200 多家明星企业,20 位著名投资机构顶级投资人共同参与!「新智造成长榜」致力于发掘 AI 领域有 “三年十倍” 成长潜力的创新公司,下一波 AI 独角兽,会有你么?点击加入!
你做一个表情,或者说一句话,机器就可以准确地识别你的情绪。
没错,当你在渴望 get“读心术” 技能的时候,机器已经能完美的实现了。目前,国内的翼开科技、以色列公司 Beyond Verbal 以及美国的 Affectiva 和 Emotient 都在做这情感计算解决方案。其应用场景也非常广泛:飞行员情绪监控、呼叫中心情绪考核、学生情绪监测甚至是智能硬件都可以使用这类算法,而且精度可以达到 90% 以上。
简单来说,机器是根据人的心率、呼吸、语音甚至是面部表情等特征,再通过特定的模型算法就能解读出人的情绪状态,从技术角度看,数据挖掘、机器学习等都是情感计算的基础。
那么完成情感判断需要哪些模块?以及具体实现原理是怎样的呢?本期硬创公开课,雷锋网邀请到了翼开科技创始人魏清晨为大家分享情感计算的技术问题以及应用场景。
嘉宾介绍

魏清晨,翼开科技 EmoKit 创始人,目前全面负责 EmoKit 公司的战略规划、运营管理、团队建设,团队里两名核心科学家均为海归博士后。
EmoKit,即海妖情感计算引擎,包括情绪的识别、优化、表达,是人工智能的核心基础设施之一。自 2015 年创立半年获得 600 万投资,如今已经超 2000 万用户,今年获得近 2000 万元订单。Emokit 先后获得美国麻省理工学院举办的 “MIT-CHIEF 全球创业大赛” 中国区第一名,芬兰 “Slush World 2014 全球创业大赛” 名列第一,工信部和全国科协 2015 全国移动互联网创业大赛 “特等奖”,清华大学 H+Lab“幸福科技全球挑战赛” 冠军。
以下内容整理自本期公开课,雷锋网做了不改变愿意的编辑:
情感计算的模块和价值
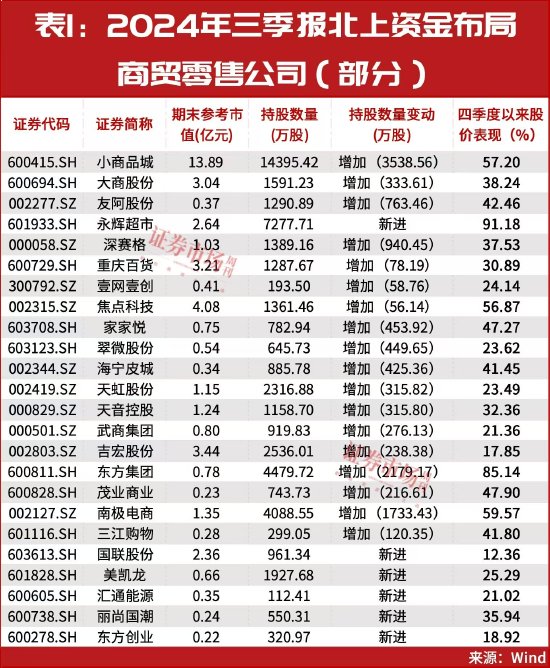
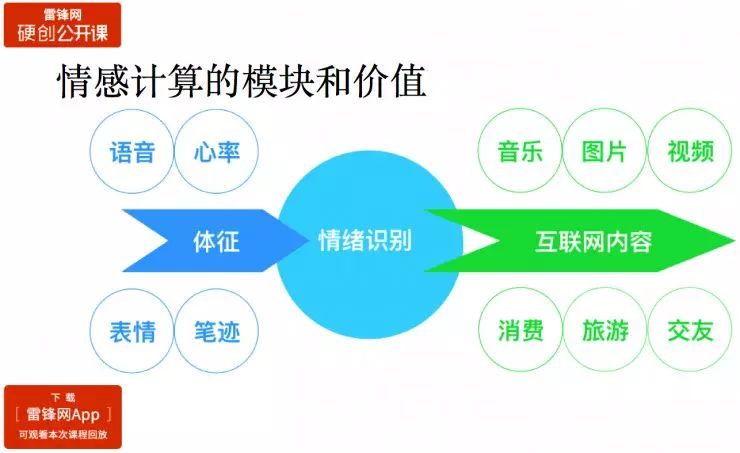
就我们现在在做的事情来看,我们把情感计算分成 3 个模块:第一部分是情绪识别,通过语音、心率、表情和写字过程中压感和速率的变化来判断用户的情绪。
情绪识别
