(点击
上方公众号
,可快速关注)
英文:BRAD PEABODY,编译:dogstar
www.itran.cc/2017/05/17/server-side-io-performance-node-php-java-go/
如有好文章投稿,请点击 → 这里了解详情
理解应用程序的输入/输出(I/O)模型,意味着其在计划处理负载与残酷的实际使用场景之间的差异。若应用程序比较小,也没有服务于很高的负载,也许它影响甚微。但随着应用程序的负载逐渐上涨,采用错误的I/O模型有可能会让你到处踩坑,伤痕累累。
正如大部分存在多种解决途径的场景一样,重点不在于哪一种途径更好,而是在于理解如何进行权衡。让我们来参观下I/O的景观,看下可以从中窃取点什么。

在这篇文章,我们将会结合Apache分别比较Node,Java,Go,和PHP,讨论这些不同的语言如何对他们的I/O进行建模,各个模型的优点和缺点,并得出一些初步基准的结论。如果关心你下一个Web应用的I/O性能,那你就找对文章了。
I/O基础知识:快速回顾
为了理解与I/O密切相关的因素,必须先来回顾在操作系统底层的概念。虽然不会直接处理这些概念的大部分,但通过应用程序的运行时环境你一直在间接地处理他们。而关键在于细节。
系统调用
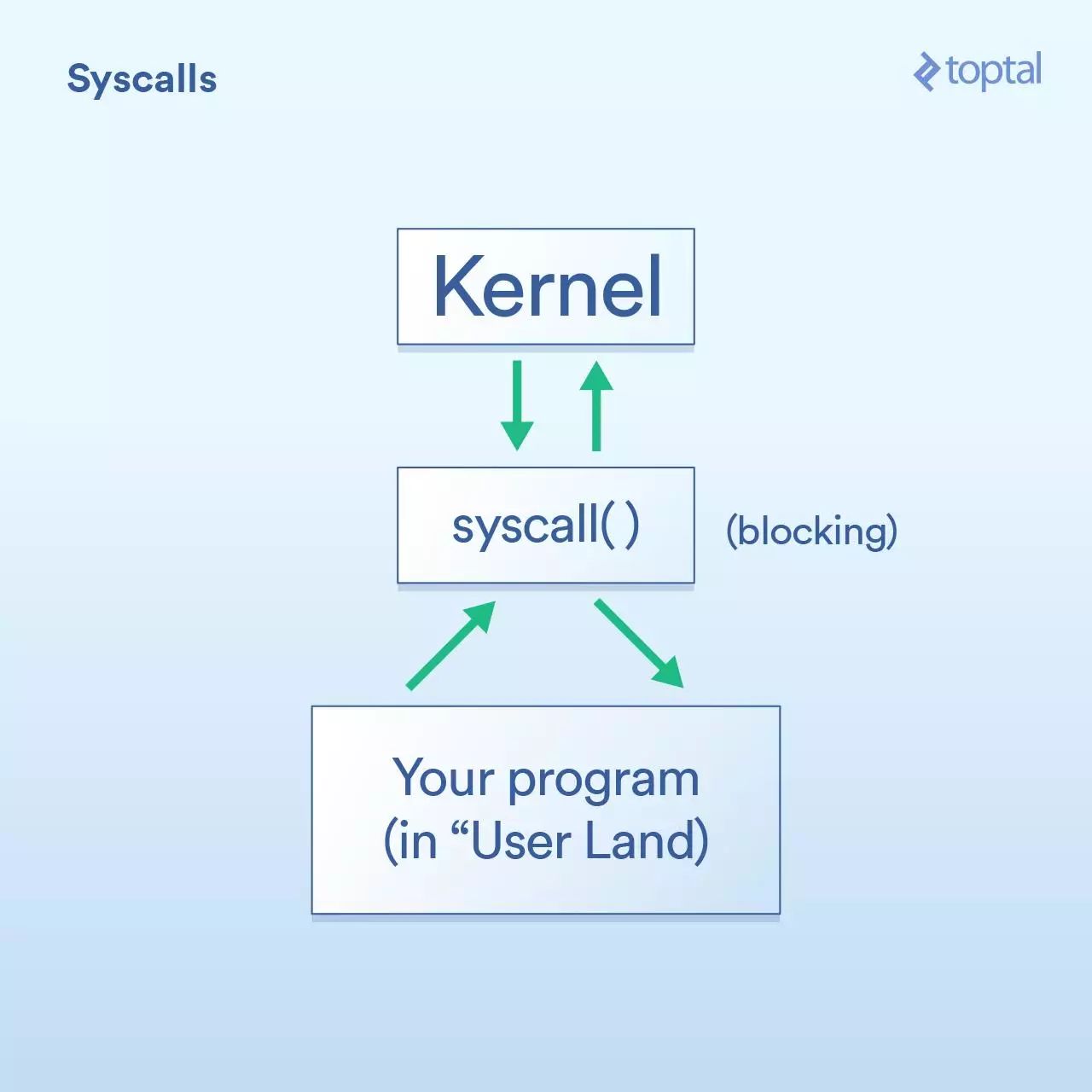
首先,我们有系统调用,它可以描述成这样:
-
你的程序(在“用户区域”,正如他们所说的)必须让操作系统内核在它自身执行I/O操作。
-
“系统调用”(syscall)意味着你的程序要求内核做某事。不同的操作系统,实现系统调用的细节有所不同,但基本的概念是一样的。这将会有一些特定的指令,把控制权从你的程序转交到内核(类似函数调用但有一些专门用于处理这种场景的特殊sauce)。通常来说,系统调用是阻塞的,意味着你的程序需要等待内核返回到你的代码。
-
内核在我们所说的物理设备(硬盘、网卡等)上执行底层的I/O操作,并回复给系统调用。在现实世界中,内核可能需要做很多事情才能完成你的请求,包括等待设备准备就绪,更新它的内部状态等,但作为一名应用程序开发人员,你可以不用关心这些。以下是内核的工作情况。
阻塞调用与非阻塞调用
好了,我刚刚在上面说系统调用是阻塞的,通常来说这是对的。然而,有些调用被分类为“非阻塞”,意味着内核接收了你的请求后,把它放进了队列或者缓冲的某个地方,然后立即返回而并没有等待实际的I/O调用。所以它只是“阻塞”了一段非常短的时间,短到只是把你的请求入列而已。
