今天继续来分析爬虫数据分析文章,一起来看看网易严选商品评论的获取和分析。
警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系萝卜删除!!!
声明:这是一篇超级严肃的技术文,超!级!严!肃!请本着学习交流的态度阅读,谢谢!

网易商品评论爬取
分析网页
评论分析
进入到网易严选官网,搜索“文胸”后,先随便点进一个商品。
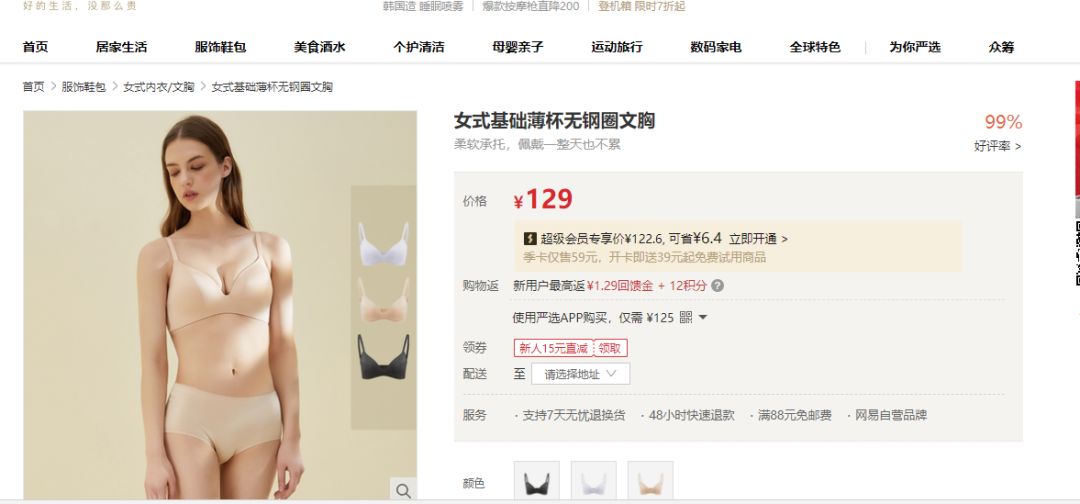
在商品页面,打开 Chrome 的控制台,切换至 Network 页,再把商品页面切换到评价标签下,选择一个评论文字,如“薄款、穿着舒适、满意”,在 Network 中搜索。
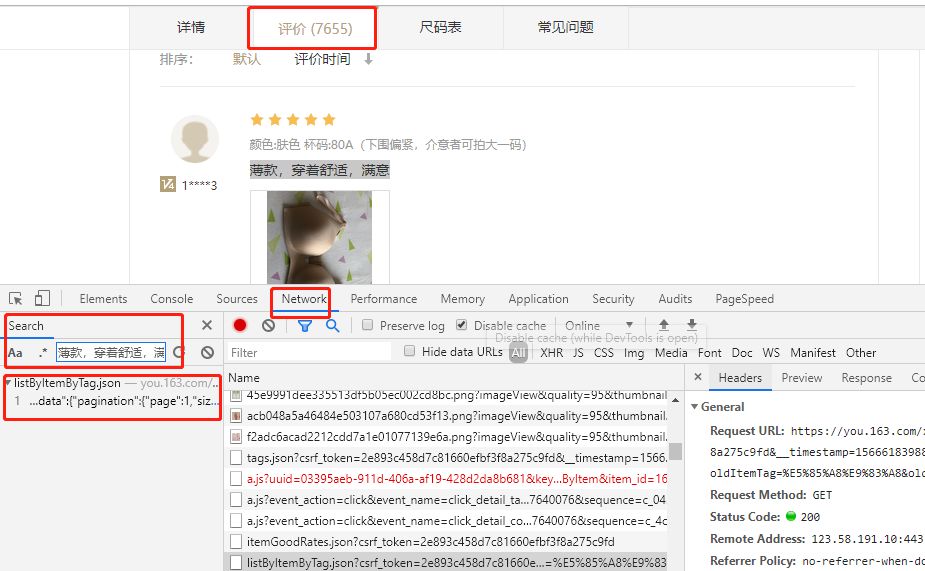
可以发现,评论文字是通过 listByItemByTag.json 传递过来的,点击进入该请求,并拷贝出该请求的 URL:
https://you.163.com/xhr/comment/listByItemByTag.json?csrf_token=060f4782bf9fda38128cfaeafb661f8c&__timestamp=1571106038283&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
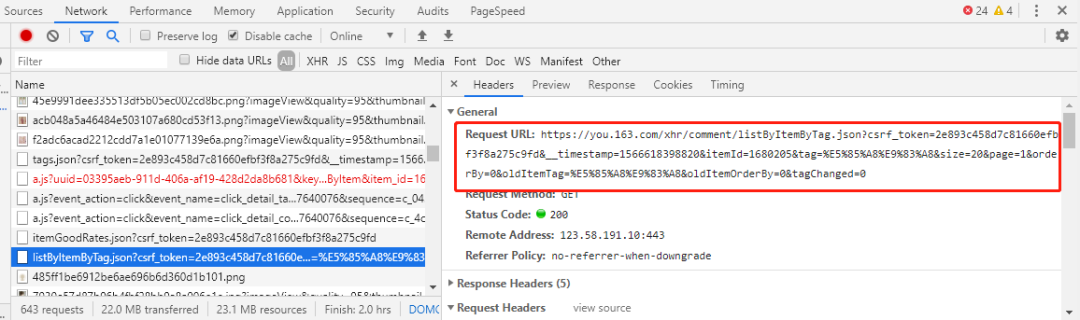
将该 URL 放入 Postman 中,逐个尝试 url query params,最后能够发现,只需保留 itemId 和 page 两个请求参数即可。

请求返回的是一个 JSON 格式的数据,下面就是分析该 JSON 数据了。
不难发现,所有的评论数据都存储在 commentList 中,我们只需保存该数据即可。
下面就是如何获取 itemId 的信息了,这个是产品的 ID,我们回到网易严选首页,继续分析。