情绪的类型一共有 24 种,积极和消极各 12 种。在情感计算的发展过程中,算法也经历了六次升级。第一代我们通过量表测评,第二代加入了心率和呼吸,第三代针对个体增加了纵向的学习和训练,第四代我们对情绪做了一个细化(从原来的 5 中情绪增加到了 24 种),第五代加入了表情和笔记的情绪识别,第六代主要做两块工作:一个是判断了用户的情绪之后,基于单一的事件背景进一步识别用户的意图;第二个工作就是把语音、表情和视觉的行为、文本做一个多模态的拟合。
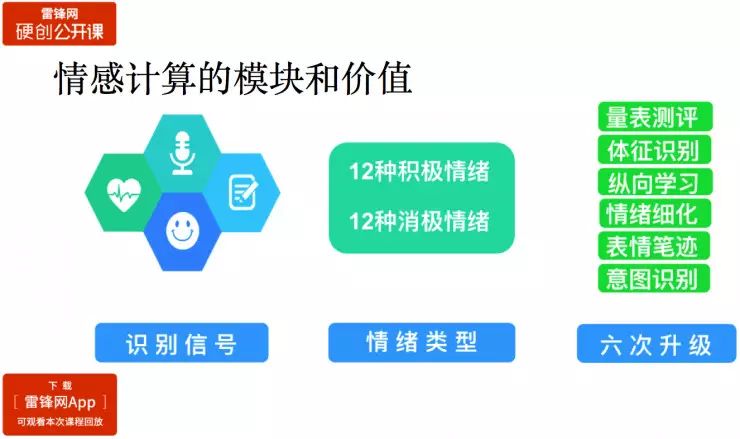
情绪优化模块
情绪识别只是第一步,未来需要解决的问题是调整用户的情绪。从上图可以看出,通过语音、心率表情和笔记这些信息判断用户的情绪之后,还可以通过推荐内容来缓解用户的情绪。
例如,翼开科技 2011 年上线的一款应用就会给用户推荐诗歌、书法、音乐等等,后来在音乐内容上做得更加深入,我们通过分析音乐的音高、节奏、旋律和音强,3 分钟的歌曲会采集 6000 个数据点分,根据这些信息来给歌曲打情绪标签。现在已经标注过得音乐数量超过了 160 万首,另外,像图片、视频都是可以通过用户的情绪来做内容匹配,最终达到缓解情绪的目的。
情绪表达
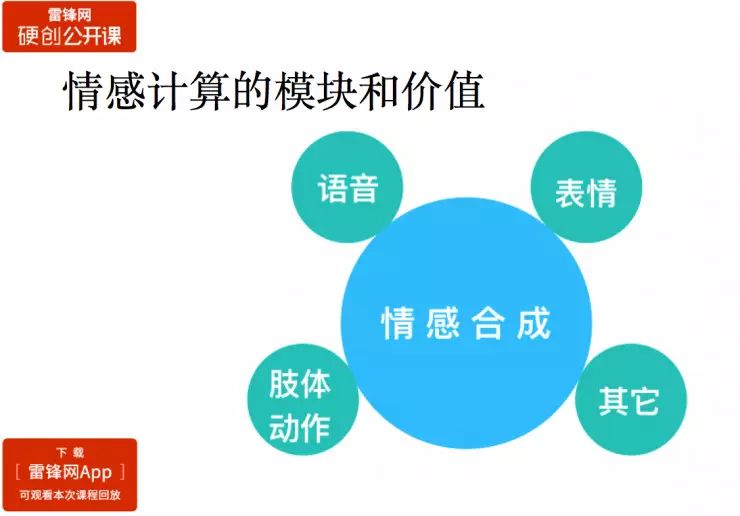
情绪表达是利用情感合成技术,让一段语音、表情或者肢体动作模拟人的情感,让机器带有情感的表达出来,这样就可以提升人和机器的交互体验。
举个例子,如果送餐机器人只会识别菜和客人,这是基础服务;但要增加机器人的附加价值,需要送餐机器人读懂客人的情绪,客人情绪低落的时候,送餐机器人会以一种比较舒缓的情绪对话。
情感计算技术实现的路线
目前翼开科技和中科院心理所、清华大学心理系和美国卡内基梅隆大学语言技术研究所。
这实际上是两个流派:前面的两个机构代表的是基于理论研究的专家模型,卡内基梅隆大学是基于神经网络、深度学习的模型。
目前翼开科技在做的有一部分是基于深度学习的,也有一部分是基于专家模型。我们认为这两类的瓶颈都逐渐显现出来了,需要相互融合。
为什么会用深度学习来做表情的识别?
现在做深度学习的瓶颈在于大量标注过的数据,不过表情标注会相对比较容易,一张人脸只判断喜怒哀乐,一般情况下 1 秒就可以识别出一个人的表情,如果有几十万张表情图片,用众包的方式所需的时间和费用都不会很大。
不过有一些数据不太方便做标注,例如语音。
三分钟的语音,我们必须听完三分钟才能做情绪的标注,标注的工作量在无形中增加了上百倍,而且相对表情而言,语音的情绪表达更加隐性,所以也很难用深度学习的方式来实现语音的情绪识别。