这里有一些有助于解释清楚的(Linux系统调用)例子:-read()是阻塞调用——你传给它一个文件句柄和一个存放所读到数据的缓冲,然后此调用会在当数据好后返回。注意这种方式有着优雅和简单的优点。-epoll_create(),epoll_ctl(),和epoll_wait()这些调用分别是,让你创建一组用于侦听的句柄,从该组添加/删除句柄,和然后直到有活动时才阻塞。这使得你可以通过一个线程有效地控制一系列I/O操作。如果需要这些功能,这非常棒,但也正如你所看到的,使用起来当然也相当复杂。
理解这里分时差异的数量级是很重要的。如果一个CPU内核运行在3GHz,在没有优化的情况下,它每秒执行30亿次循环(或者每纳秒3次循环)。非阻塞系统调用可能需要10纳秒这样数量级的周期才能完成——或者“相对较少的纳秒”。对于正在通过网络接收信息的阻塞调用可能需要更多的时间——例如200毫秒(0.2秒)。例如,假设非阻塞调用消耗了20纳秒,那么阻塞调用消耗了200,000,000纳秒。对于阻塞调用,你的程序多等待了1000万倍的时间。

内核提供了阻塞I/O(“从网络连接中读取并把数据给我”)和非阻塞I/O(“当这些网络连接有新数据时就告诉我”)这两种方法。而使用何种机制,对应调用过程的阻塞时间明显长度不同。
调度
接下来第三件关键的事情是,当有大量线程或进程开始阻塞时怎么办。
出于我们的目的,线程和进程之间没有太大的区别。实际上,最显而易见的执行相关的区别是,线程共享相同的内存,而每个进程则拥有他们独自的内存空间,使得分离的进程往往占据了大量的内存。但当我们讨论调度时,它最终可归结为一个事件清单(线程和进程类似),其中每个事件需要在有效的CPU内核上获得一片执行时间。如果你有300个线程正在运行并且运行在8核上,那么你得通过每个内核运行一段很短的时间然后切换到下一个线程的方式,把这些时间划分开来以便每个线程都能获得它的分时。这是通过“上下文切换”来实现的,使得CPU可以从正在运行的某个线程/进程切换到下一个。
这些上下文切换有一定的成本——它们消耗了一些时间。在快的时候,可能少于100纳秒,但是根据实现的细节,处理器速度/架构,CPU缓存等,消耗1000纳秒甚至更长的时间也并不罕见。
