当地时间 2017 年 4 月 24-26 日,第五届 ICLR 会议将在法国土伦举行。会议的第一天已经过去,在这一天的会议上有什么值得关注的亮点呢?机器之心在本文中介绍了研究者 Carlos E. Perez 在 Medium 上总结的那些虽然被拒,但仍然值得关注的/有亮点的论文,还对谷歌、百度、Facebook 展示的部分热门研究论文进行了介绍。另外,ICLR 的官方 Facebook 主页有视频直播,现在也已能看到部分录制的视频:https://www.facebook.com/iclr.cc
十篇被拒的好论文
研究者与开发者、Intuition Machine 联合创始人 Carlos E. Perez 在 Medium 上发布了一篇文章,介绍了那些 ICLR 2017 却不幸被拒,但仍有价值的十篇论文。
据作者介绍,因为本届 ICLR 的论文评议方式存在很大的主观性(实际上也引起了很大的争议,参阅机器之心文章《学界 | ICLR2017 公布论文接收名单,匿名评审惹争议》),所以很多原本可能比较优秀的论文却因为某些原因被刷了下去。Perez 说:「这就是这个不幸的现实。」比如牛津大学、Google DeepMind 和加拿大高等研究院(CIFAR)的研究人员提出 LipNet 的重要论文《LipNet: End-to-End Sentence-level Lipreading 》就出人意料地被拒了,不过这篇论文并没有被包含在这份名单中。下面就列出了这十篇值得关注,却惨遭淘汰的论文。注:本文仅代表原作者的个人观点,不表示机器之心的立场。
1. 一种联合多任务模型:为多 NLP 任务生长一个神经网络(A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks)
作者:Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka, Richard Socher
地址:https://openreview.net/forum?id=SJZAb5cel
说明:这是一篇真正新颖的论文,给出了一种逐步生长(grow)神经网络的方法。这篇论文居然被拒了,真是让人惊讶!这篇论文为什么很重要呢?因为其表明了网络可以如何通过迁移学习(transfer learning)和域适应(domain adaptation)的方式进行开发。目前还没有多少论文在这个领域探索。
2. 分层的记忆网络(Hierarchical Memory Networks)
作者:Sarath Chandar, Sungjin Ahn, Hugo Larochelle, Pascal Vincent, Gerald Tesauro, Yoshua Bengio
地址:https://openreview.net/forum?id=BJ0Ee8cxx
说明:这也是一篇关于 NLP 的论文。瞧瞧其作者名单,这么多明星研究者的论文居然也被拒了,真是吓人!这篇论文可以说是探索记忆的层次概念的最早期的论文之一。大多数记忆增强式的网络往往只有扁平的记忆结构。这篇论文不应该被轻视。
3.RL²:通过慢速强化学习的快速强化学习(RL²: Fast Reinforcement Learning via Slow Reinforcement Learning)
作者:Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, Pieter Abbeel
地址:https://openreview.net/forum?id=HkLXCE9lx
说明:居然把这篇论文给拒了,评议者一定是在逗我!这可是一篇突破性的研究啊!我猜原因是因为标题里面的 RL² 看起来太吓人了。任何关于元学习(meta-learning)的研究都应该是畅销货,然而这篇论文尽管有声名显赫的作者,但还是惨遭淘汰。真是不可想象!
4. 揭秘残差网络(Demystifying ResNet)
作者:Sihan Li, Jiantao Jiao, Yanjun Han, Tsachy Weissman
地址:https://openreview.net/forum?id=SJAr0QFxe
说明:我很喜欢这篇论文,因为其给出了一些关于如何使用残差或 skip 连接的有见地的经验法则。2016 年最热门的创新,一些人尝试解构这项技术,然而他们的努力却遭受了打击。有人说因为这项研究中使用了简化过的模型。但这个理由可以说是荒唐可笑,你难道不会选择使用简化模型来表征复杂的模型吗?这难道不是理所当然的事情吗?
