昨晚见到大神
Aurélien Géron
真人讲 Tensorflow 2.0 的 autograph,会后和他聊天得知他已经搬到新加坡了,而且在这边也有一个 AI consulting 的初创公司。大神非常谦逊,讲东西一针见血,现在在忙于他的经典书《
Hands-On Machine Learning with Scikit-Learn and TensorFlow
》的第二版,里面加了很多 Tensorflow 2.0 的新东西。他的书和 youtube 上的几个视屏都是精品,我自认为写的最好的文章「
胶囊网络
」是受他的那个 capsule network 的视屏的启发而作。
大神的事业已经非常成功,问他写书的动力在哪 (因为我自己也写,深知要牺牲很多个人时间),他很简单地说他就喜欢一直学习,通过写书可以明晰自己的对知识的理解,通过亲自写代码可以一直紧跟那些深度学习框架的发展。大神博学、谦逊、讲东西接地气,值得我学习,献上我和他合照一张 :)

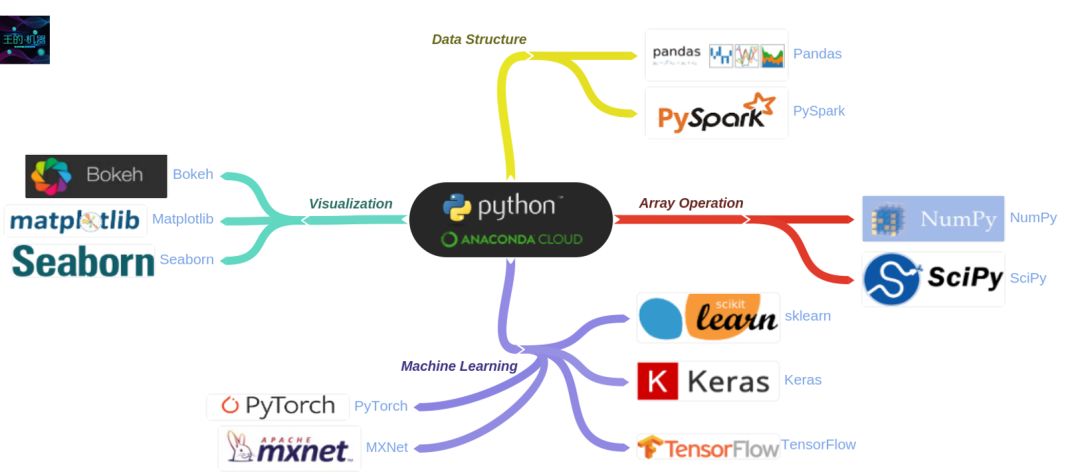
微信公众号终于可以插代码了,Python 可以走一波了。首先我承认不是硬核搞 IT 的,太高级的玩法也玩不来,讲讲下面基本的还可以,之后带点机器学习、金融工程和量化投资的实例也是可以。
-
Python 入门篇 (上)
-
Python 入门篇 (下)
-
数组计算之 NumPy
-
科学计算之 SciPy
-
数据结构之 Pandas
-
基本可视化之 Matplotlib
-
统计可视化之 Seaborn
-
交互可视化之 Bokeh
-
炫酷可视化之 PyEcharts
-
机器学习之 Sklearn
-
深度学习之 TensorFlow
-
深度学习之 Keras
-
深度学习之 PyTorch
-
深度学习之 MXnet
整个系列力求精简和实用 (可能不会完整,但看完此贴举一反三也不要完整,追求完整的建议去看书),到了「难点处」我一定会画图帮助读者理解。Python 系列的入门篇的目录如下,本帖是上篇,只涵盖前
三个节
,下篇接着后两节。

对于任何一种计算机语言,我觉得最重要的就是「数据类型」「条件语句 & 迭代循环」和「函数」,这三方面一定要打牢基础。此外 Python 非常简洁,一行代码 (one-liner) 就能做很多事情,很多时候都用了各种「解析式」,比如列表、字典和集合解析式。
在学习本贴前感受一下这个问题:
如何把以下这个不规则的列表 a 里的所有元素一个个写好,专业术语叫打平 (flatten)?
a = [1, 2, [3, 4], [[5, 6], [7, 8]]]
魔法来了 (这一行代码有些长,用手机的建议横屏看)
fn = lambda x: [y for l in x for y in fn(l)] if type(x) is list else [x]fn(a)
这一行代码,用到了迭代、匿名函数、递推函数、解析式这些技巧。初学者一看只会说“
好酷啊,但看不懂
”,看完本帖和下帖后,我保证你会说“
我也会这样用了,真酷!
