
人类自诞生以来就伴随着各种信息的生产和获取,如今这个信息爆炸的 DT 时代,人们更是被各种信息所包围。我们知道,人获取信息的方式主要有被动获取和主动获取两种,其中被动获取就是推荐的方式、主动获取就是搜索的方式。
获取信息是人类认知世界、生存发展的刚需,搜索就是最明确的一种方式,其体现的动作就是“出去找”,找食物、找地点等,到了互联网时代,搜索引擎(Search
Engine)就是满足找信息这个需求的最好工具,你输入想要找的内容(即在搜索框里输入查询词,或称为
Query),搜索引擎快速的给你最好的结果,这样的刚需催生了谷歌、百度这样的互联网巨头。
此次结合达观数据在垂直搜索引擎建设方面的经验,围绕以下内容进行展开:
-
用户搜索意图的理解及其难点解析
-
如何识别用户搜索意图
-
达观数据用户搜索意图理解引擎介绍
首先,从偏技术的角度来看看搜索引擎发展的几个阶段:
第一个阶段,使用倒排索引解决匹配的效率问题,使用文档模型解决基本的相关性,使搜索引擎变得可用、可扩展,代表比如 Infoseek 。但这一阶段只保证了基本的文字相关性,搜索的真正效果是无法保证的。
第二个阶段,使用超链模型,比如谷歌的 pagerank 和百度的超链分析。解决权威性问题,使搜索质量提升一个档次。从这一阶段搜索引擎开始快速普及与并进入商业化,为谷歌和百度这样的公司带来了丰厚的利润。
第三个阶段,一方面使用更复杂的规则和机器学习排序模型,综合考虑了用户的行为特征,如商品评论、点赞、收藏、购买等,使得搜索引擎的结果再次提升一个档次,这些在电商等垂直搜索上表现的会更加明显;另一方面,基于各种先进的自然语言处理技术,充分挖掘用户搜索行为日志,对
query 进行分析改写以召回更多更好的结果。
第四个阶段,从“有框”搜索时代步入更加人工智能的“无框”搜索时代。人机交互方式也将更多的是问答式的自然语言加语音的方式,而搜索引擎也更像一个智能机器人,理解人的自然语言问题,提供更加直接有效的知识和答案。这一阶段目前尚处于起步阶段,谷歌、Amazon
以及一些优秀的创业公司都在进行积极的探索。
搜索引擎涉及的技术非常繁复,既有工程架构方面的,又有算法策略方面的。综合来讲,一个搜索引擎的技术构建主要包含三大部分:
-
对 query 的理解;
-
对内容(文档)的理解;
-
对 query 和内容(文档)的匹配和排序。
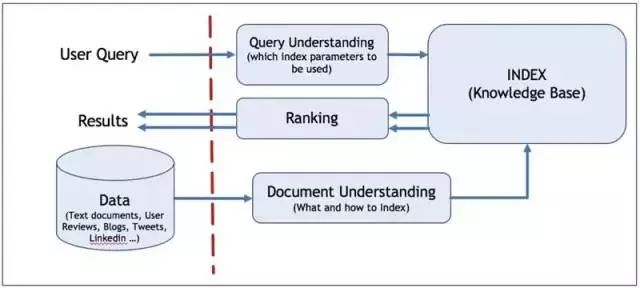
本片文章主要探讨其中的 Query Understanding,即对 query 的理解。
对 query 的理解, 换句话说就是对用户搜索意图的理解。先看垂直搜索中的一些例子:
“附近的特价酒店”
“上海到扬州高速怎么走”
“小龙虾最新报价”
“华为最新款手机”
“水”
这几个例子都不能直接根据 query 的字面意思去搜索,而是要理解用户输入文字背后的真实意图。不过要准确理解 query 背后的用户搜索意图可不是那么容易的。
我们来分析一下理解用户搜索词背后的真实意图识别存在哪些难点:
-
用户输入不规范,输入方式多样化,使用自然语言查询,甚至非标准的自然语言。比如上面提到的“附近的特价酒店” 、“上海到扬州高速怎么走”都是自然语言查询的例子,又如 “披星 ( ) 月”、“吾尝终日而思矣, 下面“
。
-
用户的查询词表现出多意图,比如用户搜索“变形金刚”,是指变形金刚的电影还是游戏? 搜索“仙剑奇侠传”是指游戏还是游戏软件? 电影? 小说? 电商网站搜索“水”是指矿泉水?还是女生用的护肤水?
