选自BAIR
作者:Subhashini Venugopalan、Lisa Anne Hendricks
机器之心经授权编译
参与:路雪
现在的视觉描述只能描述现有的训练数据集中出现过的图像,且需要大量训练样本。近日,UC 伯克利提出一种新型视觉描述系统,无需成对的新物体图像和语句数据就可描述该物体。

给出一个图像,人类可以轻松推断出其中最明显的实体,并有效描述该场景,比如,物体所处地点(在森林里还是在厨房?)、物体具备什么属性(棕色还是白色?),以及更重要的一点:一个物体如何与其他物体互动(在地上跑,还是被一个人抓着等等)。视觉描述的任务旨在开发为图像中的物体生成语境描述的视觉系统。视觉描述正面临挑战,因为它不仅需要识别物体(熊),还要识别其他元素,如动作(站立)和属性(棕色),并构建一个流畅的句子来描述物体、动作和属性在图像中的关系(如一头棕熊站在森林里的一块岩石上)。
视觉描述的现状


以上为目前描述生成器(captioner)对两幅图片生成的描述。第一幅是训练数据中出现的物体(熊)图像,第二幅是模型在训练过程中未见过的物体(食蚁兽)图像。
当前的视觉描述或图像字幕生成模型效果已经很好,但是它们只能描述现有的图像字幕训练数据集中出现过的物体,且需要大量训练样本来生成好的描述。要学习如何在语境中描述类似「豺」或「食蚁兽」的物体,大多数视觉描述模型需要大量带有对应描述的豺或食蚁兽样本。但是,当前的视觉描述数据集,如 MSCOCO,不包含对所有物体的描述。与之相反的是,近期使用卷积神经网络(CNN)的目标识别工作能够识别出数百种类别的物体。尽管目标识别模型能够识别豺和食蚁兽,但是描述模型不能生成这些识别动物在语境中的准确描述语句。我们构建的视觉描述系统克服了这一难题,该系统无需成对的新物体图像和语句数据就可描述该物体。
任务:描述新物体
这里,我们正式地定义一下我们的任务。给定一个包含成对图像和描述(图像-句子对数据,如 MSCOCO)的数据集以及带有物体标签但没有描述的图像(非成对图像数据,如 ImageNet),我们希望能够学习如何描述在图像-句子对数据中未出现的物体。为此我们必须构建一个模型,该模型能够识别不同的视觉要素(如豺、棕色、站立和地面),并用新的方式将其组合成流畅的描述。以下是我们的描述模型的关键模块。
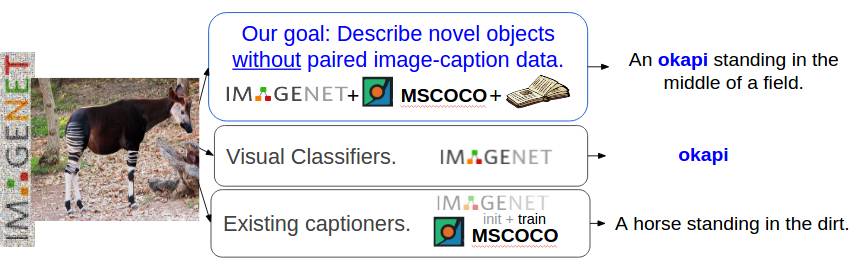
我们的目标是描述训练图像中的多种物体。
使用数据的外部资源
为了给图像-字幕训练数据之外的多种物体生成描述,我们利用了外部数据源。具体来说,我们使用带物体标签的 ImageNet 图像作为非成对图像的数据源,将没有标注的文本语料库(如 Wikipedia)中的句子作为我们的文本数据源。它们分别用于训练我们的视觉识别 CNN 和语言模型。