”
Python 里面有自己的内置数据类型 (build-in data type),本节介绍基本的三种,分别是整型 (int),浮点型 (float),和布尔型 (bool)。
整数 (integer) 是最简单的数据类型,和下面浮点数的区别就是前者小数点后没有值,后者小数点后有值。例子如下:
a = 1031print( a, type(a) )
通过
print
的可看出 a 的值,以及类 (class) 是
int
。Python 里面
万物皆对象
(object),「整数」也不例外,只要是对象,就有相应的属性 (attributes) 和方法 (methods)。
通过
dir( X )
和
help( X )
可看出 X 对应的对象里可用的属性和方法。
等等
['__abs__',
'__add__',
...
'__xor__',
'bit_length',
'conjugate',
...
'real',
'to_bytes']
红色
的是 int 对象的可用方法,
蓝色
的是 int 对象的可用属性。对他们你有个大概印象就可以了,具体怎么用,需要哪些参数 (argument),你还需要查文档。看个
bit_length
的例子
该函数是找到一个整数的二进制表示,再返回其长度。在本例中 a = 1031, 其二进制表示为 ‘10000000111’ ,长度为 11。
简单来说,浮点型 (float) 数就是实数, 例子如下:
print( 1, type(1) )print( 1., type(1.) )
1 <class 'int'>
1.0 <class 'float'>
加一个小数点
.
就可以创建 float,不能再简单。有时候我们想保留浮点型的小数点后 n 位。可以用 decimal 包里的 Decimal 对象和 getcontext() 方法来实现。
import decimalfrom decimal import Decimal
Python 里面有很多用途广泛的包 (package),用什么你就引进 (import) 什么。包也是对象,也可以用上面提到的
dir(decimal)
来看其
属性
和
方法
。比如 getcontext() 显示了 Decimal 对象的默认精度值是 28 位 (prec=28),展示如下:
Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999,
Emax=999999, capitals=1, clamp=0, flags=[],
traps=[InvalidOperation, DivisionByZero, Overflow])
让我们看看 1/3 的保留 28 位长什么样?
d = Decimal(1) / Decimal(3)d
Decimal
('0.3333333333333333333333333333')
那保留 4 位呢?用 getcontext().prec 来调整精度哦。
decimal.getcontext().prec = 4 e = Decimal(1) / Decimal(3)e
高精度的 float 加上低精度的 float,保持了高精度,没毛病。
Decimal('0.6666333333333333333333333333')
布尔 (boolean) 型变量只能取两个值,
True
和
False
。当把布尔变量用在数字运算中,用 1 和 0 代表
True
和
False
。
T = TrueF = Falseprint( T + 2 )print( F - 8 )
除了直接给变量赋值
True
和
False
,还可以用 bool(
X
) 来创建变量,其中
X
可以是
-
基本类型:整型、浮点型、布尔型
-
容器类型:字符、元组、列表、字典和集合
print( type(0), bool(0), bool(1) )print( type(10.31), bool(0.00), bool(10.31) )print( type(True), bool(False), bool(True) )
<class 'int'> False True
<class 'float'> False True
<class 'bool'> False True
bool 作用在基本类型变量的总结
:X 只要不是整型 0、浮点型 0.0,bool(X) 就是
True
,其余就是
False
。
print( type(''), bool( '' ), bool( 'python' ) )print( type(()), bool( () ), bool( (10,) ) )print( type([]), bool( [] ), bool( [1,2] ) )print( type({}), bool( {} ), bool( {'a':1, 'b':2} ) )print( type(set()), bool( set() ), bool( {1,2} ) )
<class 'str'> False True
<class 'tuple'> False True
<class 'list'> False True
<class 'dict'> False True
<class 'set'> False True
bool 作用在容器类型变量的总结
:
X 只要不是空的变量,bool(X) 就是
True
,其余就是
False
。
确定
bool(X)
的值是
True
还是
False
,就看 X 是不是空,空的话就是
False
,不空的话就是
True
。
-
对于数值变量,0, 0.0 都可认为是空的。
-
对于容器变量,里面没元素就是空的。
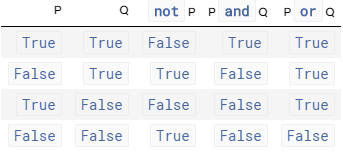
此外两个布尔变量 P 和 Q 的逻辑运算的结果总结如下表:
上节介绍的整型、浮点型和布尔型都可以看成是单独数据,而这些数据都可以放在一个容器里得到一个「容器类型」的数据,比如:
字符用于处理文本 (text) 数据,用「单引号 ’」和「双引号 “」来定义都可以。
t1 = 'i love Python!'print( t1, type(t1) )t2 = "I love Python!"print( t2, type(t2) )
i love Python! <class 'str'>
I love Python! <class 'str'>
字符中常见的内置方法 (可以用
dir(str)
来查) 有
print( t1.find('love') )print( t1.find('like') )
t2.replace( 'love Python', 'hate R' )
print( 'http://www.python.org'.strip('htp:/') )print( 'http://www.python.org'.strip('.org') )
www.python.org
http://www.python
s = 'Python'print( s )print( s[2:4] )print( s[-5:-2] )print( s[2] )print( s[-1] )
Python 里面索引有三个特点 (经常让人困惑):
-
从 0 开始 (和 C 一样),不像 Matlab 从 1 开始。
-
切片通常写成 start:end 这种形式,
包括
「start 索引」对应的元素,
不包括
「end索引」对应的元素。因此 s[2:4] 只获取字符串第 3 个到第 4 个元素。
-
索引值可正可负,正索引从 0 开始,从左往右;负索引从 -1 开始,从右往左。使用负数索引时,会从最后一个元素开始计数。最后一个元素的位置编号是 -1。
这些特点引起读者对切片得到什么样的元素感到困惑。有个小窍门可以帮助大家快速锁定切片的元素,如下图。
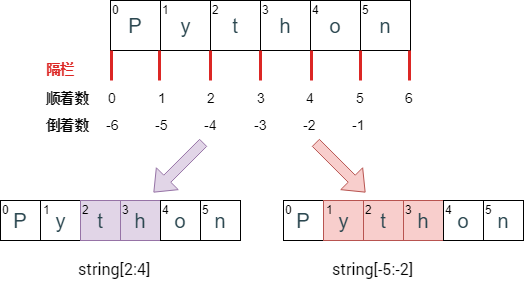
与其把注意力放在元素对应的索引,不如想象将元素分开的隔栏,显然 6 个元素需要 7 个隔栏,隔栏索引也是从 0 开始,这样再看到 start:end 就认为是隔栏索引,那么获取的元素就是
「隔栏 start」和
「隔栏 end」之间包含的元素。如上图:
正则表达式 (regular expression) 主要用于识别字符串中
符合某种模式
的部分,什么叫模式呢?用下面一个具体例子来讲解。
input = """'06/18/2019 13:00:00', 100, '1st';'06/18/2019 13:30:00', 110, '2nd';'06/18/2019 14:00:00', 120, '3rd'"""input
"\n'06/18/2019 13:00:00', 100, '1st';
\n'06/18/2019 13:30:00', 110, '2nd';
\n'06/18/2019 14:00:00', 120, '3rd'\n"
假如你想把上面字符串中的「时间」的模式来抽象的表示出来,对照着具体表达式
'
06
/
18
/
2019
13
:
00
:
00
'
来看,我们发现该字符串有以下规则:
-
开头和结束都有个
单引号 '
-
里面有多个
0-9
数字
-
里面有多个
正斜线 /
和
分号 :
-
还有一个空格
因此我们用下面这样的模式
pattern = re.compile("'[0-9/:\s]+'")
再看这个抽象模式表达式
'
[
0-9
/
:
\s]+
'
,里面符号的意思如下:
有了模式 pattern,我们来看看是否能把字符串中所有符合 pattern 的日期表达式都找出来。
["'06/18/2019 13:00:00'",
"'06/18/2019 13:30:00'",
"'06/18/2019 14:00:00'"]
结果是对的,之后你想怎么盘它就是你自己的事了,比如把 / 换成 -,比如用 datetime 里面的 striptime() 把日期里年、月、日、小时、分钟和秒都获取出来。
「元组」定义语法为
(
元素1
,
元素2
,
...
,
元素n
)
关键点是「
小括号 ()
」和「
逗号 ,
」
-
小括号
把所有元素绑在一起
-
逗号
将每个元素一一分开
创建元组的例子如下:
t1 = (1, 10.31, 'python')t2 = 1, 10.31, 'python'print( t1, type(t1) )print( t2, type(t2) )
(1, 10.31, 'python') <class 'tuple'>
(1, 10.31, 'python') <class 'tuple'>
创建元组可以用小括号 (),也可以什么都不用,为了可读性,建议还是用 ()。此外对于含
单个元素
的元组,务必记住要
多加一个逗号
,举例如下:
print( type( ('OK') ) ) # 没有逗号 , print( type( ('OK',) ) ) # 有逗号 ,
<class 'str'>
<class 'tuple'>
看看,没加逗号来创建含单元素的元组,Python 认为它是字符。
当然也可以创建二维元组:
nested = (1, 10.31, 'python'), ('data', 11)nested
((1, 10.31, 'python'), ('data', 11))
元组中可以用整数来对它进行索引 (indexing) 和切片 (slicing),不严谨的讲,前者是获取单个元素,后者是获取一组元素。接着上面二维元组的例子,先看看索引的代码:
nested[0]print( nested[0][0], nested[0][1], nested[0][2] )
(1, 10.31, 'python')
1 10.31 python
再看看切片的代码:
元组有不可更改 (immutable) 的性质,因此不能直接给元组的元素赋值,例子如下 (注意「元组不支持元素赋值」的报错提示)。
t = ('OK', [1, 2], True)t[2] = False
TypeError: 'tuple' object does not support item assignment
但是只要元组中的元素可更改 (mutable),那么我们可以直接更改其元素,
注意这跟赋值其元素不同
。如下例 t[1] 是列表,其内容可以更改,因此用 append 在列表后加一个值没问题。
元组大小和内容都不可更改,因此只有 count 和 index 两种方法。
t = (1, 10.31, 'python')print( t.count('python') )print( t.index(10.31) )
这两个方法返回值都是 1,但意思完全不同
元组拼接 (concatenate) 有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
(1, 10.31, 'python') + ('data', 11) + ('OK',)(1, 10.31, 'python') * 2
(1, 10.31, 'python', 'data', 11, 'OK')
(1, 10.31, 'python', 1, 10.31, 'python')
解压 (unpack) 一维元组 (有几个元素左边括号定义几个变量)
t = (1, 10.31, 'python')(a, b, c) = tprint( a, b, c )
解压二维元组 (按照元组里的元组结构来定义变量)
t = (1, 10.31, ('OK','python'))(a, b, (c,d)) = tprint( a, b, c, d )
如果你只想要元组其中几个元素,用通配符「
*
」,英文叫 wildcard,在计算机语言中
代表一个或多个元素
。下例就是把多个元素丢给了 rest 变量。
t = 1, 2, 3, 4, 5a, b, *rest, c = tprint( a, b, c )print( rest )
如果你根本不在乎 rest 变量,那么就用通配符「
*
」加上下划线「
_
」,刘例子如下:
a, b, *_ = tprint( a, b )
优点
:占内存小,安全,创建遍历速度比列表快,可一赋多值。
缺点
:不能添加和更改元素。
等等等,这里有点矛盾,元组的不可更改性即使优点 (安全) 有时缺点?确实是这样的,安全就没那么灵活,灵活就没那么安全。看看大佬廖雪峰怎么评价「不可更改性」吧
immutable 的好处实在是太多了:
性能优化
,多线程安全,不需要锁,不担心被恶意修改或者不小心修改。
后面那些安全性的东西我也不大懂,性能优化这个我可以来测试一下列表和元组。列表虽然没介绍,但是非常简单,把元组的「小括号 ()」该成「中括号 []」就是列表了。我们从创建、遍历和占空间三方面比较。
%timeit [1, 2, 3, 4, 5]%timeit (1, 2, 3, 4, 5)
62 ns ± 13.2 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
12.9 ns ± 1.94 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)
创建速度,元组 (12.9ns) 碾压列表 (62ns)。
lst = [i for i in range(65535)]tup = tuple(i for i in range(65535))%timeit for each in lst: pass%timeit for each in tup: pass
507 µs ± 61.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
498 µs ± 18.7 µs per loop (mean ± std. dev. of 7
runs, 1000 loops each)
遍历速度两者相当,元组 (498 µs) 险胜列表 (507 µs)。
from sys import getsizeofprint( getsizeof(lst) )print( getsizeof(tup) )
列表比元组稍微废点内存空间。
「列表」定义语法为
[
元素1
,
元素2
,
...
,
元素n
]
关键点是「
中括号 []
」和「
逗号 ,
」
-
中括号
把所有元素绑在一起
-
逗号
将每个元素一一分开
创建列表的例子如下:
l = [1, 10.31,'python']print(l, type(l))
[1, 10.31, 'python'] <class 'list'>
不像元组,列表内容可更改 (mutable),因此附加 (append, extend)、插入 (insert)、删除 (remove, pop) 这些操作都可以用在它身上。
l.append([4, 3])print( l )l.extend([1.5, 2.0, 'OK'])print( l )
[1, 10.31, 'python', [4, 3]]
[1, 10.31, 'python', [4, 3], 1.5, 2.0, 'OK']
严格来说
append
是
追加
,把一个东西
整体
添加在列表后,而
extend
是
扩展
,把一个东西里的
所有元素
添加在列表后。对着上面结果感受一下区别。
l.insert(1, 'abc') # insert object before the index positionl
[1, 'abc', 10.31, 'python', [4, 3], 1.5, 2.0
, 'OK']
insert(i, x) 在编号 i 位置前插入 x。对着上面结果感受一下。
l.remove('python') # remove first occurrence of objectl
[1, 'abc', 10.31, [4, 3], 1.5, 2.0, 'OK']
p = l.pop(3) # removes and returns object at index. Only only pop 1 index position at any time.print( p )print( l )
[4, 3]
[1, 'abc', 10.31, 1.5, 2.0, 'OK']
remove 和 pop 都可以删除元素
对着上面结果感受一下,具体用哪个看你需求。
索引 (indexing) 和切片 (slicing) 语法在
元组那节
都讲了,而且怎么判断切片出来的元素在
字符
那节
也讲了,规则如下图:
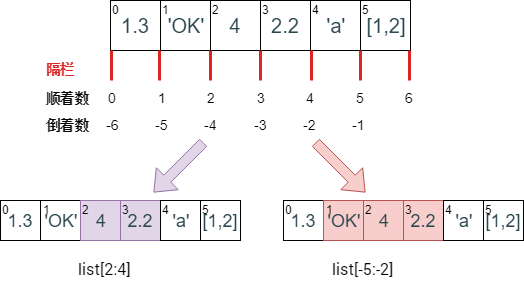
对照上图看下面两个例子 (顺着数和倒着数编号):
l = [7, 2, 9, 10, 1, 3, 7, 2, 0, 1]l[1:5]
列表可更改,因此可以用切片来赋值。
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
切片的通用写法是
start
:
stop
:
step
这三个在特定情况下都可以省去,我们来看看四种情况:
print( l )print( l[3:] )print( l[-4:] )
[7
, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[1000, 1, 3, 7, 2, 0, 1]
[7, 2, 0, 1]
以
step
为 1 (默认) 从编号
start
往列表尾部切片。
print( l )print( l[:6] )print( l[:-4] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[7, 2, 999, 1000, 1, 3]
[7, 2, 999, 1000, 1, 3]
以
step
为 1 (默认) 从列表头部往编号
stop
切片。
print( l )print( l[2:4] )print( l[-5:-1] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[999, 1000]
[3, 7, 2, 0]
以
step
为 1 (默认) 从编号
start
往编号
stop
切片。
情况 4 -
start
:
stop
:
step
print( l )print( l[1:5:2] )print( l[:5:2] )print( l[1::2] )print( l[::2] )print( l[::-1] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[2, 1000]