线程(或者进程)越多,上下文切换就越多。当我们谈论成千上万的线程,并且每一次切换需要数百纳秒时,速度将会变得非常慢。
然而,非阻塞调用本质上是告诉内核“当你有一些新的数据或者这些连接中的任意一个有事件时才调用我”。这些非阻塞调用设计于高效地处理大量的I/O负载,以及减少上下文切换。
到目前为止你还在看这篇文章吗?因为现在来到了有趣的部分:让我们来看下一些流利的语言如何使用这些工具,并就在易用性和性能之间的权衡作出一些结论……以及其他有趣的点评。
请注意,虽然在这篇文章中展示的示例是琐碎的(并且是不完整的,只是显示了相关部分的代码),但数据库访问,外部缓存系统(memcache等全部)和需要I/O的任何东西,都以执行某些背后的I/O操作而结束,这些和展示的示例一样有着同样的影响。同样地,对于I/O被描述为“阻塞”(PHP,Java)这样的情节,HTTP请求与响应的读取与写入本身是阻塞的调用:再一次,更多隐藏在系统中的I/O及其伴随的性能问题需要考虑。
为项目选择编程语言要考虑的因素有很多。当你只考虑性能时,要考虑的因素甚至有更多。但是,如果你关注的是程序主要受限于I/O,如果I/O性能对于你的项目至关重要,那这些都是你需要了解的。“保持简单”的方法:PHP。
回到90年代的时候,很多人穿着匡威鞋,用Perl写着CGI脚本。随后出现了PHP,很多人喜欢使用它,它使得制作动态网页更为容易。
PHP使用的模型相当简单。虽然有一些变化,但基本上PHP服务器看起来像:
HTTP请求来自用户的浏览器,并且访问了你的Apache网站服务器。Apache为每个请求创建一个单独的进程,通过一些优化来重用它们,以便最大程度地减少其需要执行的次数(创建进程相对来说较慢)。Apache调用PHP并告诉它在磁盘上运行相应的.php文件。PHP代码执行并做一些阻塞的I/O调用。若在PHP中调用了file_get_contents(),那在背后它会触发read()系统调用并等待结果返回。
当然,实际的代码只是简单地嵌在你的页面中,并且操作是阻塞的:
// 阻塞的文件I/O
$file_data
=
file_get_contents
(
'/path/to/file.dat'
);
// 阻塞的网络I/O
$curl
=
curl_init
(
'http://example.com/example-microservice'
);
