
来源 | 简书,本文经作者授权转载。
作者 | 大吉大利小米酱 编辑:学妹

金秋九月,丹桂飘香,在这秋高气爽,阳光灿烂的收获季节里,我们送走了一个个暑假余额耗尽哭着走向校园的孩籽们,又即将迎来一年一度伟大祖国母亲的生日趴体(无心上班,迫不及待想为祖国母亲庆生!)。
那么问题来了,去哪儿玩呢?百度输了个“国庆”,出来的第一条居然是“去哪里旅游人少”……emmmmmmm,因缺思厅。
于是我萌生了通过旅游网站的景点销量来判断近期各景点流量情况的想法(这个想法很危险啊)。
所以这次的目标呢,是爬去哪儿网景点页面,并得到景点的信息,大家可以先思考下大概需要几步。
因为前几次爬虫都是爬一些文本信息,做一下词云之类的,中二的我觉得:没!意!思!了!这次正好爬的是数据,我决定用数据的好基友——图表来输出我爬取的数据,也就是说我要用爬取的景点销量以及景点的具体位置来生成一些可视化数据。
这里先安利一下百度的地图API和echarts,前者是专门提供地图API的工具,听说好多APP都在用它,后者是数据处理居家旅行的好伙伴,用了之后,它好,我也好(隐约觉得哪里不对)。
API是什么,API是应用程序的编程接口,就好像插头与插座一样,我们的程序需要电(这是什么程序?),插座中提供了电,我们只需要在程序中写一个与插座匹配的插头接口,就可以使用电来做我们想做的事情,而不需要知道电是如何产生的。
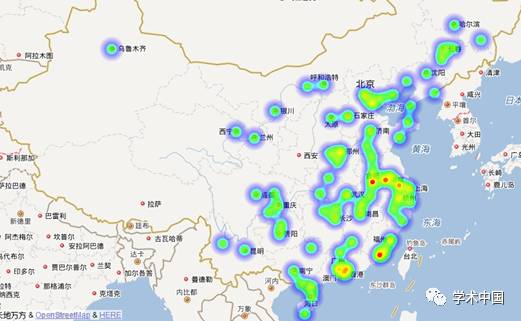
引入数据后的百度热力图
举个例子来讲,A想要把写完的小说出版成书,可是怎么出书捏?A不会呀,这时候A发现某出版社提供了出版服务,出版社表示只需要提供小说的正文、以及一个设计的封面就可以啦,于是A将小说保存成了word格式,又画了个封面jpg图,发给了出版社,没过多久米酱就拿到了一本装订好的书啦(此段纯属虚构,专业出版人士尽管打我,我不会承认的)。
在A出书的过程中,A并不需要知道出版社是怎么印刷这个书的,也不需要知道是怎么装订这个书的,A只需要提供出版社所要求的东西即可。
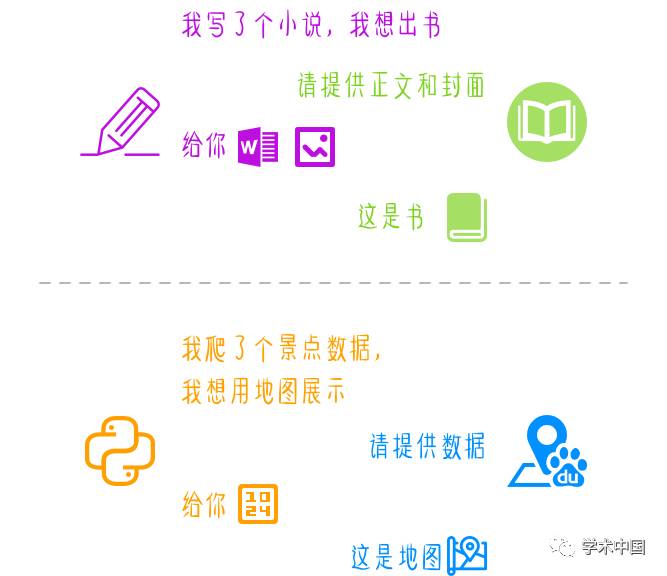
通过api对接的开发者与服务商
有人可能说,我已经懂了api是啥意思了,可是咋个用呢。关于这一点,我很负责任的告诉你:我也不会。
但是!