-
意图强度,表现为不同用户对相同的查询有不同的需求强度。比如:宫保鸡丁。宫保鸡丁菜,菜谱需求占
90%。宫保鸡丁歌曲,歌曲下载需求占 10%。又比如:荷塘月色。荷塘月色歌曲,歌曲下载需求占 70%。荷塘月色小区,房产需求占
20%。荷塘月色菜,菜谱需求占 10%。
-
意图存在时效性变化,就是随着时间的推移一些查询词的意图会发生变化。比如:华为
P10 国行版 3 月 24 日上市。3 月 21 日的查询意图:新闻 90%,百科 10%3 月 24 日的查询意图:新闻 70%,购买
25%,百科 5%5 月 1 日的查询意图:购买 50%,资讯 40%,其他 10%5 年以后的查询意图:百科 100%。
-
数据冷启动的问题,用户行为数据较少时,很难准确获取用户的搜索意图。
-
没有固定的评估的标准,CTR、MAP、MRR、nDCG 这些可以量化的指标主要是针对搜索引擎的整体效果的,具体到用户意图的预测上并没有标准的指标。
首先我们来看一下用户搜索意图有哪些分类。一般把搜索意图归类为 3 种类型:导航类、信息类和事务类。雅虎的研究人员在此基础上做了细化,将用户搜索意图划分如下类别:
-
直接型:用户想知道关于一个话题某个方面明确的信息,比如“地球为什么是圆的”、“哪些水果维生素含量高”。
-
间接型:用户想了解关于某个话题的任意方面的信息,比如粉丝搜索“黄晓明”。
-
建议型:用户希望能够搜索到一些建议、意见或者某方面的指导,比如“如何选股票”。
-
定位型:用户希望了解在现实生活中哪里可以找到某些产品或服务,比如“汽车维修”。
-
列表型:用户希望找到一批能够满足需求的信息,比如“陆家嘴附近的酒店”。
-
下载型:希望从网络某个地方下载想要的产品或者服务,比如“USB 驱动下载”。
-
娱乐型:用户出于消遣的目的希望获得一些有关信息,比如“益智小游戏”
-
交互型:用户希望使用某个软件或服务提供的结果,用户希望找到一个网站,这个网站上可以直接计算房贷利息。
-
获取型:用户希望获取一种资源,这种资源的使用场合不限于电脑,比如“麦当劳优惠券”,用户希望搜到某个产品的折扣券,打印后在现实生活中使用。
查询意图理解的过程就是结合用户历史行为数据对 query 进行各种分析处理的过程,包括查询纠错、查询词自动提示、查询扩展,查询自动分类、语义标签等。
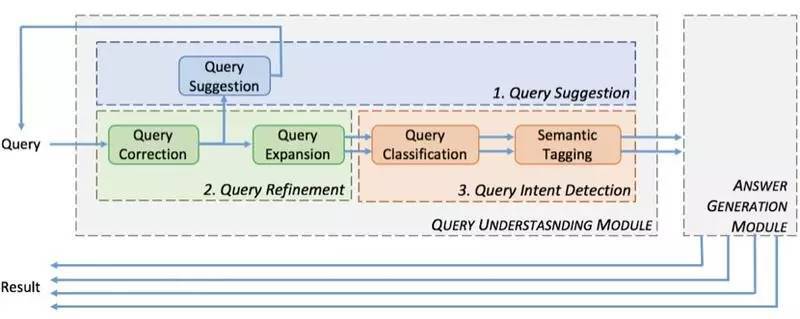
上面这张图是一个具体的例子说明 query understanding 的工作过程:
稍微解释一下这张图:
-
用户的原始 query 是 “michal jrdan”
-
Query Correction 模块进行拼写纠错后的结果为:“Michael Jordan”
-
Query Suggestion 模块进行下拉提示的结果为:“Michael Jordan berkley”和 “Michael Jordan NBA”,假设用户选择了“Michael Jordan berkley”
-
Query Expansion 模型进行查询扩展后的结果为:“Michael Jordan berkley”和 “Michael I. Jordan berkley”
-
Query Classification 模块进行查询分类的结果为:academic
-
最后语义标签(Semantic Tagging)模块进行命名实体识别、属性识别后的结果为:[Michael Jordan: 人名][berkley:location]:academic
下面我们逐一的来看看这面这些模块内部细节。
首先看一下 Query Correction 模块,也即查询纠错模块。
对于英文,最基本的语义元素是单词,因此拼写错误主要分为两种:一种是
Non-word Error,指单词本身就是拼错的,比如将“happy”拼成“hbppy”,“hbppy”本身不是一个词。另外一种是
Real-word Error,指单词虽拼写正确但是结合上下文语境确是错误的,比如“two eyes”写成“too
eyes”,“too”在这里是明显错误的拼写。
而对于中文,最小的语义单元是字,往往不会出现错字的情况,因为现在每个汉字几乎都是通过输入法输入设备,不像手写汉字也许会出错。虽然汉字可以单字成词,但是两个或以上的汉字组合成的词却是更常见的语义元素,这种组合带来了类似英文的
Non-word Error,比如“大数据”写成“大树据”,虽然每个字是对的,但是整体却不是一个词,也就是所谓的别字。
query 纠错的具体方案有
:
-
基于编辑距离
-
基于噪声信道模型
1. 编辑距离的方法
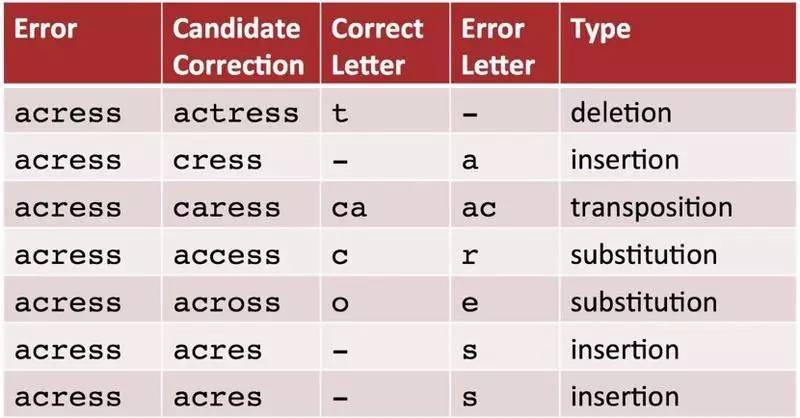
编辑距离包括删除(del)、增加(ins)、替换(sub)和颠倒(trans)四种转移操作,对应四种转移矩阵。这些转移矩阵的概率可以通过对语料库统计大量的正确词和错误词对来得到。

中文词语的编辑距离转换存在较大的转义风险。比如,雷锋 ->雷峰塔。中文纠错通常以拼音为基础,编辑距离等其他方式为辅的策略。