$result
=
curl_exec
(
$curl
);
// 更多阻塞的网络I/O
$result
=
$db
->
query
(
'SELECT id, data FROM examples ORDER BY id DESC limit 100'
);
?>
关于它如何与系统集成,就像这样:
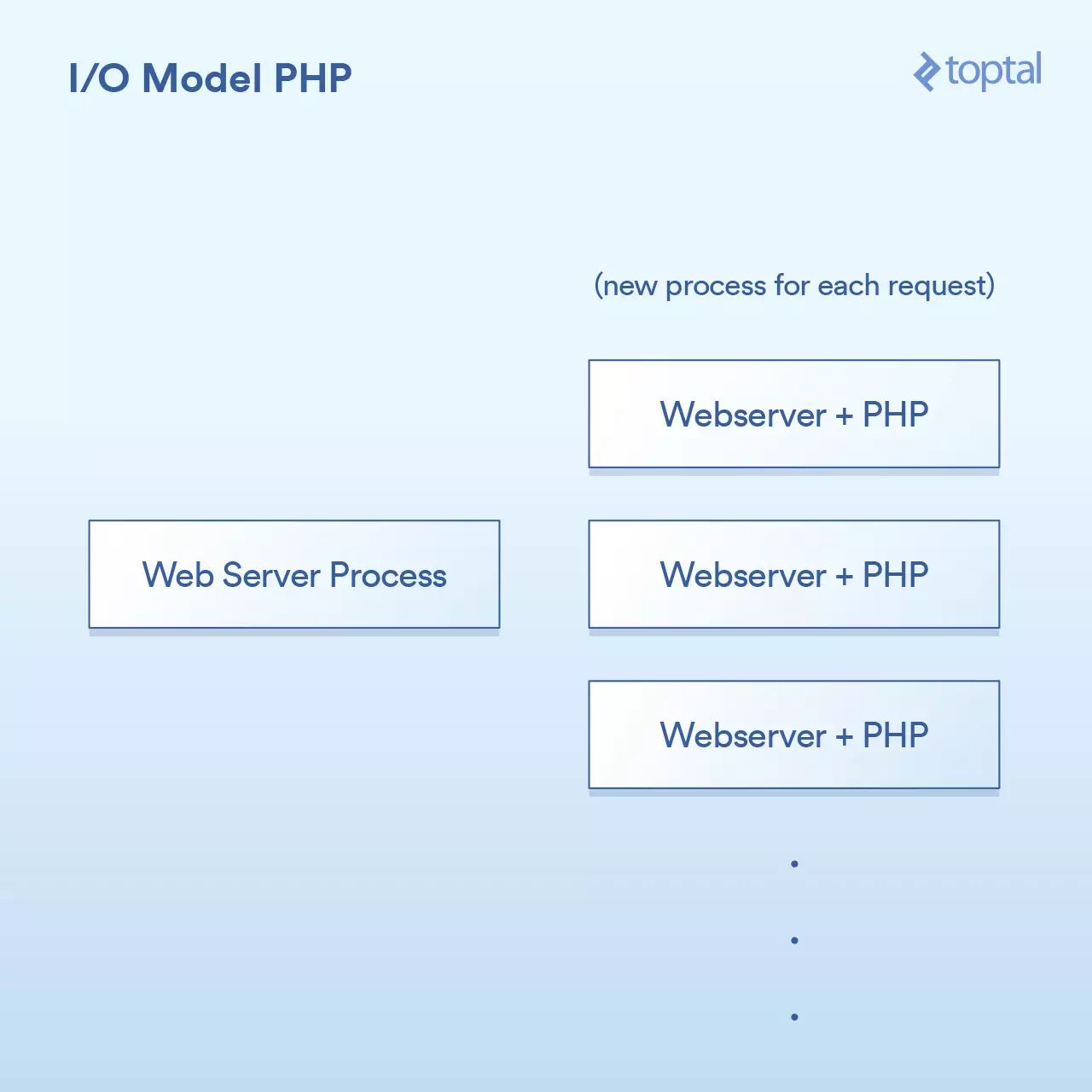
相当简单:一个请求,一个进程。I/O是阻塞的。优点是什么呢?简单,可行。那缺点是什么呢?同时与20,000个客户端连接,你的服务器就挂了。由于内核提供的用于处理大容量I/O(epoll等)的工具没有被使用,所以这种方法不能很好地扩展。更糟糕的是,为每个请求运行一个单独的过程往往会使用大量的系统资源,尤其是内存,这通常是在这样的场景中遇到的第一件事情。
注意:Ruby使用的方法与PHP非常相似,在广泛而普遍的方式下,我们可以将其视为是相同的。
多线程的方式:Java
所以就在你买了你的第一个域名的时候,Java来了,并且在一个句子之后随便说一句“dot com”是很酷的。而Java具有语言内置的多线程(特别是在创建时),这一点非常棒。
大多数Java网站服务器通过为每个进来的请求启动一个新的执行线程,然后在该线程中最终调用作为应用程序开发人员的你所编写的函数。
在Java的Servlet中执行I/O操作,往往看起来像是这样:
public
void
doGet
(
HttpServletRequest
request
,
HttpServletResponse
response
)
throws
ServletException
,
IOException
{
// 阻塞的文件I/O
InputStream
fileIs
=
new
FileInputStream
(
"/path/to/file"
);
// 阻塞的网络I/O
URLConnection
urlConnection
=
(
new
URL
(
"http://example.com/example-microservice"
)).
openConnection
();
InputStream
netIs
=
urlConnection
.
getInputStream
();
// 更多阻塞的网络I/O
out
.
println
(
"..."