百度地图提供了很多API使用示例,有html基础,大致可以看懂,有js基础就可以尝试改函数了(不会jsの我默默地复制源代码),仔细观察源代码,可以知道热力图的生成主要的数据都存放在points这个变量中。
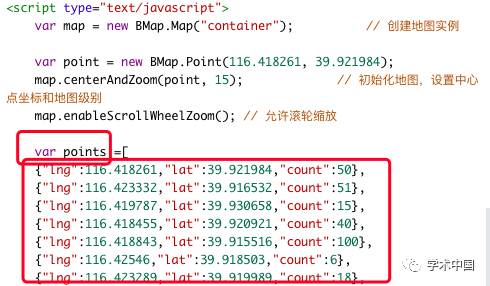
这种[{x:x,x:x},{x:x,x:x}]格式的数据,是一种json格式的数据,由于具有自我描述性,所以比较通俗易懂,大概可以知道这里的三个值,前俩个是经纬度,最后一个应该是权重(我猜的)。
也就是说,如果我希望将景点的热门程度生成为热力图,我需要得到景点的经纬度,以及它的权重,景点的销量可以作为权重,并且这个数据应该是json格式的呈现方式。
echarts也是一样滴(*^__^*)。
其实这次的爬虫部分是比较简单的(如果你有跟着我的文爬过网站的话)。
分析网址(去哪儿景点)→爬取分页中信息(景点经纬度、销量)→转为json文件。
分析去哪儿景点页的网址可得出结构:http://piao.qunar.com/ticket/list.htm?keyword=搜索地点®ion=&from=mpl_search_suggest&page=页数
这次没有用正则来匹配内容,而使用了xpath匹配,非常好用。
def getList():
place = raw_input('请输入想搜索的区域、类型(如北京、热门景点等):')
url = 'http://piao.qunar.com/ticket/list.htm?keyword='+ str(place) +'®ion=&from=mpl_search_suggest&page={}'
i = 1
sightlist = []
while i:
page = getPage(url.format(i))
selector = etree.HTML(page)
print '正在爬取第' + str(i) + '页景点信息'
i+=1
informations = selector.xpath('//div[@class="result_list"]/div')
for inf in informations: #获取必要信息
sight_name = inf.xpath('./div/div/h3/a/text()')[0]
sight_level = inf.xpath('.//span[@class="level"]/text()')
if len(sight_level):
sight_level = sight_level[0].replace('景区','')
else:
sight_level = 0
sight_area = inf.xpath('.//span[@class="area"]/a/text()')[0]
sight_hot = inf.xpath('.//span[@class="product_star_level"]//span/text()')[0].replace('热度 ','')
sight_add = inf.xpath('.//p[@class="address color999"]/span/text()')[0]
sight_add = re.sub('地址:|(.*?)|\(.*?\)|,.*?$|\/.*?$','',str(sight_add))
sight_slogen = inf.xpath('.//div[@class="intro color999"]/text()')[0]
sight_price = inf.xpath('.//span[@class="sight_item_price"]/em/text()')
if len(sight_price):
sight_price = sight_price[0]
else:
i = 0
break
sight_soldnum = inf.xpath('.//span[@class="hot_num"]/text()')[0]
sight_url = inf.xpath('.//h3/a[@class="name"]/@href')[0]
sightlist.append([sight_name,sight_level,sight_area,float(sight_price),int(sight_soldnum),float(sight_hot),sight_add.replace('地址:',''),sight_slogen,sight_url])
time.sleep(3)
return sightlist,place
可右划查看
1.这里把每个景点的所有信息都爬下来了(其实是为了练习使用xpath……)。
2.使用了while循环,for循环的break的方式是发现无销量时给i值赋零,这样while循环也会同时结束。
3.地址的匹配使用re.sub()函数去除了n多复杂信息,这点后面解释。
为了防止代码运行错误,为了维护代码运行的和平,将输出的信息列表存入到excel文件中了,方便日后查阅,很简单的代码,需要了解pandas的用法。
def listToExcel(list,name):
df = pd.DataFrame(list,columns=['景点名称','级别','所在区域','起步价','销售量','热度','地址','标语','详情网址'])
df.to_excel(name + '景点信息.xlsx')
可右划查看
非常悲伤的,(〒︿〒)我没找到去哪儿景点的经纬度,以为这次学(zhuang)习(bi)计划要就此流产了。(如果有人知道景点经纬度在哪里请告诉我)
