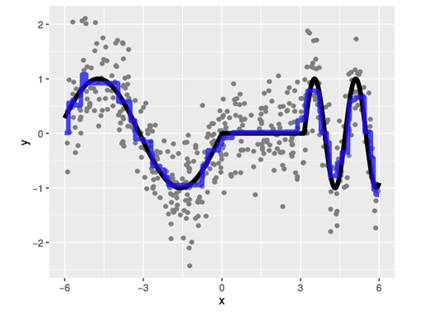
本论文详细说明了权重函数影响拟合的确定的方式,并且表明树提升可以被看作是直接在拟合阶段考虑偏置-方差权衡。这有助于邻域保持尽可能大,以避免方差不必要地增大,而且只有在复杂结构很显然的时候才会变小。
尽管当涉及到高维问题时,树提升「打败了」维度的诅咒(curse of dimensionality),而没有依赖任何距离指标。另外,数据点之间的相似性也可以通过邻域的自适应调整而从数据中学习到。这能使模型免疫维度的诅咒。
另外更深度的树也有助于获取特征的交互。因此无需搜索合适的变换。
因此,是提升树模型(即自适应的确定邻域)的帮助下,MART 和 XGBoost 一般可以比其它方法实现更好的拟合。它们可以执行自动特征选择并且获取高阶交互,而不会出现崩溃。
通过比较 MART 和 XGBoost,尽管 MART 确实为所有树都设置了相同数量的终端节点,但 XGBoost 设置了 Tmax 和一个正则化参数使树更深了,同时仍然让方差保持很低。相比于 MART 的梯度提升,XGBoost 所使用的牛顿提升很有可能能够学习到更好的结构。XGBoost 还包含一个额外的随机化参数,即列子采样,这有助于进一步降低每个树的相关性。
机器之心分析师的看法
这篇论文从基础开始,后面又进行了详细的解读,可以帮助读者理解提升树方法背后的算法。通过实证和模拟的比较,我们可以更好地理解提升树相比于其它模型的关键优势以及 XGBoost 优于一般 MART 的原因。因此,我们可以说 XGBoost 带来了改善提升树的新方法。
本分析师已经参与过几次 Kaggle 竞赛了,深知大家对 XGBoost 的兴趣以及对于如何调整 XGBoost 的超参数的广泛深度的讨论。相信这篇文章能够启迪和帮助初学者以及中等水平的参赛者更好地详细理解 XGBoost。
参考文献
Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining, KDD 』16, pages 785–794, New York, NY, USA. ACM.
Freund, Y. and Schapire, R. E. (1996). Experiments with a new boosting algorithm. In Saitta, L., editor, Proceedings of the Thirteenth International Conference on Machine Learning (ICML 1996), pages 148–156. Morgan Kaufmann.
Friedman, J. H. (2002). Stochastic gradient boosting. Comput. Stat. Data Anal., 38(4):367–378.
Hastie, T., Tibshirani, R., and Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. Springer Series in Statistics. Springer.
Kuhn, M. and Johnson, K. (2013). Applied Predictive Modeling. SpringerLink : Bu ̈cher. Springer New York.
Lichman, M. (2013). UCI machine learning repository.
Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. The MIT Press.
Strobl, C., laure Boulesteix, A., and Augustin, T. (2006). Unbiased split selection for classification trees based on the gini index. Technical report.
Vapnik, V. N. (1999). An overview of statistical learning theory. Trans. Neur. Netw., 10(5):988–999.
Wei-Yin Loh, Y.-S. S. (1997). Split selection methods for classification trees. Statistica Sinica, 7(4):815–840.
Wikipedia::Lasso. https://en.wikipedia.org/wiki/Lasso_(statistics)
Wikipedia::Tikhonov regularization. https://en.wikipedia.org/wiki/Tikhonov_regularization

点击【阅读原文】报名参赛,美国赛区报名请点击大赛首页 US 进入美国赛区报名通道