);
}
由于我们上面的doGet方法对应于一个请求并且在自己的线程中运行,而不是每次请求都对应需要有自己专属内存的单独进程,所以我们会有一个单独的线程。这样会有一些不错的优点,例如可以在线程之间共享状态、共享缓存的数据等,因为它们可以相互访问各自的内存,但是它如何与调度进行交互的影响,仍然与前面PHP例子中所做的内容几乎一模一样。每个请求都会产生一个新的线程,而在这个线程中的各种I/O操作会一直阻塞,直到这个请求被完全处理为止。为了最小化创建和销毁它们的成本,线程会被汇集在一起,但是依然,有成千上万个连接就意味着成千上万个线程,这对于调度器是不利的。
一个重要的里程碑是,在Java 1.4 版本(和再次显著升级的1.7 版本)中,获得了执行非阻塞I/O调用的能力。大多数应用程序,网站和其他程序,并没有使用它,但至少它是可获得的。一些Java网站服务器尝试以各种方式利用这一点; 然而,绝大多数已经部署的Java应用程序仍然如上所述那样工作。

Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
作为一等公民的非阻塞I/O:Node
当谈到更好的I/O时,Node.js无疑是新宠。任何曾经对Node有过最简单了解的人都被告知它是“非阻塞”的,并且它能有效地处理I/O。在一般意义上,这是正确的。但魔鬼藏在细节中,当谈及性能时这个巫术的实现方式至关重要。
本质上,Node实现的范式不是基本上说“在这里编写代码来处理请求”,而是转变成“在这里写代码开始处理请求”。每次你都需要做一些涉及I/O的事情,发出请求或者提供一个当完成时Node会调用的回调函数。
在求中进行I/O操作的典型Node代码,如下所示:
http
.
createServer
(
function
(
request
,
response
)
{
fs
.
readFile
(
'/path/to/file'
,
'utf8'
,
function
(
err
,
data
)
{
response
.
end
(
data
);
});
});
可以看到,这里有两个回调函数。第一个会在请求开始时被调用,而第二个会在文件数据可用时被调用。
这样做的基本上给了Node一个在这些回调函数之间有效地处理I/O的机会。一个更加相关的场景是在Node中进行数据库调用,但我不想再列出这个烦人的例子,因为它是完全一样的原则:启动数据库调用,并提供一个回调函数给Node,它使用非阻塞调用单独执行I/O操作,然后在你所要求的数据可用时调用回调函数。这种I/O调用队列,让Node来处理,然后获取回调函数的机制称为“事件循环”。它工作得非常好。
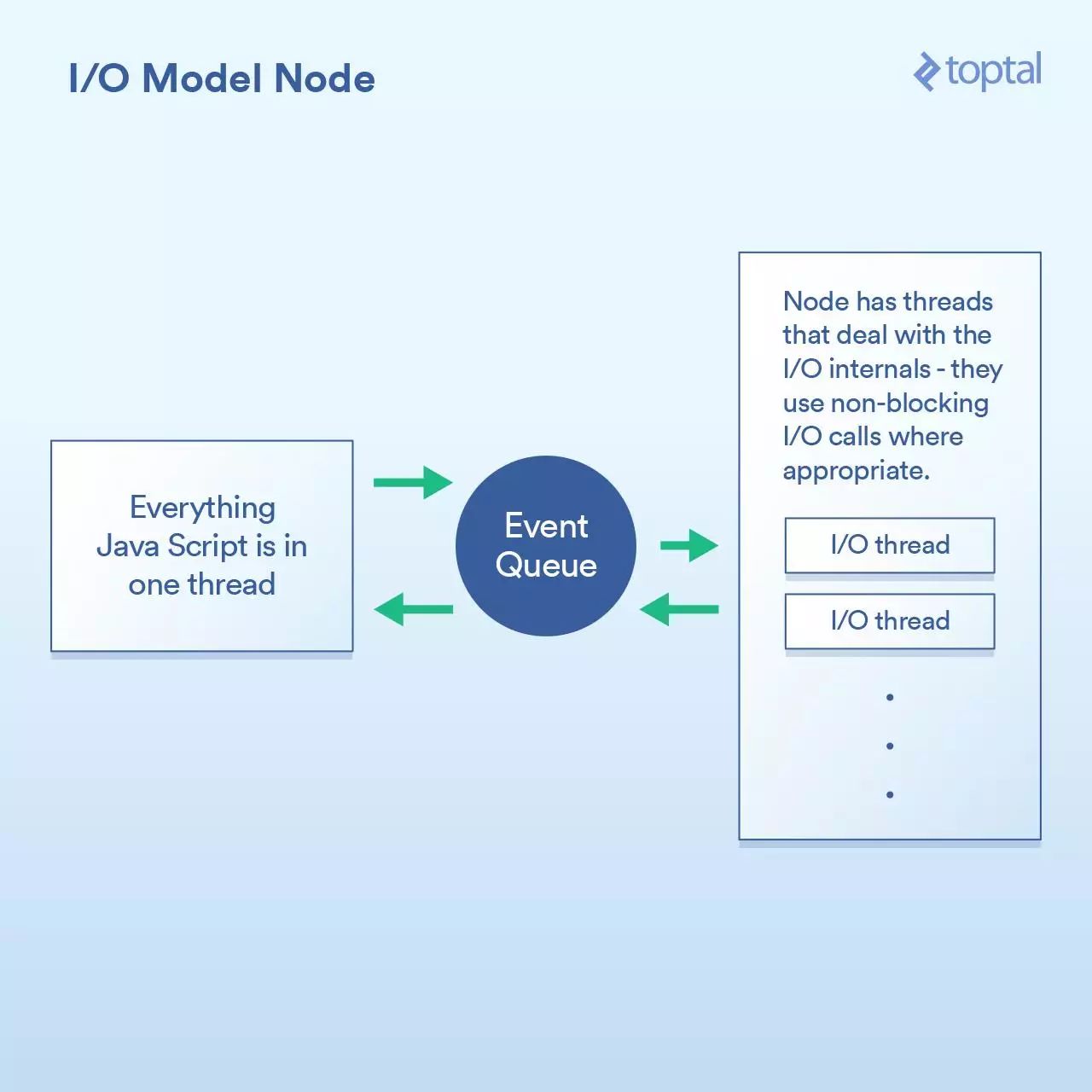
然而,这个模型中有一道关卡。在幕后,究其原因,更多是如何实现JavaScript V8 引擎(Chrome的JS引擎,用于Node)1,而不是其他任何事情。你所编写的JS代码全部都运行在一个线程中。思考一下。这意味着当使用有效的非阻塞技术执行I/O时,正在进行CPU绑定操作的JS可以在运行在单线程中,每个代码块阻塞下一个。 一个常见的例子是循环数据库记录,在输出到客户端前以某种方式处理它们。以下是一个例子,演示了它如何工作:
var
handler
=
function
(
request
,
response
)
{
connection
.
query
(
'SELECT ...'
,
function
(
err
,
rows
)
{
if
(
err
)
{
throw
err
};
for
(
var
i
=
0
;
i
rows
.
length
;
i
++
)
{
// 对每一行纪录进行处理
}
response
.
end
(...);
// 输出结果
})
};
虽然Node确实可以有效地处理I/O,但上面的例子中的for循环使用的是在你主线程中的CPU周期。这意味着,如果你有10,000个连接,该循环有可能会让你整个应用程序慢如蜗牛,具体取决于每次循环需要多长时间。每个请求必须分享在主线程中的一段时间,一次一个。
这个整体概念的前提是I/O操作是最慢的部分,因此最重要是有效地处理这些操作,即使意味着串行进行其他处理。这在某些情况下是正确的,但不是全都正确。
另一点是,虽然这只是一个意见,但是写一堆嵌套的回调可能会令人相当讨厌,有些人认为它使得代码明显无章可循。在Node代码的深处,看到嵌套四层、嵌套五层、甚至更多层级的嵌套并不罕见。
我们再次回到了权衡。如果你主要的性能问题在于I/O,那么Node模型能很好地工作。然而,它的阿喀琉斯之踵(译者注:来自希腊神话,表示致命的弱点)是如果不小心的话,你可能会在某个函数里处理HTTP请求并放置CPU密集型代码,最后使得每个连接慢得如蜗牛。
真正的非阻塞:Go
在进入Go这一章节之前,我应该披露我是一名Go粉丝。我已经在许多项目中使用Go,是其生产力优势的公开支持者,并且在使用时我在工作中看到了他们。
也就是说,我们来看看它是如何处理I/O的。Go语言的一个关键特性是它包含自己的调度器。并不是每个线程的执行对应于一个单一的OS线程,Go采用的是“goroutines”这一概念。Go运行时可以将一个goroutine分配给一个OS线程并使其执行,或者把它挂起而不与OS线程关联,这取决于goroutine做的是什么。来自Go的HTTP服务器的每个请求都在单独的Goroutine中处理。
此调度器工作的示意图,如下所示:

这是通过在Go运行时的各个点来实现的,通过将请求写入/读取/连接/等实现I/O调用,让当前的goroutine进入睡眠状态,当可采取进一步行动时用信息把goroutine重新唤醒。
实际上,除了回调机制内置到I/O调用的实现中并自动与调度器交互外,Go运行时做的事情与Node做的事情并没有太多不同。它也不受必须把所有的处理程序代码都运行在同一个线程中这一限制,Go将会根据其调度器的逻辑自动将Goroutine映射到其认为合适的OS线程上。最后代码类似这样:
func ServeHTTP
(
w
http
.
ResponseWriter
,
r
*
http
.
Request
)