但是,我怎么会放弃呢,我又找到了百度经纬度api,网址:http://api.map.baidu.com/geocoder/v2/?address=地址&output=json&ak=百度密钥,修改网址里的“地址”和“百度密钥”,在浏览器打开,就可以看到经纬度的json信息。
#上海市东方明珠的经纬度信息
{"status":0,"result":{"location":{"lng":121.5064701060957,"lat":31.245341811634675},"precise"
可右划查看
百度密钥申请方法:
http://jingyan.baidu.com/article/363872eccda8286e4aa16f4e.html
这样我就可以根据爬到的景点地址,查到对应的经纬度啦!python获取经纬度json数据的代码如下。
def getBaiduGeo(sightlist,name):
ak = '密钥'
headers = {
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
address = 地址
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
可右划查看
观察获取的 json 文件,location 中的数据和百度 API 所需要的 json 格式基本是一样,还需要将景点销量加入到 json 文件中,这里可以了解一下 json 的浅拷贝和深拷贝知识,最后将整理好的 json 文件输出到本地文件中。
def getBaiduGeo(sightlist,name):
ak = '密钥'
headers = {
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
list = sightlist
bjsonlist = []
ejsonlist1 = []
ejsonlist2 = []
num = 1
for l in list:
try:
try:
try:
address = l[6]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
address = l[0]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
address = l[2]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
continue
json_geo['count'] = l[4]/100
bjsonlist.append(json_geo)
ejson1 = {l[0] : [json_geo['lng'],json_geo['lat']]}
ejsonlist1 = dict(ejsonlist1,**ejson1)
ejson2 = {'name' : l[0],'value' : l[4]/100}
ejsonlist2.append(ejson2)
print '正在生成第' + str(num) + '个景点的经纬度'
num +=1
bjsonlist =json.dumps(bjsonlist)
ejsonlist1 = json.dumps(ejsonlist1,ensure_ascii=False)
ejsonlist2 = json.dumps(ejsonlist2,ensure_ascii=False)
with open('./points.json',"w") as f:
f.write(bjsonlist)
with open('./geoCoordMap.json',"w") as f:
f.write(ejsonlist1)
with open('./data.json',"w") as f:
f.write(ejsonlist2)
可右划查看
(╯' - ')╯┻━┻
在设置获取经纬度的地址时,为了匹配到更准确的经纬度,我选择了匹配景点地址,然而,景点地址里有各种神奇的地址,带括号解释在XX对面的,说一堆你应该左拐右拐各种拐就能到的,还有英文的……于是就有了第三章中复杂的去除信息(我终于圆回来了!)。
然而,就算去掉了复杂信息,还有一些匹配不到的景点地址,于是我使用了嵌套try,如果景点地址匹配不到;就匹配景点名称,如果景点名称匹配不到;就匹配景点所在区域,如果依然匹配不到,那我……那我就……那我就跳过ㄒ_ㄒ……身为一个景点,你怎么能,这么难找呢!不要你了!
这里生成的三个json文件,一个是给百度地图api引入用的,另俩个是给echarts引入用的。
将第二章中所述的百度地图api示例中的源代码复制到解释器中,添加密钥,保存为html文件,打开就可以看到和官网上一样的显示效果。echarts需要在实例页面,点击页面右上角的EN切换到英文版,然后点击download demo下载完整源代码。
根据html导入json文件修改网页源码,导入json文件。
#百度地图api示例代码中各位置修改部分
<head>
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.js">script>
head>
<script type="text/javascript">
$.getJSON("points.json", function(data){
var points = data;
script中原有函数;
});
script>
可右划查看
这里使用了jQuery之后,即使网页调试成功了,在本地打开也无法显示网页了,在chrome中右键检查,发现报错提示是需要在服务器上显示,可是,服务器是什么呢?

