编者按:4月30日至5月3日,ICLR 2018(International Conference on Learning Representations 2018 )正在加拿大温哥华火热进行。此次大会上,微软亚洲研究院机器学习组发表了最新研究成果“Learning to Teach”,他们探索出一种新的让机器学会自动化教学的方法,进而提升数据利用率和模型性能。想看论文原文?请点击文末“阅读原文”。
近年来,“自动学习(
AutoML
)”已经成为了一个研究热点。通过自动化的方式,机器试图学习到最优的学习策略,从而避免机器学习从业者低效的手动调整方式。经典的自动学习方法包括
用于超参数调节的贝叶斯优化(Bayesian Optimization),以及用于优化器和网络结构调整的元学习技术(Meta learning/Learning-to-Learn)
。
除了在学术界引起了广泛研究兴趣,自动学习在工业界也已经得到了实际应用,例如微软
Azure
提供的自定义影像(
Custom Vision
)服务
,能够方便云计算用户自动训练用于计算机视觉的机器学习模型。除此之外,还有谷歌云提供的
AutoML
服务等。
Azure
自定义影像服务链接:
https://azure.microsoft.com/zh-cn/services/cognitive-services/custom-vision-service/
不论是传统的机器学习算法还是最近的自动学习算法,它们的重点都是如何让
AI
更好地学习:两种学习算法的训练过程都是在固定的数据集
上,通过最小化固定的损失函数(
Loss Function
)
,优化得到位于模型假设空间(
Hypothesis Space
)
里最优的模型。而两者差别仅仅在于优化过程是否是自动进行的,这无疑
限制了自动学习技术的潜力。
事实上,当我们回过头来追溯人类社会的智能史,我们会发现
“教学”这一行为,对于人类智能的培养和传承起着不可磨灭的重要作用
。《礼记·学记》曾云:“是故学然后知不足,教然后知困。知不足然后能自反也,知困然后能自强也。故曰教学相长也。”通过和人类社会的学习机制对比,我们发现传统的机器学习和近年来的自动学习都忽略了一个很重要的方面:
它们只学而不教