5. 一种神经知识语言模型(A Neural Knowledge Language Model)
作者:Sungjin Ahn, Heeyoul Choi, Tanel Parnamaa, Yoshua Bengio
地址:https://openreview.net/forum?id=BJwFrvOeg
说明:又是一篇关于 NLP 的论文,又是 Yoshua Bengio 被拒的一篇论文。将知识库与深度学习融合应该是一项非常重大的成果,然而这篇论文却因为「缺乏新颖性(lack of novelty)」而被驳回。评议者抱怨最多的是该论文的书写风格,真是不幸。
6. 知识适应:教会适应(Knowledge Adaptation: Teaching to Adapt)
作者:Sebastian Ruder, Parsa Ghaffari, John G. Breslin
地址:https://openreview.net/forum?id=rJRhzzKxl
说明:当我第二遍刷被拒的论文时,我才注意到这一篇。毕竟我自己也是有所偏见的,我更倾向于寻找关于域适应和迁移学习的研究。这篇论文给出了一些非常好的想法。不幸的是,这些想法没能打动评议者。
7. 张量混合模型(Tensorial Mixture Models)
作者:Or Sharir, Ronen Tamari, Nadav Cohen, Amnon Shashua
地址:https://openreview.net/forum?id=BJluGHcee
说明:我非常喜欢这篇论文,参考我的另一篇文章:https://medium.com/intuitionmachine/the-holographic-principle-and-deep-learning-52c2d6da8d9,不幸的是,评议者对该研究太多怀疑了。
8. 探究深度神经网络的表现力(On the Expressive Power of Deep Neural Networks)
作者:Maithra Raghu, Ben Poole, Jon Kleinberg, Surya Ganguli, Jascha Sohl-Dickstein
地址:https://openreview.net/forum?id=B1TTpYKgx
说明:如果这样的基础理论和实验研究论文都会被拒,而那些像炼丹一样的所谓的「深度学习研究」却能得到支持,那还研究个毛线!
9. 深度学习的 Hessian 特征值:奇点与超越(Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond)
作者:Levent Sagun, Leon Bottou, Yann LeCun
地址:https://openreview.net/forum?id=B186cP9gx
