NeuroPower是一个在线的用来帮助神经科学研究者来根据试验性数据(pilot data)帮助研究者确定即将要进行的任务态核磁实验达到一定统计功效(power)所需要的样本数量(sample size)的统计工具(其实不应该只是任务态,但目前该网站明确指出只支持任务态,但确实有后续更新计划)。
近年来,fMRI研究结果的可重复性受到诸多质疑,我认为最顶峰的一次质疑就是在《Cluster failure: Why fMRI inferences for spatial extent have inflated false-positive rates》(Eklund, Nichols, & Knutsson, 2016)这篇文章发表于PNAS后。虽然这篇文章所针对的是fMRI研究中的统计方法的使用,尤其针对cluster(团块/簇)水平的多重比较矫正方法的使用。但是类似的争议在fMRI研究的可重复性争论中还表现在对小样本量的power的估计不足等方面。同时由于小样本量带来的power的不足在一定程度上也影响了fMRI基于假设检验(主要是参数检验)在多重比较矫正方面出现的一些问题(在上述文章发表后,中科院心理所严超赣研究员等人在HUMAN BRAIN MAPPING杂志上发文对cluster水平的矫正方法进行了检验,他们提出的导致cluster水平矫正出现问题的其中一个原因就在于样本量的问题,Chen, Lu, & Yan, 2018)。尽管这些研究都是基于静息态的数据所做,但是任务态研究也同样面临着这样的问题。
在早期读到的一些论文中,很多样本量在10左右的文章仍旧使用基于T分布假设或者F分布假设的参数检验来进行统计分析,然而这并不符合这些假设检验对构造相应分布所需样本量的要求,同时这些数据也并未报告其Effect size(这在某种程度上可以反应power大小),导致一些研究结果难以得到重复。因此,在实验研究前,根据实验设计以及需要达到的power和一些统计参数来估计样本量是重要的。
那么使用行为学实验中常用的G-power等工具来计算可行吗?老实说我并不清楚,但是fMRI数据有其特殊性,首先其单个被试所获得的数据是巨量的,基于volume的数据收集和统计思想让fMRI数据处理面对着对基于voxel或cluster的多重比较问题,我觉得这个问题应该是行为学测量与fMRI测量间一个重大的区别吧,这一点在NeuroPower这个工具中也有体现。因此,术业有专攻,我认为还是应当使用NeuroPower来估计fMRI(目前只用于task-fMRI)实验中应当收集的样本量。
NeuroPower 是一个在线工具包,想使用它必须要在该网站上进行设置,
网站
(
可点击文末阅读原文跳转
)
首页如下:
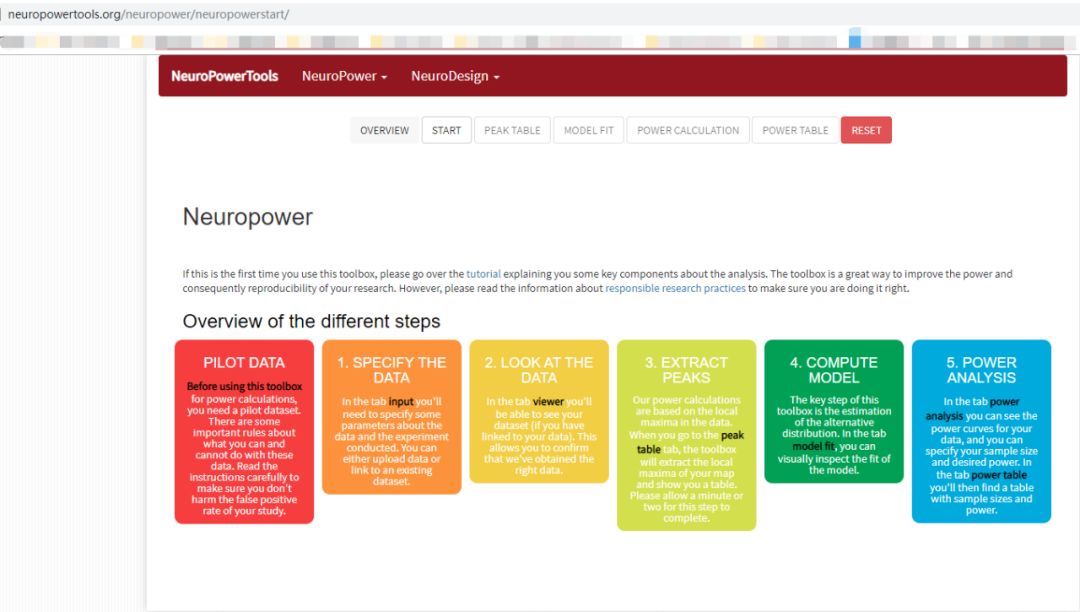
在这个界面中,可以看到使用NeuroPower的步骤,一共是分为5步骤,分别是数据参数设置、查看试验性数据结果、提取数据激活显著值表、估计模型以及最后的power求解。
对于这个工具而言,最重要的在于第一步,即数据参数设置。
这里的设置共有两个部分,第一个部分是pilot数据,即试验性数据,第二个部分是你自己假定的检验区域(mask)。