。无论是训练数据、损失函数,还是模型的假设空间,都对应着人类教学过程里的若干重要环节。因此我们试图打破对于训练数据、损失函数和模型假设空间的限制,把教学这一重要的概念集成到机器学习系统中,使得人工智能和机器学习算法得以教学相长。我们将这一框架命名为“
学习教学
”(
Learning to Teach
,简写为
L2T
)。其中涵盖了若干个关键问题:
1.
数据教学力图为机器学习过程寻找到最优的训练集
。训练数据对应人类教学过程中的教育材料,例如教科书。
2.损
失函数教学力图为机器学习过程寻找到最优的损失函数
。这类比于人类教学过程中,优秀的教师会通过高质量的测试过程来评估学生的学习质量,并对其进行引导。
3.模
型空间教学力图为机器学习过程定义最优的模型假设空间
。例如在训练的初期,我们可能会倾向于使用简单的线性模型来尽快学习到数据里的规律,而在训练的末期,我们可能更愿意选择复杂的深度模型来使得性能得到进一步增强。这类比于教师教授给学生的技能集合(
Skills Set
):小学生只会学习到简单的数字运算,中学生则会学习到基本的代数知识,到了大学,微积分则成为了必备的技能。
为了解决这些问题,我们定义了两个模型:
学生模型和教师模型
。前者即为通常意义下的机器学习模型,后者则负责为前者提供合适的数据、损失函数,或者模型假设空间。在图
1
中,我们简单展示了两个模型的完全自动化训练过程:在学生模型训练的每一步t
,教师模型得到学生模型的状态向量(用于反映学生模型当前的状态),根据自身参数输出教学策略,诸如当前需要使用的训练数据、损失函数,或者优化的模型空间,反馈给学生模型。学生模型基于此进行一步优化(例如梯度下降),更新其参数。之后学生模型会将一个奖励信号(例如开发集上的准确率)反馈给教师模型。教师模型基于该信号对自己的教学策略进行优化更新。这样的过程循环往复直至教师模型收敛。
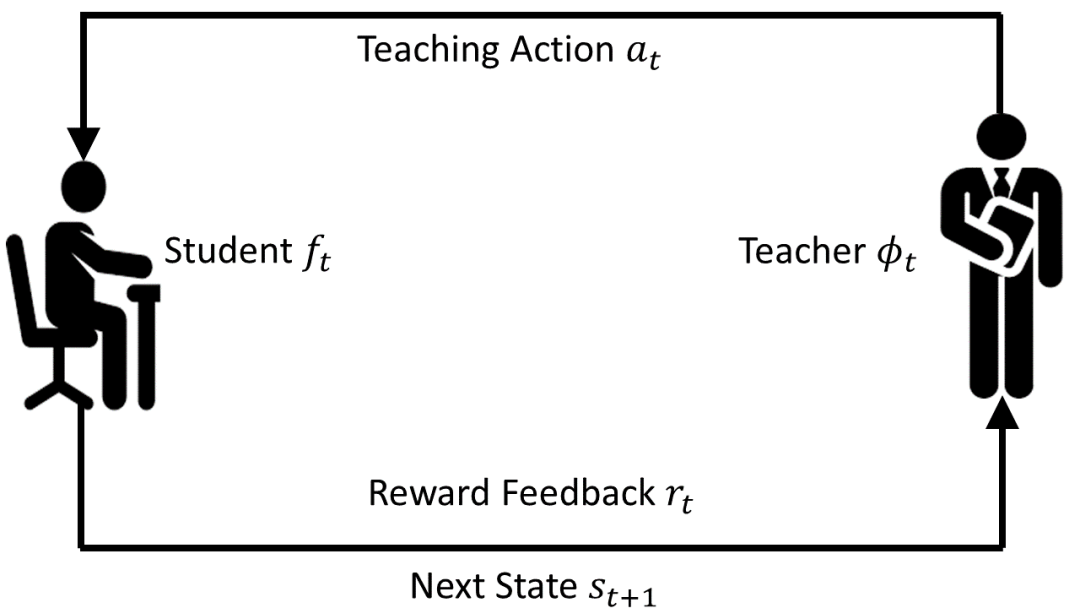
图
1 L2T
的训练过程
我们以数据教学的实验为例,来展示
L2T
在实际中如何帮助更快更好地训练机器学习模型。在我们的实验中,
学生模型是用于分类的深度神经网络,使用随机梯度下降来进行优化。教师模型是一个三层的前向网络,其职责是负责为学生模型的每步更新提供合适的批次数据(
Mini-batch Data
)
。
我们使用强化学习中的
REINFORCE
算法来进行教师模型的训练更新。
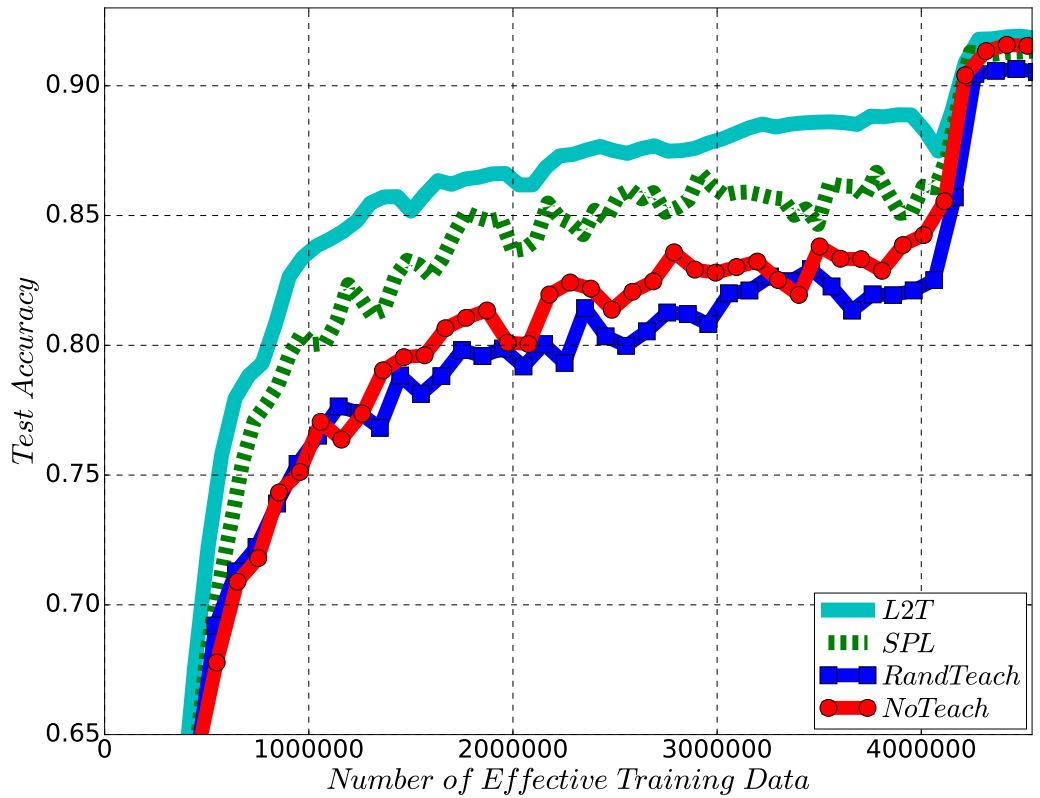