产品 ID 获取
当我们在搜索框中输入关键字进行搜索的时候,同样能够发现在 Network 中有很多请求,此时可以观察各个请求,通过请求文件的名称(此处需要一些经验,守规矩的程序员都不会乱起名字),我们可以定位到搜索时展示搜索结果的请求。
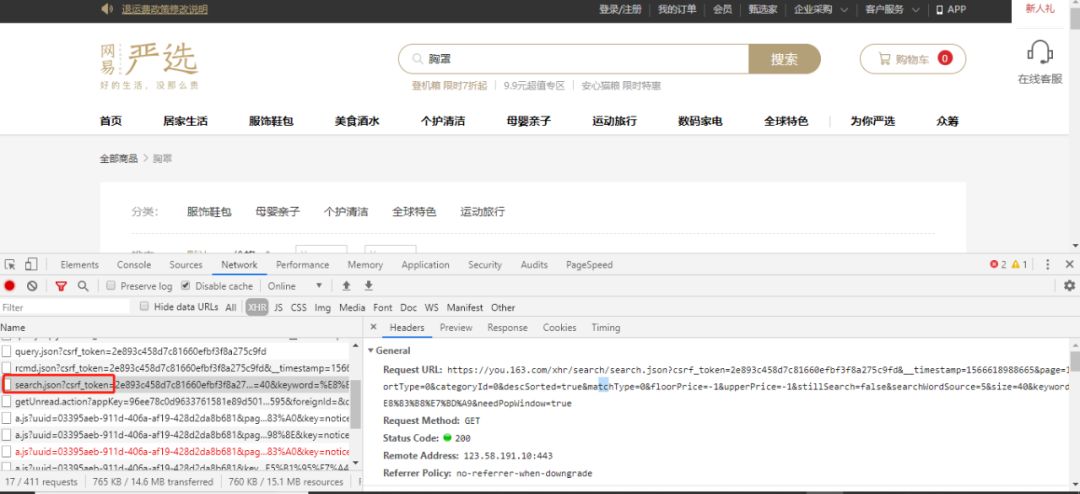
搜索一般都是 search,所以我们就锁定了这个 search.json 的请求。
同样把请求 URL 拷贝到 Postman 中,逐个验证传参,最后保留 page 和 keyword 两个参数即可。
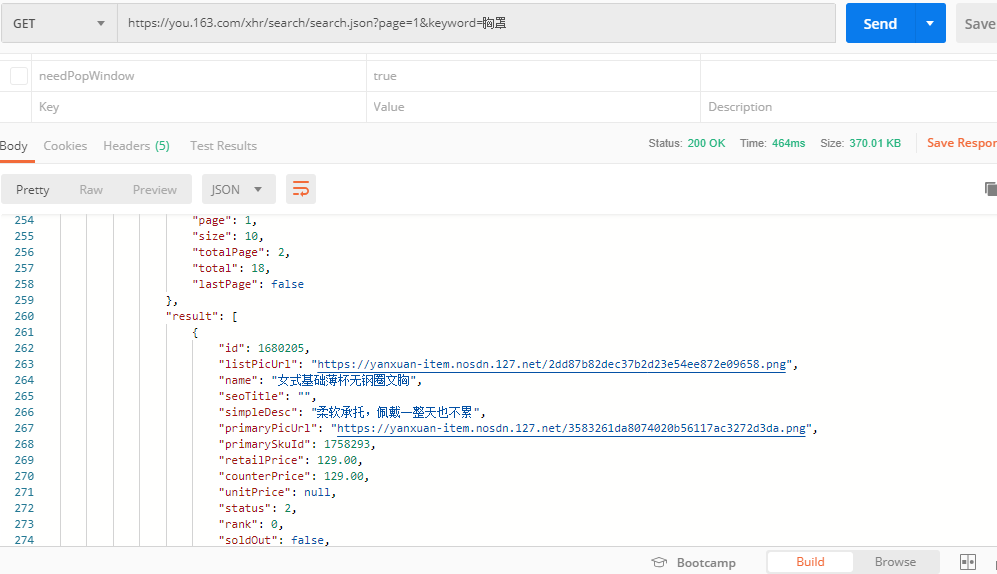
该请求返回的数据较多,还是需要耐心的分析数据,也能够发现,在 result->data->directly->searcherResult->result 下面的 id 值,即为我们要获取的产品 ID。
以上,我们基本完成了前期的分析工作,下面开始代码的编写。
编写代码
获取产品 ID
def search_keyword(keyword):
uri = 'https://you.163.com/xhr/search/search.json'
query = {
"keyword": keyword,
"page": 1
}
try:
res = requests.get(uri, params=query).json()
result = res['data']['directly']['searcherResult']['result']
product_id = []
for r in result:
product_id.append(r['id'])
return product_id
except:
raise
我这里是获取了 page 为 1 的产品 ID,下面就是通过产品 ID 来获取不同产品下的评论信息。