在外部资源上进行高效训练
捕捉语义相似度
我们希望能够描述在图像-句子对训练数据中未见过但与之类似的物体(如 ImageNet 中的物体)。我们使用密集词嵌入(dense word embedding)来达到该目的。词嵌入是词密集的高维表征,意义接近的词在嵌入空间中比较接近。在我们之前的工作「深度合成字幕(Deep Compositional Captioning,DCC)」[1] 中,我们首次在 MSCOCO 成对图像-字幕数据集上训练字幕模型。然后,为了描述新物体,我们对于每一个新物体(如霍加狓鹿)都使用词嵌入方法来确定一个在 MSCOCO 数据集所有物体中与新物体最相似的物体(在此案例中该物体是斑马)。之后,我们将该模型学得的参数从已见过的物体传输(复制)到未见过的物体(即将斑马对应的网络权重复制到霍加狓鹿)。
新物体字幕生成
DCC 模型能够描述多个未见过的物体类别,而将参数从一个物体复制到另一个物体可以创造符合语法的句子,如物体「网球拍」,模型从「网球」复制权重至「网球拍」,生成句子如「一个男人在球场打网球拍」。在我们近期的工作 [2] 中,我们直接将词嵌入纳入我们的语言模型。具体来说,我们在语言模型的输入和输出中使用 GloVe 嵌入。这使得该模型在描述未见过的物体时悄悄地捕捉语义相似度,进而生成句子,如「一个网球运动员挥舞球拍击球」。另外,直接将词嵌入纳入网络使我们的模型可以进行端到端的训练。
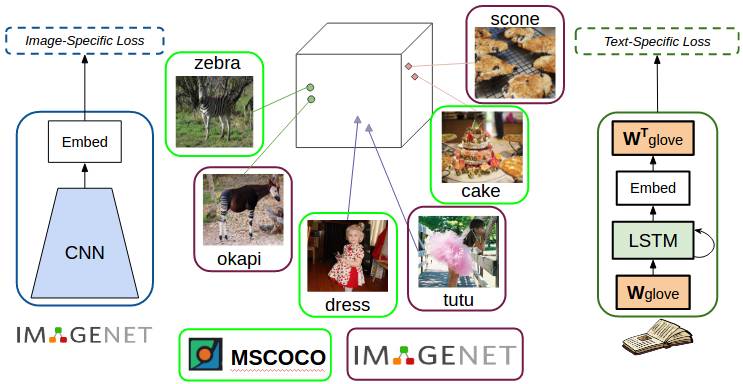
将密集词嵌入纳入语言模型以捕捉语义相似度。
字幕模型和神经网络中的遗忘问题
我们将视觉网络的和语言模型的输出与字幕模型联合起来。该模型与现有的 ImageNet 预训练字幕模型相似。但是,我们观察到尽管该模型在 ImageNet 上接受预训练,当该模型在 COCO 图像-字幕对数据集上进行训练/微调时,它倾向于遗忘之前见过的物体。蒙特利尔和 Google DeepMind 的研究者也观察到了神经网络中的遗忘问题。我们在研究中,使用联合训练策略可以解决遗忘问题。
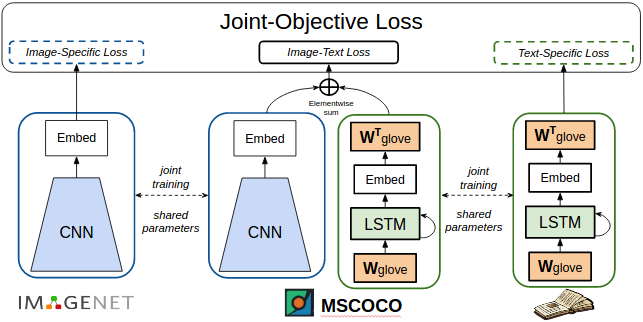
在不同的数据/任务上共享参数、联合训练,以克服「遗忘」问题
具体来说,我们的工作包含三个部分:一个视觉识别网络、一个字幕模型和一个语言模型。这三个部分共享参数,共同训练。在训练过程中,每一批输入包含部分带标注的图像、一系列图像-描述对,以及部分句子。这三种输入训练网络的三个部分。由于三个部分共享参数,所以该网络接受联合训练,以识别图像中的物体、生成图像字幕和句子。联合训练帮助该网络克服遗忘问题,使模型能够对很多新的物体类别生成描述。
未来会怎样?
我们的模型中最常见的一个错误是无法识别物体,一种缓解方式是使用更好的视觉特征。另一个常见错误是生成的句子不够流畅(A cat and a cat on a bed)或不符合「常识」(如:「A woman is playing gymnastics」不完全正确,因为一个人无法「play」gymnastics,动词搭配不当)。提出这些问题的解决办法应该会很有趣。尽管我们在该研究中提出把联合训练作为克服遗忘问题的策略,但是在大量不同任务和数据集上训练模型并不总能够实现。另一种解决方法是构建一个基于视觉信息和物体标签生成描述的模型。这样的模型还能够在计算机运行中集成物体,即当我们在选中的物体集合上对模型进行预训练时,我们还应该思考如何渐进地在具备新概念的新数据上训练模型。解决这些问题可以帮助研究者开发出更好、更鲁棒的视觉描述模型。

原文地址:http://bair.berkeley.edu/blog/2017/08/08/novel-object-captioning/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]