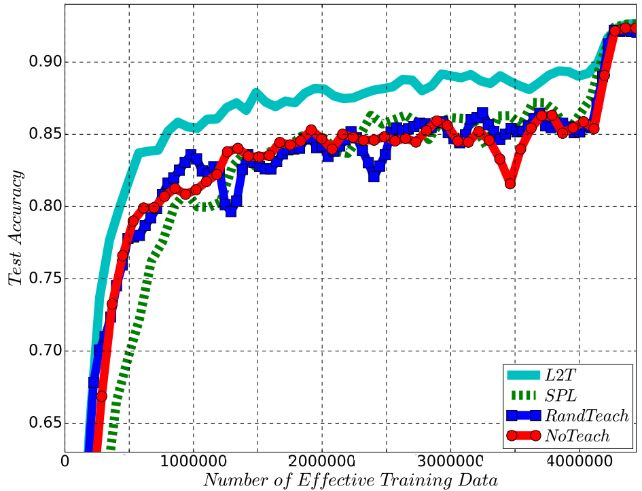
图
2 上
:训练教师网络使其指导
MNIST
上的
MLP
训练,并将其应用于
CIFAR-10
上的
ResNet-32
训练;下:训练教师网络使其指导
CIFAR-10
上的
ResNet-32
训练,并将其应用于
CIFAR-10
上的
ResNet-110
训练。
在图
2
展示的训练实验中,我们可以清楚地发现通过
L2T
训练出来的教师模型能够帮助学生模型更快地收敛。尤其需要注意的是,
L2T
具有良好的可迁移性:在小数据集、小模型上(例如用于
MNIST
的
MLP
)训练得到的教师模型可以无缝迁移到大数据集、大模型(例如用于
CIFAR-10
分类的
ResNet-32
)上。
同时,为了进一步验证
L2T
框架的效果,我们也在用于
IMDB
情感分类数据集的
LSTM
网络上进行了实验,在网络训练过程中引入
L2T
训练出来的教师模型能够显著提高网络模型的准确率(如下表所示)。

表
1
使用不同教学策略训练
LSTM
得到的
IMDB
数据集分类准确率。
总结来说,我们展示了一个新的让机器学会自动化教学的方法。初步的实验验证了该方法在提升数据利用率、提升模型性能方面有着良好的表现
。
未来我们计划将该方法应用于损失函数和模型假设空间的自动学习
,以期对机器学习模型的性能有更大的提升
,
为机器学习技术使用者提供更方便、更高效的自动化工具。
想要了解更多细节的读者,欢迎阅读我们发布在今年
ICLR 2018
上的论文
:
Learning to Teach, Yang Fan, Fei Tian,Tao Qin, Xiang-Yang Li, Tie-Yan Liu, Proceedings of Sixth International Conference on Learning Representations (ICLR 2018)
论文链接:
https://openreview.net/forum?id=HJewuJWCZ
作者简介

田飞分别于
2011
年、
2016
年在中国科学技术大学计算机系获得学士及博士学位,目前担任微软亚洲研究院机器学习组研究员。他的研究兴趣主要集中在序列学习、自动化学习,以及机器学习技术在自然语言处理领域的应用。
你也许还想
看
:










