点击上方“StarryHeavensAbove”保持关注
↑先看新闻:
“SANTA CLARA, Calif., May 3, 2017 – VeriSilicon Holdings Co., Ltd. (VeriSilicon), a Silicon Platform as a Service (SiPaaS®) company, today announces VIP8000, a highly scalable and programmable processor for computer vision and artificial intelligence. It delivers over 3 Tera MACs per second, with power consumption more efficient than 1.5 GMAC/second/mW and the smallest silicon area in industry with 16FF process technology.”
“2017年5月4日,中国上海——楷登电子(美国Cadence公司,NASDAQ: CDNS)今日正式公布业界首款独立完整的神经网络DSP —Cadence® Tensilica® Vision C5 DSP,面向对神经网络计算能力有极高要求的视觉设备、雷达/光学雷达和融合传感器等应用量身优化。针对车载、监控安防、无人机和移动/可穿戴设备应用,Vision C5 DSP 1TMAC/s的计算能力完全能够胜任所有神经网络的计算任务。”
随着VeriSilicon和Cadence相继发布支持AI(神经网络)的DSP IP,加上CEVA和Synopsys,几家主流DSP IP厂商全部粉墨登场。之前的系列文章“处理器IP厂商的机器学习方案”中已经介绍了CEVA和Synopsys的方案。今天看看VeriSilicon和Cadence的方案吧。
•••
VeriSilicon推出的DSP IP编号为VIP8000,目前在其网站上还没有详细的介绍,只能从新闻稿中看看它的框图和主要的feature。
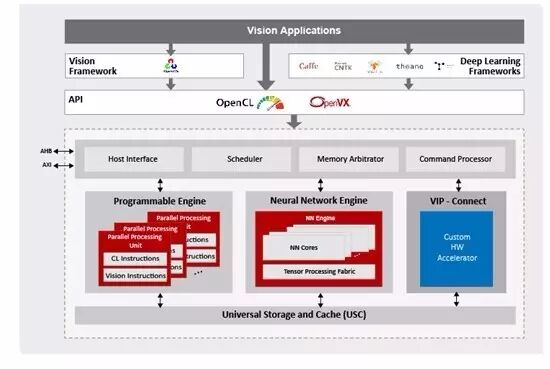
图片来自www.verisilicon.com
从新闻稿中可以看出,VIP8000不属于VeriSilicon之前的ZSP DSP系列,而是用了后来收购的Vivante的名字。“Vivante VIP8000由高度多线程的并行处理单元、神经网络单元和通用存储缓存单元组成”。从这段文字可以判断“Programmable Enginer”很有可能是基于Vivante的GPU,而不是类似CEVA的vector DSP。这是这个架构中最有趣的一点。
新闻稿中提到的VIP8000的重要feaure包括:
1. 在16nm FinFET工艺制程下,VIP8000可提供每秒超过3 Tera MACs的计算能力,能耗效率高于1.5 GMAC/秒/毫瓦,并且占用硅片面积是业内最小。
2. VIP8000可以直接导入由Caffe和TensorFlow等主流深度学习框架生成的神经网络,并可利用OpenVX框架将神经网络集成到其他计算机视觉功能模块中。它支持当前所有的主流神经网络模型(包括AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、Yolo、SSD、FCN和SegNet)和层类型(包括卷积和去卷积、扩张、FC、池化和去池化、各种规范化层和激活函数、张量重塑、逐元素运算、RNN和LSTM功能),旨在促进新型神经网络和新型层的采用。神经网络单元支持定点8位精度和浮点16位精度,并支持混合模式应用,以实现最佳计算效率和准确率。
3. Vivante VIP8000的VIP-Connect接口支持客户快速集成专用硬件加速单元,使之与标准的Vivante VIP8000硬件单元实现协同运作。
4. 该处理器由OpenCL或OpenVX进行编程,并在含客户专用硬件加速单元在内的硬件单元中采用统一的编程模型。所有硬件单元同时工作,共享缓存数据,可显著减少带宽。
