选自DeepMind
作者:Joel Leibo等人
机器之心编译
参与:朱思颖、蒋思源、李泽南
当人工智能超过人类之后,它们会选择消灭我们,还是与我们合作?谷歌旗下公司 DeepMind 的最新研究正在探讨这个问题。Joel Leibo 等人在本周四提交的论文中为我们描述了对不同奖励条件下人工智能/人类对竞争与合作的选择,这个问题的答案可能会影响到如何部署计算机智能来管理复杂的系统,如经济,城市交通与环境系统。

我们应用深度多代理强化学习(deep multi-agent reinforcement learning)的方式模拟了合作的出现。连续社会困境(sequential social dilemmas)这个新概念允许我们为理性智能体互动方式建模,并根据环境性质和人工智能认知能力多少促成一些合作。这项研究可以使我们更好理解和控制复杂的多人工智能系统行为,如经济,交通和环境等领域的各种挑战。
寻求自身利益的人们聚集在一起可以实现很多伟大的成就。为什么会是这样?最符合自己利益的策略会是只关注自己,而忽视他人利益的行动吗?
自私的个人如何、在什么情况下会趋向于合作的问题,是社会科学中的基本问题之一。描述这种现象的最简单和最优雅的模型之一就是著名的囚徒困境。
两名嫌疑犯都被逮捕并单独监禁。如没有任何一人供认,警方就没有足够的证据对两名嫌疑人的主要罪行定罪,但他们已经掌握的证据可为两名嫌疑人都判处一年徒刑。为了诱使囚犯承认,警察同时向两人提供以下选择:如果指证另一名囚犯(「叛变」),你将被释放,但另一个囚犯将服刑三年。如果两个囚犯互相指证(「叛变」),他们都将服刑两年。
事实证明,理性的智能体(agents)在博弈论的意义上是会在博弈过程中经常会选择叛变的,因为不论其他囚徒怎么选择,都会存在纳什均衡,而他们的最优决策就是选择叛变。然而,矛盾的是,如果两个囚徒都是理性人的情况下,他们每一个都会获得两年的囚禁,这要比他们一同狡辩或沉默多一年的囚禁。这种矛盾就是我们所说的社会困境(social dilemma)。
最近在人工智能,特别是深度强化学习方面的研究进展为我们提供了解决社会困境问题的新工具。传统的博弈论科学家是通过一个简单的二元选择合作或欺骗来为社会困境建模。而在现实生活中,合作和欺骗可能需要复杂的行为,因为它涉及到理性人需要学习执行任务的复杂行动序列。我们将这种新设置作为序列社会困境,并通过深层多代理强化学习(deep multi-agent reinforcement learning)训练的人工智能体来研究它。
举个例子,考虑如下采集博弈(Gathering game):两个理性智能体,红和蓝,他们漫游在一个共享世界,并收集苹果而获得正奖励。他们还能在另外一个智能体引导光线,「标记它」然后将它们暂时剔除出博弈,这是标记这一动作并不会触发奖励。下面可以从一个视频中了解智能体如何进行这一个采集博弈的。
我们让智能体重复这个博弈上千次,并通过深度多智能体的强化学习让这些智能体学习如何具有行为理性。当环境中有足够多的苹果时,智能体非常自然的学会了「和平共处」,力所能及的摘取尽可能多的苹果。然而,随着苹果数目的减少,智能体学到在这样情况下,更好的方法是标记其他智能体从而给自己时间来摘取数量有限的苹果。
这个苹果采集博弈中所表现出来的博弈特点,与最初的囚徒困境中的博弈特点有很多相通的地方,但这个采集博弈同时也给我们学习更有趣案例的机会。在这个博弈中,智能体需要学习自己理想行为:要么合作摘取苹果,要么尝试标记出其他智能体来形成对抗。