还有一种是普通人很难进行标注的,如心率。即使你是一个专业的医生,看完一段心率图也无法确定测试对象心率变化的原因(开心、焦虑、愤怒)。
所以,现在表情是基于深度学习的,语音和心率基于专家模型。
不过刚才也讲到,这两类在发展到一定程度时候,会存在瓶颈。例表情面临的瓶颈有两个:1. 普通人标注人脸表情的颗粒度一般是 6-8 种情绪,很难识别更细的(24 种甚至是一百多种);2. 即便完成了情绪类型的标准,但你无法确认情绪的真伪。
在专家模型中,则有比较成熟的模型来判断情绪的真伪,因此,我们可以在深度学习的基础上,再叠加专家模型来突破这样的瓶颈。
心率和语音基于专家模型也存在瓶颈,现在的解决办法是建立一个个体用户强化训练的模型(一个用户测得越多,模型会越贴合被测用户的特征);另外,我们还可以建立一个半监督学习算法来得到实时的反馈。
因此,表面上有两条技术路线,但实际上这二者是相互融合的。
情感计算的不同理解
不同的行业对于情感计算的理解是不一样的。罗莎琳德 · 皮卡德是麻省理工学院 MediaLab 的老师,她也是情感计算学科的奠基人。
在她《情感计算》这本书中的序言中有这么一句话:如果要让计算机实现真正的智能并适应我们,跟我们产生自然而然的人机交互,那么,它就需要具备情绪识别和表达能力,就需要具备情感。
谷歌云计算首席科学家李飞飞对情感计算是这么理解的:现在我们的 AI 都是用逻辑的方法来判断情感。逻辑代表 IQ,而情感代表 EQ。未来,从情绪到情感,是人工智能未来前进的方向。
我们认为可以从三个角度来理解情感计算:
第一,情感计算可以帮助 AI 来识别用户的情绪;
第二,情感计算可以帮助 AI 模拟人类的情绪,以改善人机情感交互;
第三,情感计算可以让 AI 产生自我约束能力(同理心)。
应用场景
目前翼开科技和环信展开了合作,环信有 IM 沟通工具,这里面包含了语音、表情和文本等信息,我们对其开放了绑定的 SDK,可以通过语音等信息来判断用户的情绪。
另外,我们现在还和科大讯飞有合作,合作的方式主要是相互交叉授权,通过绑定版的 SDK,科大讯飞来识别语音,翼开科技来判断情绪;现在还在做视觉的应用,科大讯飞识别人的身份,翼开科技来识别其情绪。
另外,以下这些都是情感计算可能落地的应用场景:
1. 基于 AI 多模态识别和生物反馈技术的精神压力智能筛查装备
2. 基于 AI 多模态识别和 NLP 技术的公安审讯实时分析预警装备
3. 基于 AI 多模态识别和车载控制技术的司机情绪和疲劳度监测敢于系统
4. 基于 AI 多模态识别和智能控制技术的情感联动的无操控智能家居系统
5. 基于 AI 多模态识别和动机分析技术的金融信贷面签风险评估机器人
6. 基于语音声纹和 NLP 技术的呼叫中心坐席情绪监控和满意度分析方案
7. 基于情感大数据时序递归分析技术的幼儿性格发育倾向性预测软件
8. 基于情感大数据时序递归分析技术的承认免疫系统损伤预警软件
当然,对于创业公司而言,要做出上述所有场景来推向市场,雷锋网了解到,翼开科技已经在教育、金融等领域做出了商业化的尝试。
精彩问答
Q:语音、图像这些不同的模块怎么在系统里面协调工作?
A:其实就是一个多模态的算法,有两种实现的方法:本身数据就是多模态的数据,然后做标注,做完玩标注就可以通过深度学习的方式来做训练;第二种,通过同一个 sensor 采集数据后再做多模态,例如通过麦克风可以采集到用户的语音、声纹特征,进一步分析文本,来做多模态。
Q:情感数据对准确率还是有很大的影响,这些数据是怎么搜集的?
A:在我们和卡内基梅隆大学情感计算专家交流的过程中,我们得到一个观点,通过单种信息来判断情绪,准确率是有局限性的;另外,越早做多模态越好,越多的模态拟合越好。
我们把反应情绪的信号分为两类,一类是浅层信号,如语音、表情;还有一类是深层信号,完全受交感神经和副交感神经的影响,主观意识很难控制。
浅层信号更容易采集,但权重不高;深层信号权重高,但采集难度比较大。两种信号做综合的多模态分析可以提升情感判断的准确度。
Q:目前的准确率有多高?多模态的模型有相关的 paper 吗?
A:语音和心率是基于专家模型的,这个精度会低一点,在 85% 左右,表情在 90% 左右(但是表情只有 7 中情绪)。
Q:情感识别目前有判断准确率的行业标准吗?没有标准的话,从哪些维度来提升识别率?
A:现在判断情绪标准的类型比较多,常见的如果用深度学习方法实现的模型,再重新另一套标注的数据来跑一下这个模型,来判断它的精度;另外,可以根据用户反馈来判断,把系统测试的结果反馈给用户,让用户来给出最终验证。
如何优化?可以通过半监督学习的方式,来进行自我训练自我校正。
Q:有采用脑电波的模态数据吗?
A:国外做这一块的研究有很多,我们现在认为脑电 sensor 还不是消费终端的标配,采集脑电要专门的 sensor,目前只用在特殊的行业,还没有做通用算法的开放。
PS:翼开科技正在招聘:机器学习,机器视觉,情感计算,多模态,NLP 等相关职位,如有意向欢迎投简历到:[email protected]
公开课视频