说明:WOW,Yann LeCun 的论文也被拒了,小伙伴们都惊呆了!这是故意在向著名作者的脸上丢鸡蛋吗?我猜想是因为这篇研究的基础实验数据不够性感,不能打动评审。有评论写道:「有趣的实验数据,但并没有理论。」简直是完全不切实际的期望。
10. 一个对深度网络损失表面的实证分析(An Empirical Analysis of Deep Network Loss Surfaces)
作者:Daniel Jiwoong Im, Michael Tao, Kristin Branson
地址:https://openreview.net/forum?id=rkuDV6iex
说明:在我另一篇文章,我谈到了关于随机梯度下降(SGD)作为一种隐式的正则化方法的另一个证据,这就是这篇论文所探讨的。但遗憾的是,这些挖掘出了非常令人印象深刻的数据的研究者却什么也没得到,只得到了论文被拒的羞辱。
最后,Perez 也谈了谈自己对于这些被拒的论文的看法:
那些试图提升我们的理解和经验的大胆研究不应该因为书写风格或没有足够的数据而受到惩罚。在研究的最前沿,获取合适的数据和进行实验要困难得多。我看到新颖的创新研究的问题之一是对评议者来说不太熟悉,然而遗憾的是,正是由于它们的新颖,作者却没能得到合理的对待。
对于深度学习本质上的实验研究来说,回报实在太少了。在这些情形中,研究者常常会使用简化的模型来进行易于理解的分析。人们不应该总是关注有很好的实验结果,当然这对机器工作方式的表征是足够有价值的;但如果缺少理论研究,我们基本上就是在毫无方向地摸黑「炼丹」。
人们很担忧,当前研究环境会对深度学习研究者越来越糟糕。这个领域发展得太快了,很多评议者的看法往往跟不上最新的研究发展。所以最后会造成批评写作风格而不是批评研究本质这样的情况发生。这么多好论文被拒,足以说明这种知识鸿沟之大。
接下来,机器之心对大会第一天谷歌、百度海报展示的两篇论文进行了介绍,Facebook 对话系统方面的研究在昨天的官方博客中也有所介绍。
谷歌:规模化的对抗机器学习
在 ICLR 2017 大会上,谷歌提交了为数最多的论文。据谷歌博客介绍,围绕神经网络与深度学习的理论与应用,谷歌开发了进行理解与泛化的新的学习方法。此次大会,谷歌共有 50 多位研究人员参与。值得一提的是,三篇最佳论文中有两篇都是来自于谷歌。
关于两篇最佳论文,机器之心在昨日的文章中已经进行了摘要介绍。但除了这两篇最佳论文,谷歌还 poster 展示了其他众多论文。其中,刚回到谷歌的 Ian Goodfellow 就海报展示了论文《Adversarial Machine Learning at Scale》。

摘要:对抗样本(adversarial examples)是被设计用来愚弄机器学习模型的恶意输入。它们总是从一种模型迁移到另一个,让 attackers 在不知道目标模型的参数的情况下进行黑箱攻击。对抗训练(adversarial training)是在对抗样本上明确地训练模型的过程,从而使它可在面临攻击时更稳健或可减少它在干净输入上的测试错误率。目前,对抗训练主要被用于一些小问题。在此研究中,我们将对抗训练应用到了 ImageNet。我们的贡献包括:(1)推荐如何将对抗训练成功地规模化到大型模型和数据集上。(2)观察对抗训练对单步 attack 方法的稳健性。(3)发现多步 attack 方法要比单步 attack 方法有较小的可迁移性,所以单步 attack 对进行黑箱 attack 更好。(4)分辨出是「lable leaking」效应造成对抗训练的模型在对抗样本上的表现比在干净样本上的表现更好,因为对抗样本构造流程使用真实标签(true label),所以该模型能学习利用构造流程中的规律。
百度:探索循环神经网络中的稀疏性
和谷歌一样,百度也是本届 ICLR 大会的白金赞助商。在大会开幕的第一天,百度海报展示了一篇论文《EXPLORING SPARSITY IN RECURRENT NEURAL NETWORKS》,据百度介绍,这一在 RNN 上的新研究能够使用稀疏训练将网络大小减少 90%。
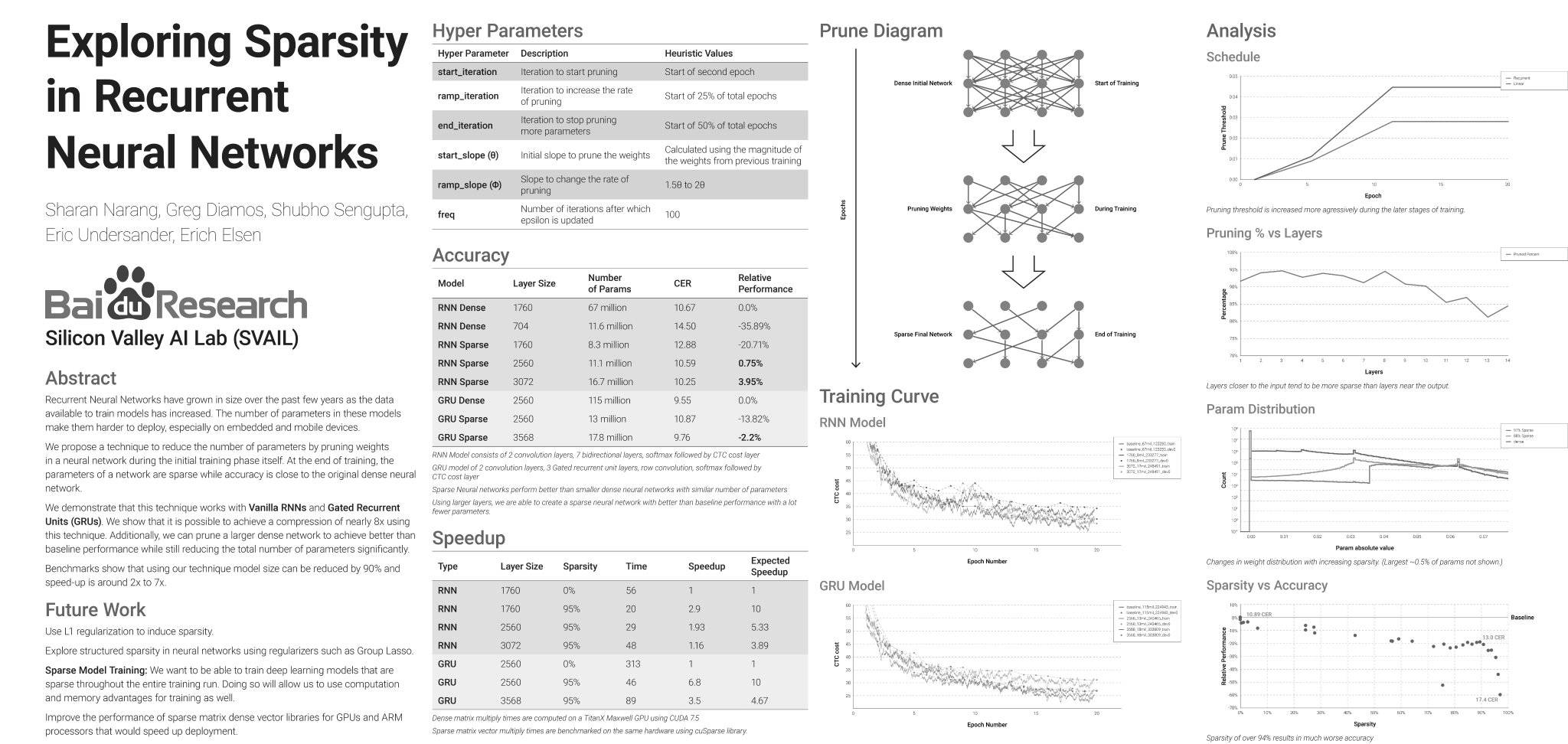
摘要:随着数据量、计算能力的提升,循环神经网络被普遍用来解决各种问题,也因此模型有大小。顶级的循环网络中的参数量使得他们难以部署,特别是在手机和嵌入式设备上。其中的挑战既在于模型的大小,也在于评估所要花费的时间。为了有效的部署这些循环网络,我们提出了一种技术,在网络的初始训练过程中通过剪枝权重的方法减少网络的参数。在训练结束时,网络的参数会稀疏,但准确率依然接近原始的密集型神经网络的准确率。网络的大小减小了 8 倍,而训练模型所需的时间不变。此外,在仍旧减少参数总量的情况下,我们能剪枝一个大型的密集网络从而获得比基线表现更好的结果。剪枝 RNN 减少了模型的大小,同时使用稀疏矩阵相乘极大的加速推论速度。基准表明,使用我们的技术能把大小减少 90%,速度提升 2 到 7 倍。
Facebook:对话系统研究
Facebook 的人工智能实验室主任 Yann LeCun 作为 ICLR 会议的发起人,在大会的第一开首先进行了演讲。

此次 ICLR 大会,Facebook 也通过多种形式展现了自己的最新研究成果。在昨日机器之心的文章中,Facebook 着重介绍了他们在对话系统方面的研究。
在官方博客中,Facebook 表示,「在让机器理解自然语言对话的内容一直是 Facebook 人工智能实验室的一项雄心勃勃的长期研究目标。真正有效的对话系统将会成为有效的辅助技术——其中会包含通过自然语言与人类进行交互的聊天系统。对话系统可以帮助用户更好地理解周遭的世界,更有效地与他人进行交流,消除沟通不畅的问题。随着网络世界的不断扩大,研究和开发这类技术正在变得越来越重要。」
此次大会上,Facebook 被接收的有关对话系统的研究有 7 篇,总共被接收的论文量为 18 篇。
本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