百度了一下,可以在本地创建一个服务器,在终端进入到html文件所在文件夹,输入python -m SimpleHTTPServer,再在浏览器中打开http://127.0.0.1:8000/,记得要将html文件名设置成index.html哦~

因为注册但没有认证开发者账号,所以每天只能获取6K个经纬度api(这是一个很好的偷懒理由),所以我选择了热门景点中前400页(每页15个)的景点,结果可想而知,为了调试因为数据增多出现的额外bug,最终的获取的景点数据大概在4500条左右(爬取时间为2017年09月10日,爬取关键词:热门景点,仅代表当时销量)。
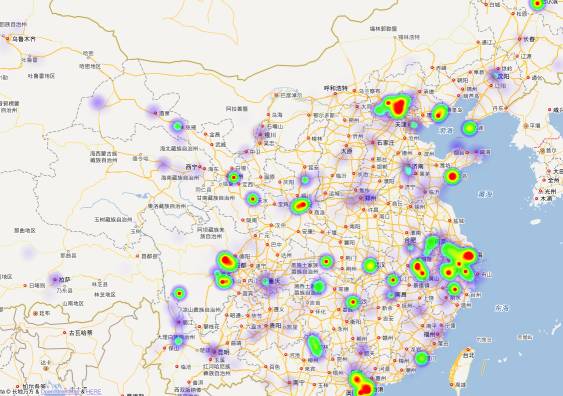
热门景点热力图
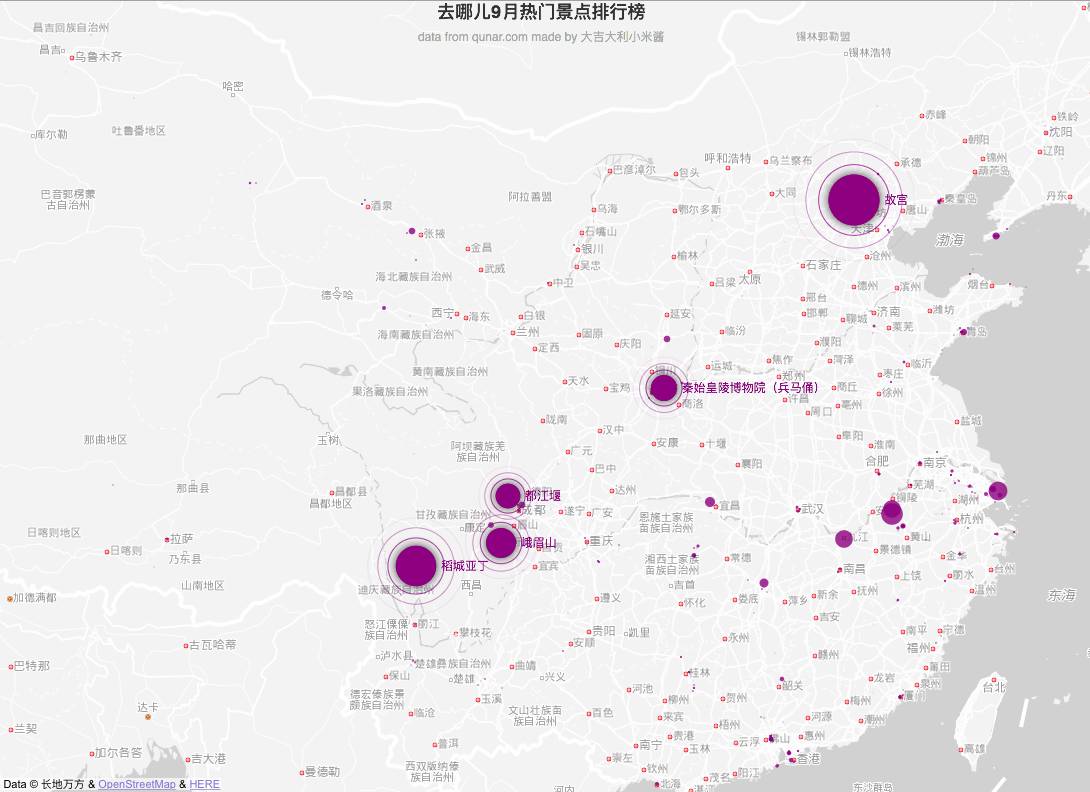
热门景点示意图
这些地图上很火爆的区域,我想在国庆大概是这样的

这样的

还有这样的