Pilot数据一般有三种来源,第一种是你自己做的试验性实验,可以理解为预实验;
第二种是open data,即共享开源的数据;
第三种是你自己以前做的实验。
一般来说,做预实验是代价较大的,毕竟核磁机昂贵,你希望自己的实验的每一个样本都是有效数据,同时,由于预实验的样本量本就很小,将其作为pilot data 可能效果并不好。
所以可选择的一般是后两种,第一种是类似的实验设计的开源数据库的实验,假设你的实验是只有一个组间因素的设计,将使用两样本T检验来进行统计检验。那么你可以在开源数据库中寻找到一个类似的实验设计的数据来作为pilot data。第二种是你自己以前所做的实验设计,你利用以往自己做的类似的研究数据作为pilot data。其实这种思路和第二种一致,只是数据来源更便利。那么去哪里寻找pilot data呢?
Andrew Jahn
博士推荐了一个网站——https://neurovault.org/,在这个网站里可以找
到你需要的实验设计的数据。这里的数据基于多种来源,你可以看到来自于fMRI 1000数据库的数据等等,同时这里的数据都是发表文章的数据,你可以追溯到这些数据的来源。
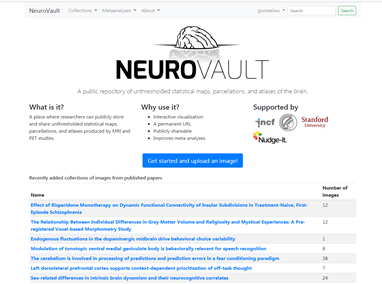
在这个网站下载需要的数据不需要注册,只需要点击左上角的collection,然后选择see all collection即可。
就像图示这样!

然后在搜索框中搜索自己需要的特定的设计或者主题的数据即可(如下图)。
在这里我有两点自己的疑问和对这种疑问的理解性回答和大家分享,也希望大家能有讨论。
第一个问题是,设计的主题(如是研究注意还是语言这样的研究对象问题)是否需要相关。
从我对G-power和这里NeuroPower设计的方式来理解,核磁实验设计(以下提到的设计特指因素设计或参数设计这样的实验设计因素,不是具体的block或event的呈现方式选择)里由于涉及到不同的研究主题对其激活的脑区差异是有明显影响的。
因此,我认为这里确实要考虑你自己实验研究的中心内容(即主题)是否与pilot data一致。
我认为应该要找到尽量一致的主题,例如你的研究主题是语言,那简单的运动感觉研究应该是不能作为pilot data的。
在核磁数据里有这样的疑问是因为研究问题的主题差异会有明显的脑区激活差异(例如视觉加工和运动加工的脑区差异),因此不同主题可能是会对active region有影响的。
而NeuroPower也明显考虑到了这个问题,因此有一个可以自己设定假定的检验区域(mask)的选项,这里也就是我在前文说到的第二个部分。
既然NeuroPower有这样的考虑,我觉得我们应该根据自己的研究设计(即因素设计还是参数设计)以及研究主题来寻找合适的公开数据作为pilot数据,我认为主题相关是更好的,因为在NeuroPower的第二步中,如果你选择的mask和你放入的pilot数据激活的结果之间没有重合的脑区,你是看不到第二步的激活peak的表格的。
