
写在最前
程序是为人类服务的,最近正好身边小伙伴们在做球衣生意,当然是去nikenba专区购买了,可是有些热门球衣发布几分钟就被抢完,有些折扣球衣也是很快就被抢售一空,那么我们只能靠自己的眼睛一直盯着网站吗?NoNoNo,作为计算机专业的学生,怎么能为这种事情浪费时间呢?那肯定想法就是写爬虫自动比对价格啊,后来又在想,爬虫数据也是在PC端啊,该怎么实时提醒我们呢?再弄一个微信机器人发送数据不就可以了吗?说干就干,代码开撸
先看下效果:

准备工作:
首先本文使用py3,需要安装以下库:
1)itchat
2)requests
3)apscheduler
分析网页:
首先我们需要做什么?毫无疑问,分析网页,因为最重要的一步就是获取数据,那么如何获取数据就是我们首先要克服的困难
附上 nike nba专区地址:https://www.nike.com/cn/w/nba-sleeveless-and-tank-tops-18iwiz9sbux
首先我们要明确一个地方,我们的目的是实时监控热门打折球衣,所以我们的价格肯定首先降序排列,不过先不用着急,打开F12先看下调试器,对了我使用的是chrome浏览器

由于我们是先打开网页再打开调试窗口,所以目前我们看不到数据,别急,我们刷新一下再看
哦吼,完蛋,怎么这么多东西貌似根本没法看
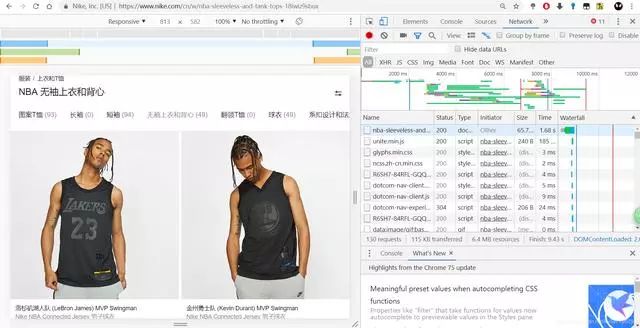
别急 继续分析,作为一个学(qiong)生(bi),我们肯定先关注价格了,当然要升序排列啊!
好的 点下浏览器调试窗口中的清除按钮(就是下面这个蓝色标记的按钮)先清除下调试台中的数据 然后呢我们点下筛选方式价格由低到高(红色标记的菜单键中选择)
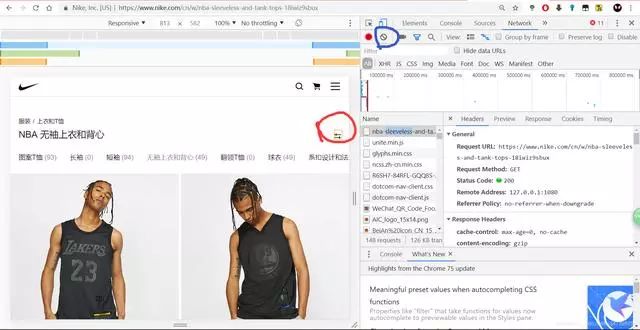
得到调试台如下,完蛋了还是一堆怎么办?
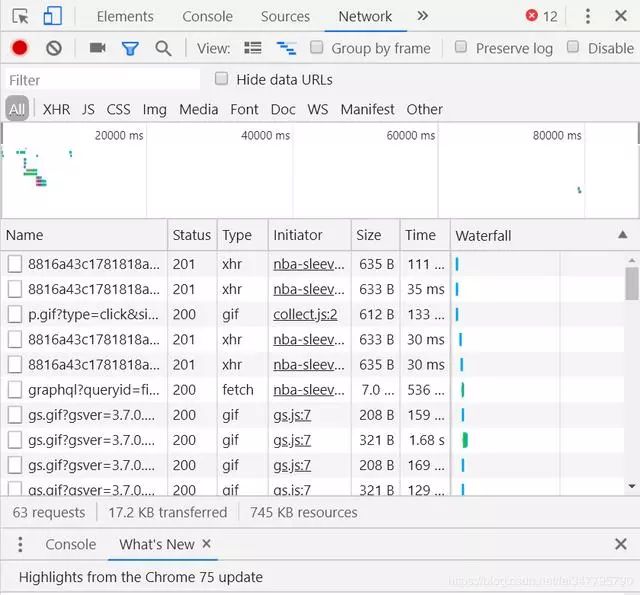
没关系,至少现在网页内容已经是按照价格升序排列了,我们再来看看得到的Network数据,挨个点一点看看,发现当点到名称为graphql开头的文件里去时候,有东西出现了
里面的响应内容出现了几个熟悉的队名称和球员名称甚至还有价格,等等,这不就是我们要的数据吗?
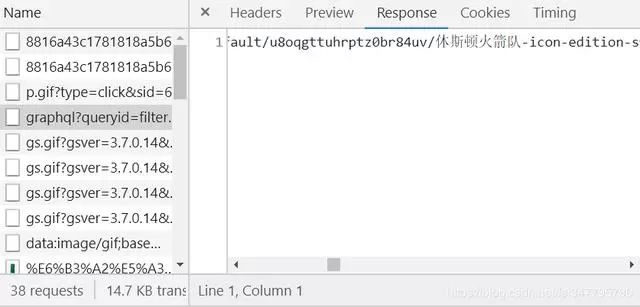
看来我们找对了地方,我们双击点开graphql开头的网页文件看看会有什么呢?。。。看起来杂乱无章,但是貌似确实是我们要的数据,是json格式的

在网页上看json简直是折磨,好的,我们用python开始把这个网页内容给弄下来仔细研究下
pycharm开搞
看看输出什么:

这样看起来好多了,好的 似乎到这里我们已经可以开始选取我们需要的数据进行记录了,但是我们又会注意到一点,这个网页的内容是瀑布流方式,也就是说滚轮往下滚动才会有更多的数据出现,可是我们目前只获取了这个页面最上端的数据,如果我们想获取更多的数据怎么办?
我们还是使用调试台,其实他页面只要变化,网站交互一定是有活动的,所以我们现在就观察当滚轮往下滚动到瀑布流下端时调试台会出现什么东西就可以了
往下滚动,发现调试台确实出现了很多新的文件,我们猜想这些文件中一定有瀑布流下端的数据,对了还记得我们刚才找到的文件名是什么吗?对的,是名称为graphql开头的文件,那么会不会新的数据文件也是这个名字开头的呢?我们使用调试台搜索下看看
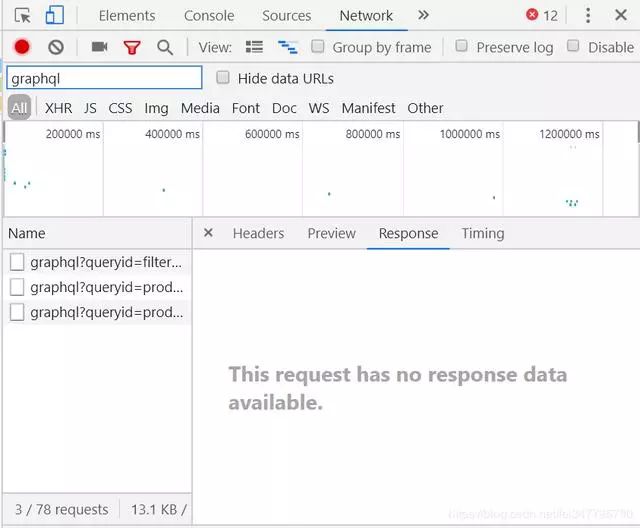
来了来了,它真的出现了,现在出现了3个文件都是graphql名字开头,毫无疑问第一个文件是我们上面找到的,那么第二个第三个呢?我们点开看看,会发现对应的商品名称之类的真的是瀑布流下端的数据。
OK看起来我们现在确实得到了所有数据文件的url
我最初的想法是直接将3个url写到一个列表中然后使用循环读取如下图(其实会发现第二个url与第三个看起来貌似一样啊怎么回事?下面有解释别急)
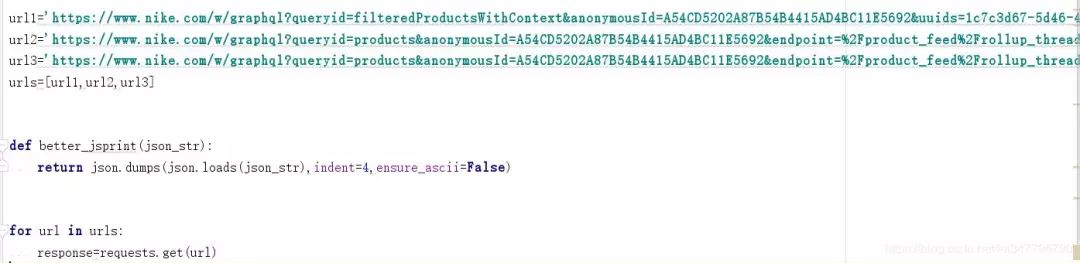
后来呢我突然意识到,万一商品更多了怎么办?会不会出现4个5个url?而总不能每次都靠人力去数有多少个url吧?然后就想,怎样才能让程序自动添加url呢?
我们再回头看看第一次抓取下来的 url1 的json数据,首先尝试下检索page这个关键词(毕竟一般程序员都会写这个作为页面标识吧?),哦霍,发现了了不得的东西,
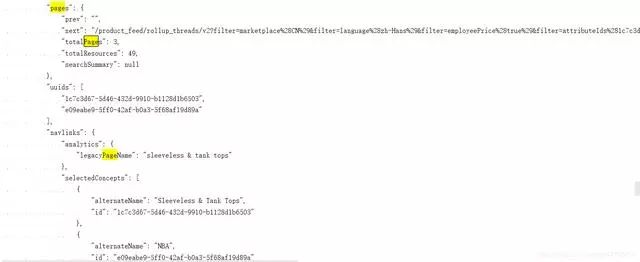
这些数据看起来很眼熟啊,还有uuids?再比对下第一次抓的 url1 发现里面的uuids还真的就是json里面的数据,那么又看到pages里面有个next 纳尼?这会不会是瀑布流下半部分url组成呢?快来比对 url2 地址
https://www.nike.com/w/graphql?queryid=products&anonymousId=A54CD5202A87B54B4415AD4BC11E5692&endpoint=%2Fproduct_feed%2Frollup_threads%2Fv2%3Ffilter%3Dmarketplace(CN)%26filter%3Dlanguage(zh-Hans)%26filter%3DemployeePrice(true)%26filter%3DattributeIds(1c7c3d67-5d46-432d-9910-b1128d1b6503%2Ce09eabe9-5ff0-42af-b0a3-5f68af19d89a)%26anchor%3D24%26count%3D24%26consumerChannelId%3Dd9a5bc42-4b9c-4976-858a-f159cf99c647%26sort%3DproductInfo.merchPrice.currentPriceAsc
尝试检索下next中的内容,发现真的存在与endpoint参数后面,哦霍 现在我们猜想,会不会每个json中都包含pages next这个数据
打印url2继续检索pages的next

真的存在,并且还存在prev参数(前一页),说明我们的猜想可能是正确的,这时候细心的小伙伴可能发现了 url2中的next内容与url1中一致啊,哦原来是这样,这样才导致了我们刚刚调试台中出现3个url文件但是第二个与第三个一样的情况
但是我们猜想第三个url返回数据中应该没有next否则就应该出现第四个文件了,我们来试一试
在url3返回数据中检索next

真的为空了所以我们可以确定,只要瀑布流下方仍有数据,那么一定存在next参数 因此我们可以确定瀑布流url写法 我们网页分析完成 接下来就要进行真正的代码编写了
(其实我有一个疑问 url2与url3看起来确实是一模一样的并且我尝试做了差值运算,发现还是一样的,但是返回数据确实不同,有大神可以发现这两个url不同之处吗 下面放上这两个url)
(url已改变,根据官网实时更新数据一直在变)