将地图上热门景点的销量top20提取出来,大多数都是耳熟能详的地点,北京的故宫排在了第一位,四川则占据了top5中的三位,在top20中也四川省就占了6位,如果不是因为地震,我想还会有更多的火爆的景点进入排行榜的~这样看来如果你这次国庆打算去四川的话,可以脑补到的场景就是:人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人……
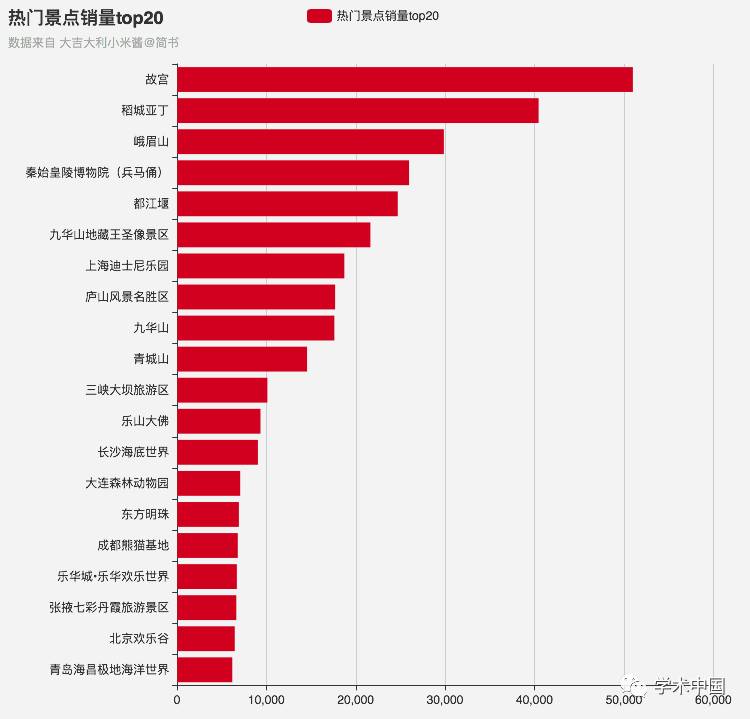
热门景点销量top20
于是我又做了一个各城市包含热门景点数目的排行,没想到在4千多个热门景点中,数目最多的竟是浙江,是第二个城市的1.5倍,而北京作为首都也……可以说是景点数/总面积的第一位了。
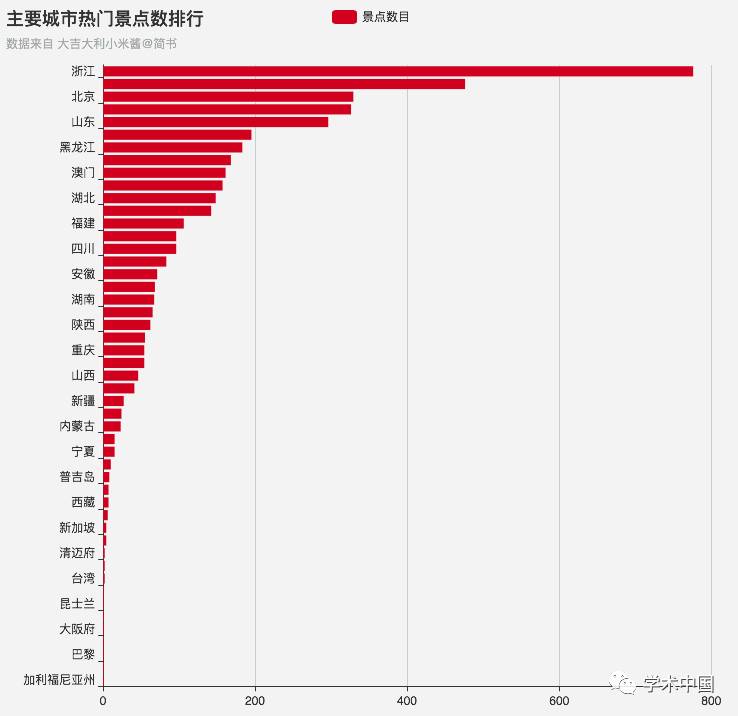
主要城市热门景点数
这些城市有那么多热门景点,都是些什么级别的景点呢?由下图看来,各城市的各级别景点基本与城市总热门景点呈正相关,而且主要由4A景区贡献而来。