但是高级复杂加工往往是全脑多区域的,尤其是联合皮质,因此我认为假如你研究语义,实在找不到语义主题的和你类似的实验设计,用研究句法的应该也可以(当然这也是语言研究中的一个争议焦点)。
第二个问题是,在NeuroPower里只提供T map和Z map的统计图选项
,同时统计方式也只提供了单样本T和独立样本T(即两样本T),因此在选择的时候假如你设计的是两因素多水平,只有F map时该怎么办。鉴于SPM是基于GLM来进行统计检验的,因此组间因素的F检验其实是可以通过两样本T来检验其组别主效应的,因此我认为两因素设计的实验的组间因素的两样本T同样可以作为你的pilot data的统计图来源。
在这里,有一个需要注意的点是不同设计的power是不一样的,这确实是一个需要关注的问题。
因此,这里对你所关注的实验结果以及你的统计知识就有一定的要求。
我这里的两因素是一个组内因素,一个组间因素。
我之所以使用组别的T map是因为我的两组被试是不同的人群,我更在意他们的组间差异。
如果你更加在意交互作用,在GLM中使用T检验也可以一定程度上实现交互效应的检验,如果你使用的是SPM,那只要设置合适的比较矩阵即可。
因此,找到合适自己实验设计(即单因素还是多因素设计,是否更关注交互作用)的pilot data是极为重要的。
因此基于对这两个问题的思考,我认为在这里寻找你想要的pilot data时应该基于自己的实验设计以及研究主题来共同建立关键词进行搜索。
在寻找到合适的数据后,就可以选择这个数据来作为pilot data。
然后这里就要求你明白NeuroPowe第一步需要输入哪些参数了,以便于你在寻找到的这个pilot data中找到足够的信息来输入。
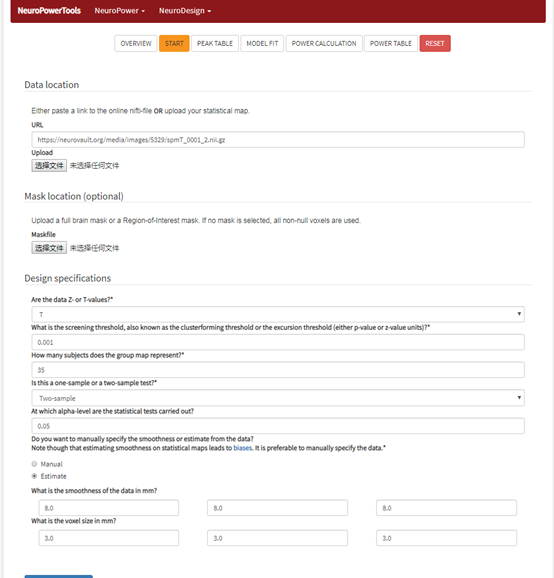
在NeuroPower界面,点击START就可以看到数据设置的界面了。
在这个界面输入的信息如我之前所说,共两个部分。
一个是pilot data 需要输入的一些统计参数,还有一个是你自己想要进行的统计区域的mask。
・第一行是输入pilot data 的数据的,可以是一个URL链接,也可以upload一个具体的数据(必须是nii数据)。
・第二行是自己想要进行统计区域的mask,这里也可以不填。
系统会默认是全脑作为统计检验区域。
・第三行要输入pilot data 的统计图值是z值还是T值,只有这两个选项。
・第四行是该数据卡的第一刀,虽然这里写了cluster forming,但从网站对这里的描述以及Andrew Jahn的讲解看,其实是voxel水平的假阳性阈值。
因为在网站里用来举例的spm一般是0.001,FSL一般为Z>2.3(fsl这里卡的其实是p为0.01)这两个常用值。
这也符合在最后power估计要使用的基于随机场理论进行矫正的矫正方法估计里应该要卡的第一刀的逻辑。
・第五行是pilot数据的被试数量。
・第六行是让你选择你所用的pilot数据是什么样的检验方法的统计结果图。
・第七行是设定alpha水平,这里设定一般是0.05,也就是我们所说的cluster水平的阈值(无论是family wise error control还是false discover error wise control 都要卡两刀)。
