
在大数据、人工智能时代,语音识别和声纹识别作为非常重要的技术手段,成为我们主要的关注点之一。
在第二届
“大数据在清华”高峰论坛“语音处理及数据安全技术专场”
中,清华大学语音和语言技术中心主任
郑方
发表题为“语音技术与身份信息的隐私保护”的演讲,探讨了
中间身份信息隐私保护的问题,以及语音处理技术在其中发挥的重要作用
。

清华大学语音和语言技术中心主任郑方
演讲时长约半个小时,建议使用wifi观看
公众号后台回复
“语音”
,下载演讲PPT
郑方:
在互联网时代,人们的生活既存在于物理空间,又存在于网络空间,其中网络空间的安全问题非常关键。世界各国就如何在网络空间里进行身份认证问题,提出了很多的计划,以推动个人和组织在网络上使用安全、高效、易用的身份解决方案。

在这些身份认证方式里面,未来的主体方案就是生物特征识别技术。生物特征分为两类:
生理特征比较稳定、生来不变,能够准确地反映身份。而行为特征在交互的过程中体现身份,貌似不是特别稳定,不太适合身份认证。

在生物特征识别技术的发展过程中,人们面临着诸多安全问题,如利用他人照片、视频,即可对人脸识别系统轻易进行攻击,或者只需采用一些传统方法,就可以轻易攻击某些基于AI安全手段的系统。这些问题导致的原因大概分为以下四个方面:

由于生理特征的不可撤销性,信息在采集和传输的过程中可能丢失,信息丢失之后整个人的身份就丢了;而后这些信息可能在任何的时候被非法使用,这就是隐私丢失对安全的冲击。安全和隐私,是一对孪生兄弟,它们是无监督的身份认证必须考虑的问题。

在无监督的情况下,如何安全地进行身份认证是非常关键的。将生物特征用在无监督情况下的认证,要考虑以下五个方面的因素:
-
人证合一:
生物特征要具有唯一性,识别技术要能够保证准确性。
-
不易伪造:
活体检测可用于防攻击,而且性价比高。
-
真实意图:
被认证的真实意图不怕丢失和复制,可保护隐私,但比活体检测更难、更为需要,因为它包含了活体检测的功能。
-
证据可追溯:
在无监督的情况下,每一次的认证能记录证据,就可用于追溯。
-
认证的便(pian)宜和便(bian)宜:
所谓便宜就是成本低,便宜就是方便,设备、平台依赖性低,使用方便。

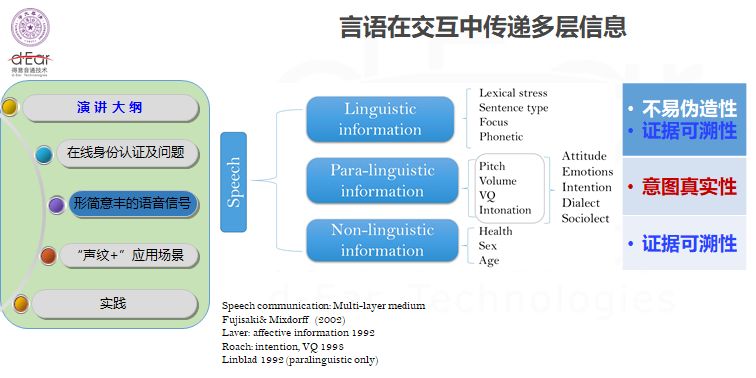
语音信号可以在很大程度上解决这一问题。语音信号是一个形简意丰的信号,信息量很大,比如说口音、语种、情感、性别身份和语音的内容,各种的信息都在一维的信号里面表现出来。

从结构化角度,人类的语言信息可以分为三层:
随着深度机器学习在语音识别、图像处理等领域的快速发展和成功应用,近年来,基于深度学习的相关方法也逐渐应用到说话人的识别中,并取得了不俗的成效。声纹识别首先涉及的是特征提取。现在用得比较多的特征提取是MFCC,一种倒谱参数,它的参数提取涉及了多层,不是在信号域提取特征,找到一些特征点和模板,而是要把它先变换到频谱域,再变换到倒谱域,经过三层的操作得出一个特征。

但是这个特征还不够,需要继续做模式识别,我们采用的模型,里面有对混合、高斯的分布进行描述,最后由通用背景和GMM的共同作用,对说话人进行刻画,最后进行身份认证。

若要安全地进行身份认证,对声纹的
第一要求就是人证合一性
。相比其他生物特征,声纹的性能比人们了解的要高。在几种生物特征里面,识别准确率依次为虹膜、声音、掌纹、指纹、指静脉、人脸。

第二个是不易伪造,声音有比较好的防攻击优势。
语音都可以用软件手段来防攻击,首先利用语音的形简意丰的特点,要识别出“谁说了什么”。其次,如果攻击者把声音录下来,然后进行拼接,我们可以进行录音重放检测。另外,可以把人的因素加进去,“三分技术七分管理”,用户自定义的数字读音和动态密码组合,形成奇妙的不用记忆的“密码”,这也是最安全的密码。

此外,可以把多特征、多活体做结合。这里用的是嘴唇,嘴唇本身有身份的信息,加上声纹就是双身份。唇语跟语音的内容一样,时序一样,这就是更强的活体检测,更能防止攻击。

第三个是检测意图的真实性
,比如语音的识别,以确定是否在无意识状态下被使用;情感识别,以确定是否受到胁迫;语音理解,以确定是否传递不便明说的危险状态。










