|
|
专栏名称: 大数据文摘
| 普及数据思维,传播数据文化 |
目录
相关文章推荐

|
CDA数据分析师 · 用Deepseek处理复杂数据效果好吗?小白 ... · 17 小时前 |

|
软件定义世界(SDX) · 指标数据体系建设分享 · 昨天 |

|
CDA数据分析师 · 【2月】CDA网校2025 ... · 2 天前 |

|
数据派THU · 机器学习过程:特征、模型、优化和评估 · 2 天前 |

|
大数据D1net · 2025年数据治理趋势与成功策略全解析 · 2 天前 |

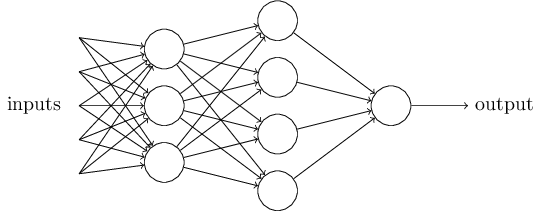
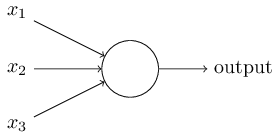
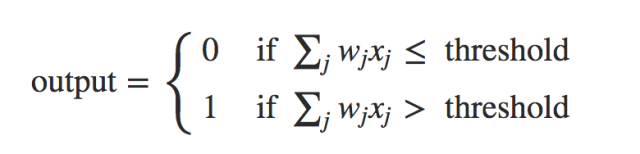
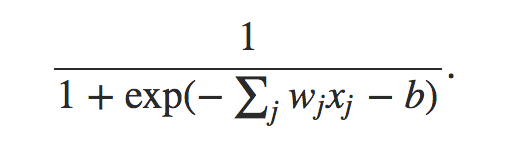
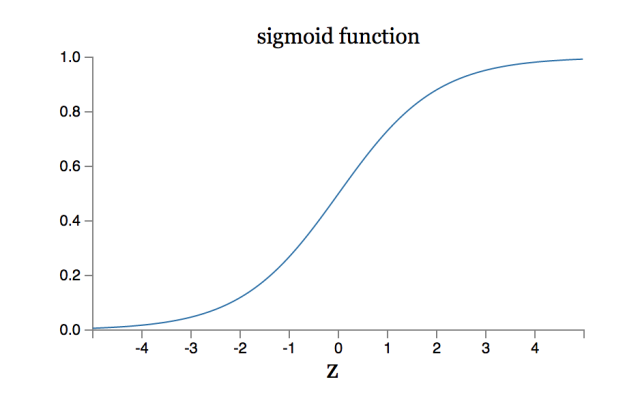
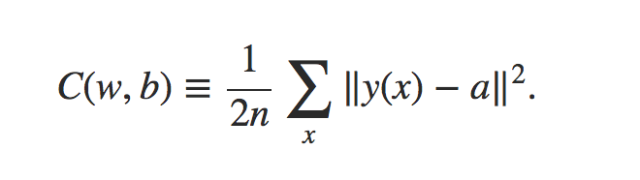
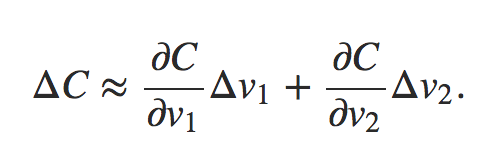
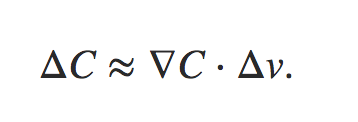
推荐文章
|
|
CDA数据分析师 · 用Deepseek处理复杂数据效果好吗?小白搞得定吗? 17 小时前 |
|
|
软件定义世界(SDX) · 指标数据体系建设分享 昨天 |
|
|
CDA数据分析师 · 【2月】CDA网校2025 数据分析组队打卡学习活动第4期已开启报名! 2 天前 |
|
|
数据派THU · 机器学习过程:特征、模型、优化和评估 2 天前 |
|
|
大数据D1net · 2025年数据治理趋势与成功策略全解析 2 天前 |

|
投行业务资讯 · 今天证监会发布重磅消息,这些投行、上市公司大股东今夜无眠 7 年前 |

|
程序员大咖 · 年收入12万,是一种什么样的体验? 7 年前 |

|
潇湘经略 · 《远离夏季空调病,坐着也要驱寒补气》 7 年前 |

|
新北方 · 小伙吃完这两样东西 四肢无法动弹!这样吃很危险! 7 年前 |

|
幕味儿 · 说古天乐是银幕第一烂片王,你服气吗? 7 年前 |