5. 为了更好地服务于不同细分市场的嵌入式产品,Vivante VIP8000可以灵活配置,其并行处理单元、神经网络单元和通用存储单元分别具有可扩展性,且ACUITY SDK可提供培训和整套IDE工具。
第一条应该是VIP8000最大的亮点,但是新闻稿中的这种描述太过笼统,在看到更详细的分析和数据支持之前,基本无法评价,大家看看就好。其他的feature和工具基本已经是现在这类IP的标配了,也没太多新鲜的东西(似乎支持的NN类型要多一些)。工具什么的,如果不亲自用用,是无法知道有什么坑的。
•••
Cadence新闻稿的标题是这样的“Cadence Unveils Industry's First Neural Network DSP IP for Automotive, Surveillance, Drone and Mobile Markets”。我首先注意到的是First这个说法,之前CEVA和Synopsys都推的支持神经网络的DSP IP,这个“第一”从何而来呢。仔细一看,Cadence推出的Vision C5 DSP是专门针对神经网络处理的,而不是像之前的方案一样,用Vision DSP + NN Engine。从这个意义上来说,也可以说是第一个。
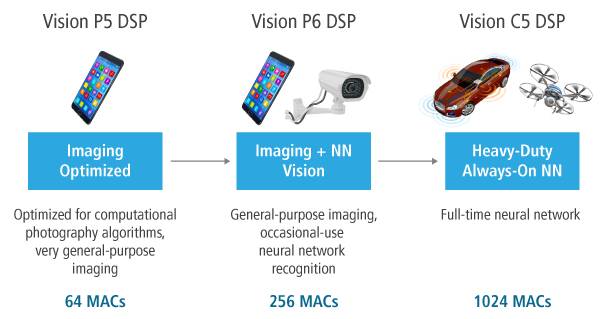
来自ip.cadence.com
从上图来看,Vision C5 DSP确实是专门针对NN的,“Heavy-Duty Always-On NN”。而传统的CV则由Vision P5/P6 DSP来完成。这也意味着未来使用Cadence方案的SoC,可能需要同时使用两个DSP,比如P6+C5,相较CEVA的Vision DSP + NN Engine紧耦合方案,其综合效果还有待考察。不过对不同的应用来说,这也是多了一种选择。
相对VeriSilicon而言,Cadence网站上对Vision C5 DSP已经有了较为详细的信息。下表就是P5,P6,C5 DSP核的一个对比。C5比较重要的指标是包括了1024个8 X 8的MAC(如果是16bit运算则是512个)。
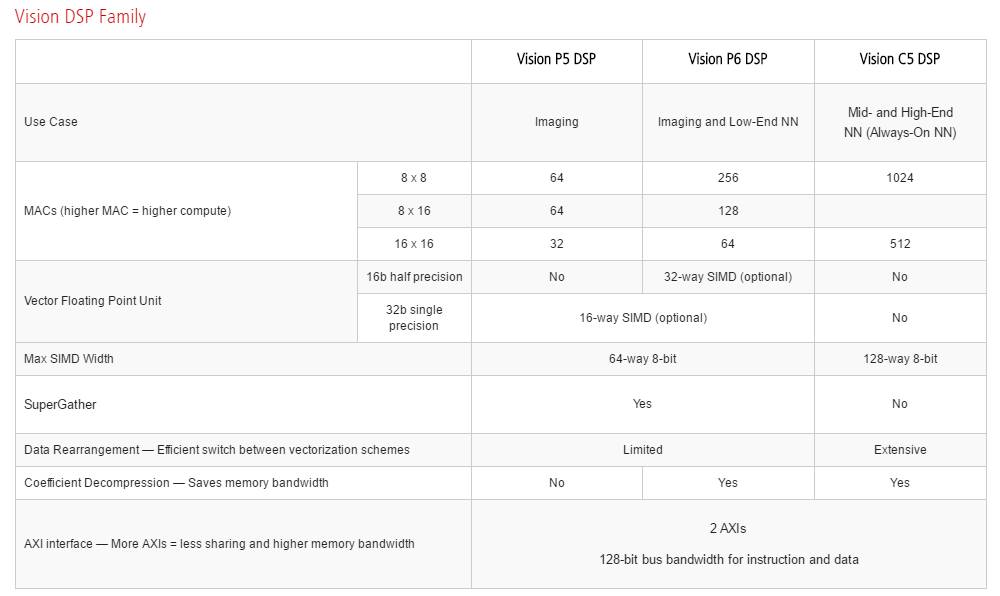
来自ip.cadence.com
C5 DSP的框图如下:
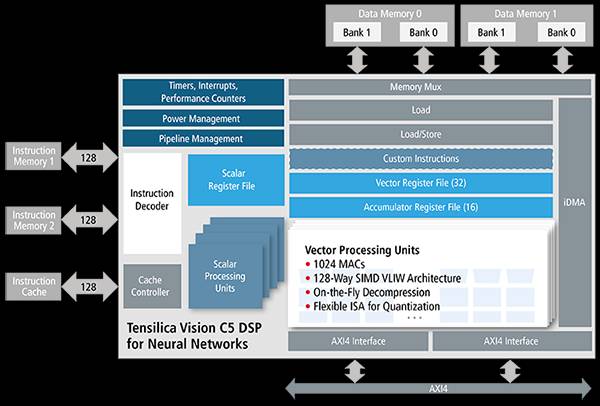
来自ip.cadence.com
而C5处理器具体的feature如下:
1. 不到1mm2的芯片面积可以实现1TMAC/秒的计算能力(吞吐量较Vision P6 DSP提高4倍),为深度学习内核提供极高的计算吞吐量
2. 1024 8-bit MAC或512 16-bit MAC 确保8-bit 和16-bit精度的出色性能
3. 128路8-bit SIMD或64路16-bit SIMD的VLIW SIMD架构
4. 专为多核设计打造,以极少的资源代价获得NxTMAC的处理能力
5. 内置iDMA和AXI4总线接口
6. 使用与Vision P5和P6 DSP一致的经验证软件工具包
7. 基于业界知名的AlexNet CNN Benchmark,Vision C5 DSP的计算速度较业界的GPU最快提高6倍;Inception V3 CNN benchmark,有9倍的性能提升。
1024个MAC和一些专用的NN加速器相比不算太多。从公开资料看,这个数字比CEVA和Synopsys的NN Engine要多一点。从框图来看,C5 DSP还是基于Cadence之前的DSP架构,而非专门设计的NN加速器,这种架构最后的实现效率如何还有待观察。
对于这些信息的分析,大家可以参考我之前的文章:处理器IP厂商的机器学习方案 - Synopsys和处理器IP厂商的机器学习方案 - CEVA。其中对如何看待这些DSP核的feature有比较详细的说明,这里就不再赘述了。
到目前为止,主要的DSP IP厂商都推出了自己的神经网络处理器方案(没算ARM这个IP大玩家)。新东西也好,老架构也罢,足见大家对这个方向的重视。两天内的新闻给我的感觉是,好戏刚刚开场,已经闻到了硝烟的味道。
T.S.
题图来自网络,版权归原作者所有
长按二维码关注