・第八行对平滑核进行估计,这一步可以选择手动设置还是估计,网站推荐的是手动输入,这里可以看pilot 数据来源,文章中都会交代它所使用的高斯平滑核的半高宽,同时也交代它的体素大小(即voxel小立方体的大小)。
这里就把数据设定好了,然后就点击submit。
图中我是在neurovault网站里选择了一个两样本T的结果统计图放入其中的。
上面已经解释了在NeuroPower的第一步我们要输入什么,下面解释一下这些数据在neurovault网站里该怎么寻找。
我这里找到是一个go/no go的奖赏实验,这是一个两因素两水平,一个组间因素,一个组内因素。
和我的设计相同(但它这里的分组其实两组人是属于随机入组设计的,和我研究设计还是不一样的,这里只作为使用演示),我选择了组间比较的T统计条件来作为我的pilot data。
如下面第一张图红色框选中的,点击它进去后看到下述第二张图。
在这张图的下方有很多信息,包括第一个选中红色框:
统计类型。
第二个:
该图片的URL地址;
第三个:
被试数量。
剩下的还有一个必要的参数就是平滑核大小和体素大小了,这个就需要去这篇论文中寻找。
这样,所有我们需要的参数就都有了。
去NeuroPower里填入后就可以submit了。
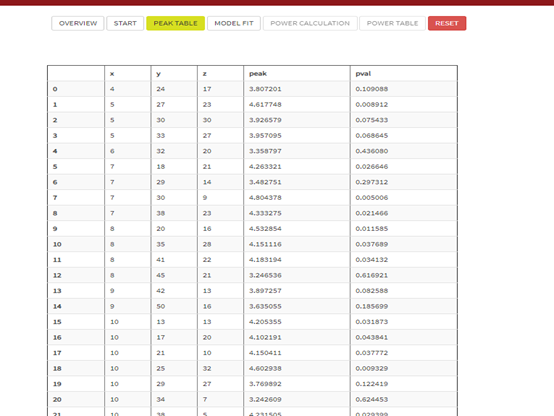
在提交后,会跳入第二步。也就是看到激活信息的table,像下图一样。这里有MNI坐标,这里的坐标之所以是MNI坐标是因为我的pilot data 是配准至MNI坐标的。这里你可以看有没有你自己的实验里感兴趣的激活区域。然后就可以点击MODEL FIT来进行模型估计。
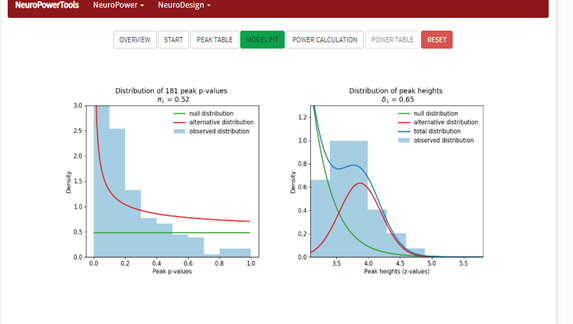
在模型估计后,会出现下面这个模型估计的曲线评估。
这个地方Andrew说他不是很懂,同时网站里也没什么具体说明,因此我也不太清楚。
但是他指出只要这里的红色线,也就是估计出来的分布和观察到的分布(即蓝色的区域)有比较好的fit就可以继续下去了,怎么评估fit的好坏呢,从红色线的走势是不是能够保持在蓝色区域内来看。
从我的图来看,还是可以继续的。
所以我就点击了最后一步,POWER calculation。
 点击以后就会看到下面这张图,右边的曲线分别代表的是进行不同的多重比较矫正时不同power下的被试数量。
一共是三种,包括Bonferroni矫正(最严格的了)、基于随机场理论的矫正(如GRF、Alphsima等)以及不矫正三种方式。
可以发现,不矫正时想要达到较高的power是需要更大的sample size的,而当样本量更大时,矫正方法对于power的影响会趋于一致。
点击以后就会看到下面这张图,右边的曲线分别代表的是进行不同的多重比较矫正时不同power下的被试数量。
一共是三种,包括Bonferroni矫正(最严格的了)、基于随机场理论的矫正(如GRF、Alphsima等)以及不矫正三种方式。
可以发现,不矫正时想要达到较高的power是需要更大的sample size的,而当样本量更大时,矫正方法对于power的影响会趋于一致。