[7, 999, 1]
[2, 1000, 3, 2, 1]
[7, 999, 1, 7, 0]
[1, 0, 2, 7, 3, 1, 1000, 999, 2, 7]
以具体的
step
从编号
start
往编号
stop
切片。注意最后把
step
设为 -1,相当于将列表反向排列。
和元组拼接一样, 列表拼接也有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
[1, 10.31, 'python'] + ['data', 11] + ['OK'][1, 10.31, 'python'] * 2
[1, 10.31, 'python', 'data', 11, 'OK']
[1, 10.31, 'python', 1, 10.31, 'python']
优点
:灵活好用,可索引、可切片、可更改、可附加、可插入、可删除。
缺点
:相比 tuple 创建和遍历速度慢,占内存。此外查找和插入时间较慢。
「字典」定义语法为
{
元素1
,
元素2
,
...
,
元素n
}
其中每一个元素是一个「键值对」- 键
:
值 (key
:
value)
关键点是「
大括号 {}
」,「
逗号 ,
」和「
分号 :
」
-
大括号
把所有元素绑在一起
-
逗号
将每个键值对一一分开
-
分号
将键和值分开
创建字典的例子如下:
d = {'Name' : 'Tencent','Country' : 'China','Industry' : 'Technology','Code': '00700.HK','Price' : '361 HKD'}print( d, type(d) )
{'Name': 'Tencent', 'Country': 'China',
'Industry': 'Technology', 'Code': '00700.HK',
'Price': '361 HKD'} <class 'dict'>
字典里最常用的三个内置方法就是 keys(), values() 和 items(),分别是获取字典的键、值、对。
print( list(d.keys()),'\n' )print( list(d.values()), '\n' )print( list(d.items()) )
['Name', 'Country', 'Industry', 'Code', 'Price', 'Headquarter']
['Tencent', 'China', 'Technology', '00700.HK', '359 HKD', 'Shen Zhen']
[('Name', 'Tencent'), ('Country', 'China'),
('Industry', 'Technology'), ('Code', '00700.HK'),
('Price', '359 HKD'), ('Headquarter', 'Shen Zhen')]
此外在字典上也有添加、获取、更新、删除等操作。
比如加一个「总部:深圳」
d['Headquarter'] = 'Shen Zhen'd
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Code': '00700.HK',
'Price': '361 HKD',
'Headquarter': 'Shen Zhen'}
比如想看看腾讯的股价是多少 (两种方法都可以)
print( d['Price'] )print( d.get('Price') )
比如更新腾讯的股价到 359 港币
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Code': '00700.HK',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}
比如去掉股票代码 (code)
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}
或像列表里的 pop() 函数,删除行业 (industry) 并返回出来。
print( d.pop('Industry') )d
Technology
{'Name': 'Tencent',
'Country': 'China',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}
字典里的键是不可更改的,因此只有那些不可更改的数据类型才能当键,比如整数 (虽然怪怪的)、浮点数 (虽然怪怪的)、布尔 (虽然怪怪的)、字符、元组 (虽然怪怪的),而列表却不行,因为它可更改。看个例子
d = {2 : 'integer key',10.31 : 'float key',True : 'boolean key',('OK',3) : 'tuple key'}d
{2: 'integer key',
10.31: 'float key',
True: 'boolean key',
('OK', 3): 'tuple key'