在这些连续社会困境中,现在可以学习哪些因素有助于智能体之间的合作。例如,下图中的点显示出在苹果采集博弈中,苹果越稀缺,智能体标记其他智能体的行为就越频繁。不仅如此,那些具备执行更复杂策略的智能体标记其他智能体的行为次数更多,例如,智能体的行为表现出更少的合作——无论我们怎么改变苹果的稀缺程度。
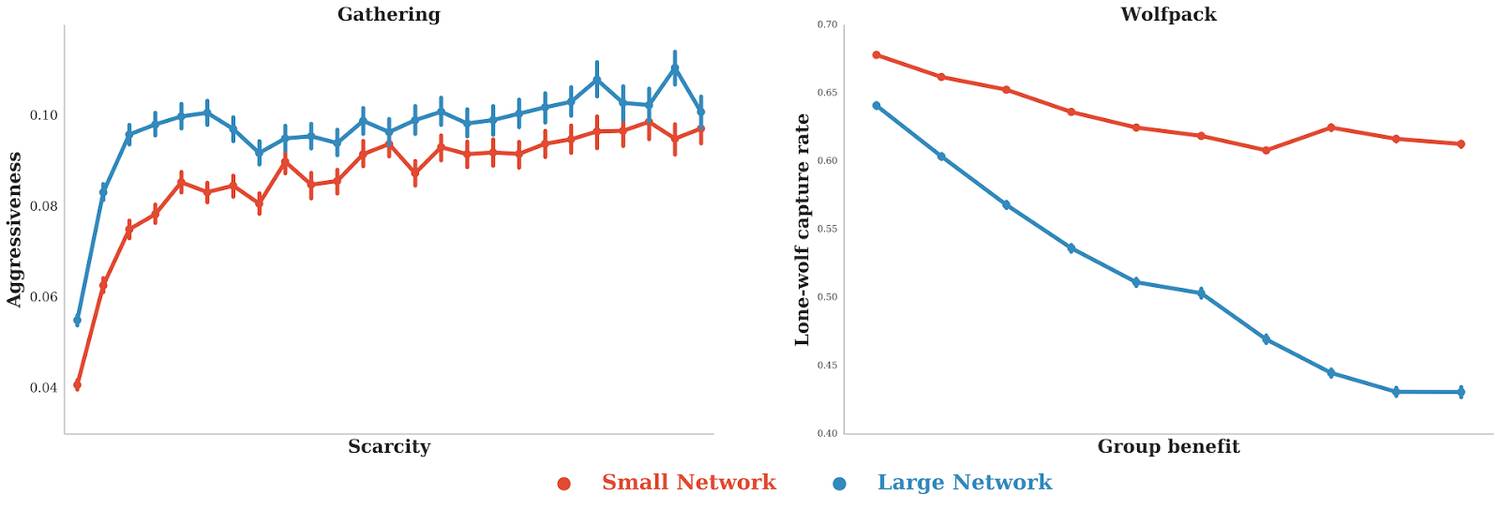
有趣的是,在另一个称为狼群模式(Wolfpack,详见下面视频)的博弈中,成功的合作需要更密切的配合,在这样的情形下,执行复杂策略能力越强,所促成智能体之间的合作也越多,智能体的这个表现与上面苹果摘取博弈中恰好相反。因此,依据博弈情形,复杂策略能力越强可能会促成智能体之间的更多合作,也可能会造成更少的合作。这个序列社交困境新框架不仅支持对交互结果的分析(正如囚徒困境的博弈过程),而且可以估测学习一个给定策略的困难度。
总结来说,我们的研究表明:可以将近期深度多智能体强化学习的人工智能技术应用于社会科学中的「古老」问题,例如,合作出现的神秘性。我们可以将所训练的人工智能智能体视为经济学理性智能体模型——理性经济人(homo economicus)的等价近似。因此,这样的模型赋予我们测试互动智能体(包括人以及人工智能智能体)所组成的仿造系统的特殊能力,可以测试在系统中设置不同的政策和调解方案将会产生何种结果。因此,我们能够更好的理解和控制复杂多智能体系统,如经济系统、交通系统、地球健康生态体系等所有依赖持续合作所构建的系统。
详细内容请查阅论文
论文:Multi-agent Reinforcement Learning in Sequential Social Dilemmas

摘要
如囚徒困境,几十年来,博弈矩阵(Matrix games)一直引导着社会困境(social dilemmas)的研究。然而,他们必须将合作或欺骗的选择作为不可分割的行动。而面临真实社会困境时,这些决策具有时间延展性(temporally extended)。协同性(Cooperativeness)只是适用于政策而不是用于每一个基本行动。我们引入了连续社会困境(sequential social dilemmas),其共享了社会困境博弈矩阵的混合激励架构,但同时也要求智能体学习实现其战略意图的政策。我们通过多个自利独立的(multiple self-interested independent)学习智能体分析了政策的动态过程,每一个智能体都有其自己的深度 Q 网络(deep Qnetwork)。在这里,我们介绍了两个马尔可夫博弈(Markov games):一个是水果收集博弈,另一个是群狼狩猎博弈。我们描述了学习行为在每一个领域中是怎样随着包括资源丰度(resource abundance)在内的环境因素变化而变化的。我们的实验表明,从共享资源的竞争中冲突是如何产生的,并阐明了现实世界社会困境的连续属性是如何影响合作的。
论文链接:https://storage.googleapis.com/deepmind-media/papers/multi-agent-rl-in-ssd.pdf
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]