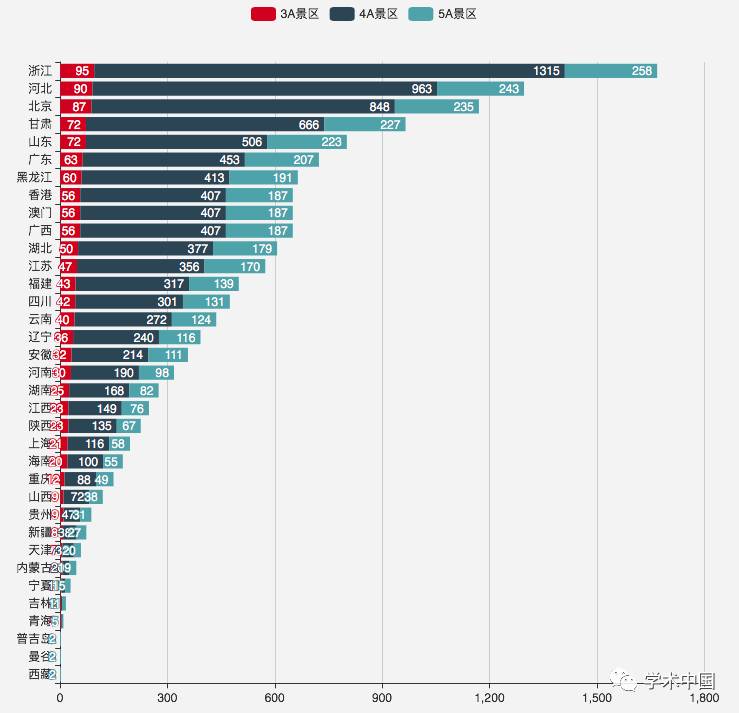
主要城市热门景点级别
既然去哪些地方人多,去哪里景多都已经知道了,那再看看去哪些地方烧得钱最多吧?下图是由各城市景点销售起步价的最大值-最小值扇形组成的圆,其中湖北以单景点销售起步价600占据首位,但也可以看到,湖北的景点销售均价并不高(在红色扇形中的藏蓝色线条)。而如果国庆去香港玩,请做好钱包减肥的心理和生理准备(≖ᴗ≖)✧。
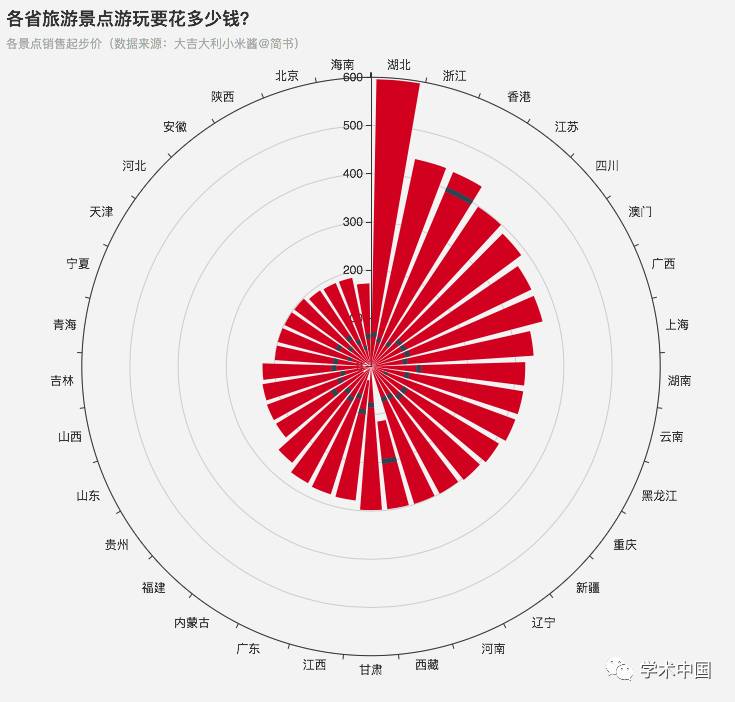
各省旅游景点销售起步价
好了,看完分析你知道既穷又懒的你怎么给自己找个理由窝家里了吧,知道下次给自己找理由的时候就要用数据说话了吧,知道数据是爬虫得来的了吧!
可是,还不会爬虫怎么办啊??
敲黑板!!学术中国第二季爬虫从入门到进阶工作坊10月20日在重庆举办,想要get第一手数据,快扫描二维码了解详情!

▲长按二维码查看详情
▷原文链接:
http://www.jianshu.com/p/b7627e67b6b9









