近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类领域特别是应用深度学习解决文本分类的相关的思路、做法和部分实践的经验。
业务问题描述
:
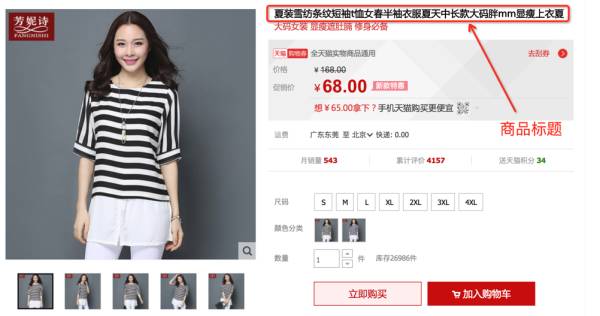
淘宝商品的一个典型的例子见下图,图中商品的标题是“
夏装雪纺条纹短袖t恤女春半袖衣服夏天中长款大码胖mm显瘦上衣夏
”。淘宝网后台是通过树形的多层的类目体系管理商品的,覆盖叶子类目数量达上万个,商品量也是10亿量级,我们是任务是根据商品标题预测其所在叶子类目,示例中商品归属的类目为“女装/女士精品>>蕾丝衫/雪纺衫”。很显然,这是一个非常典型的短文本多分类问题。接下来分别会介绍下文本分类传统和深度学习的做法,最后简单梳理下实践的经验。
一、传统文本分类方法
文本分类问题算是自然语言处理领域中一个非常经典的问题了,相关研究最早可以追溯到上世纪50年代,当时是通过专家规则(Pattern)进行分类,甚至在80年代初一度发展到利用知识工程建立专家系统,这样做的好处是短平快的解决top问题,但显然天花板非常低,不仅费时费力,覆盖的范围和准确率都非常有限。
后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典玩法,这个阶段的主要套路是人工特征工程+浅层分类模型。训练文本分类器过程见下图:
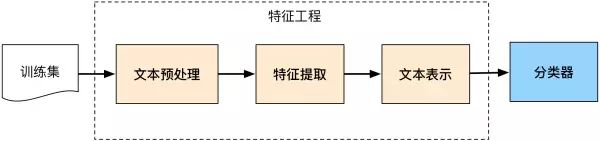
整个文本分类问题就拆分成了特征工程和分类器两部分,玩机器学习的同学对此自然再熟悉不过了
1.1 特征工程
特征工程在机器学习中往往是最耗时耗力的,但却极其的重要。抽象来讲,机器学习问题是把数据转换成信息再提炼到知识的过程,特征是“数据-->信息”的过程,决定了结果的上限,而分类器是“信息-->知识”的过程,则是去逼近这个上限。然而特征工程不同于分类器模型,不具备很强的通用性,往往需要结合对特征任务的理解。
文本分类问题所在的自然语言领域自然也有其特有的特征处理逻辑,传统分本分类任务大部分工作也在此处。文本特征工程分位文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。
1)文本预处理
文本预处理过程是在文本中提取关键词表示文本的过程,中文文本处理中主要包括文本分词和去停用词两个阶段。之所以进行分词,是因为很多研究表明特征粒度为词粒度远好于字粒度,其实很好理解,因为大部分分类算法不考虑词序信息,基于字粒度显然损失了过多“n-gram”信息。
具体到中文分词,不同于英文有天然的空格间隔,需要设计复杂的分词算法。传统算法主要有基于字符串匹配的正向/逆向/双向最大匹配;基于理解的句法和语义分析消歧;基于统计的互信息/CRF方法。近年来随着深度学习的应用,WordEmbedding
+
Bi-LSTM+CRF方法逐渐成为主流,本文重点在文本分类,就不展开了。而停止词是文本中一些高频的代词连词介词等对文本分类无意义的词,通常维护一个停用词表,特征提取过程中删除停用表中出现的词,本质上属于特征选择的一部分。
经过文本分词和去停止词之后淘宝商品示例标题变成了下图“ / ”分割的一个个关键词的形式:
夏装 / 雪纺 / 条纹 / 短袖 / t恤 / 女 / 春 / 半袖 / 衣服 / 夏天 / 中长款 / 大码 / 胖mm / 显瘦 / 上衣 / 夏
2)文本表示和特征提取
文本表示:
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定文本分类质量最重要的部分。传统做法常用词袋模型(BOW,
Bag Of Words)或向量空间模型(Vector Space
Model),最大的不足是忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。词袋模型的示例如下:
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)
一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性。词袋模型是向量空间模型的基础,因此向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
特征提取:
向量空间模型的文本表示方法的特征提取对应特征项的选择和特征权重计算两部分。特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、χ²统计量等。
特征权重主要是经典的TF-IDF方法及其扩展方法,主要思路是一个词的重要度与在类别内的词频成正比,与所有类别出现的次数成反比。
3)基于语义的文本表示
传统做法在文本表示方面除了向量空间模型,还有基于语义的文本表示方法,比如LDA主题模型、LSI/PLSI概率潜在语义索引等方法,一般认为这些方法得到的文本表示可以认为文档的深层表示,而word
embedding文本分布式表示方法则是深度学习方法的重要基础,下文会展现。
1.2 分类器
分类器基本都是统计分类方法了,基本上大部分机器学习方法都在文本分类领域有所应用,比如朴素贝叶斯分类算法(Naïve Bayes)、KNN、SVM、最大熵和神经网络等等,传统分类模型不是本文重点,在这里就不展开了。
二、深度学习
文本分类
方法
上文介绍了传统的文本分类做法,传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性,。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。接下来会分别介绍:
2.1 文本的分布式表示:词向量(word embedding)
分布式表示(Distributed
Representation)其实Hinton 最早在1986年就提出了,基本思想是将每个词表达成 n
维稠密、连续的实数向量,与之相对的one-hot
encoding向量空间只有一个维度是1,其余都是0。分布式表示最大的优点是具备非常powerful的特征表达能力,比如 n 维向量每维 k
个值,可以表征这k^n个概念。事实上,不管是神经网络的隐层,还是多个潜在变量的概率主题模型,都是应用分布式表示。下图是03年Bengio在
A Neural Probabilistic Language Model
的网络结构:
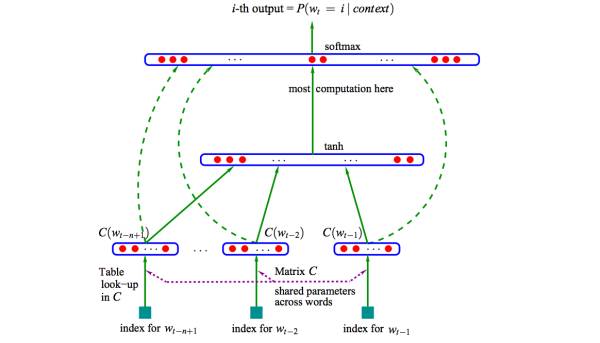 这篇文章提出的神经网络语言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目标是构建语言模型:
这篇文章提出的神经网络语言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目标是构建语言模型:
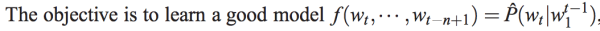 词的分布式表示即词向量(word embedding)是训练语言模型的一个附加产物,即图中的Matrix C。
词的分布式表示即词向量(word embedding)是训练语言模型的一个附加产物,即图中的Matrix C。
尽管Hinton 86年就提出了词的分布式表示,Bengio 03年便提出了NNLM,词向量真正火起来是google Mikolov 13年发表的两篇word2vec的文章
Efficient Estimation of Word Representations in Vector Space
和
Distributed Representations of Words and Phrases and their Compositionality
,更重要的是发布了简单好用的
word2vec工具包
,在语义维度上得到了很好的验证,极大的推进了文本分析的进程。下图是文中提出的CBOW 和 Skip-Gram两个模型的结构,基本类似于NNLM,不同的是模型去掉了非线性隐层,预测目标不同,CBOW是上下文词预测当前词,Skip-Gram则相反。
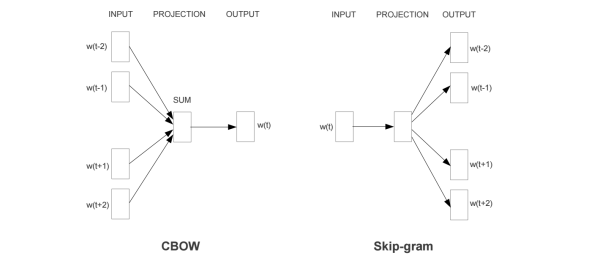
除此之外,提出了Hierarchical
Softmax 和 Negative
Sample两个方法,很好的解决了计算有效性,事实上这两个方法都没有严格的理论证明,有些trick之处,非常的实用主义。详细的过程不再阐述了,有兴趣深入理解word2vec的,推荐读读这篇很不错的paper:
word2vec Parameter Learning Explained
。额外多提一点,实际上word2vec学习的向量和真正语义还有差距,更多学到的是具备相似上下文的词,比如“good”“bad”相似度也很高,反而是文本分类任务输入有监督的语义能够学到更好的语义表示,有机会后续系统分享下。
至此,文本的表示通过词向量的表示方式,把文本数据从高纬度高稀疏的神经网络难处理的方式,变成了类似图像、语音的的连续稠密数据。深度学习算法本身有很强的数据迁移性,很多之前在图像领域很适用的深度学习算法比如CNN等也可以很好的迁移到文本领域了,下一小节具体阐述下文本分类领域深度学习的方法。
原文链接:
https://zhuanlan.zhihu.com/p/25928551