通过前面的分析,我们可以知道,评论信息都是如下形式的,对这种形式的信息,我们可以很方便地存储进入 MongoDB,然后再慢慢分析数据里的内容。
{
"skuInfo": [
"颜色:肤色",
"杯码:75B"
],
"frontUserName": "1****8",
"frontUserAvatar": "https://yanxuan.nosdn.127.net/f8f20a77db47b8c66c531c14c8b38ee7.jpg",
"content": "质量好,穿着舒服",
"createTime": 1555546727635,
"picList": [
"https://yanxuan.nosdn.127.net/742f28186d805571e4b3f28faa412941.jpg"
],
"commentReplyVO": null,
"memberLevel": 4,
"appendCommentVO": null,
"star": 5,
"itemId": 1680205
}
对于 MongoDB,我们既可以自己搭建,也可以使用网上免费的服务。
在这里我介绍一个免费的 MongoDB 服务网站:
mlab,使用很简单,就不过多介绍使用过程了。
数据库有了,下面就是把数据保存进去了。
def details(product_id):
url = 'https://you.163.com/xhr/comment/listByItemByTag.json'
try:
C_list = []
for i in range(1, 100):
query = {
"itemId": product_id,
"page": i,
}
res = requests.get(url, params=query).json()
if not res['data']['commentList']:
break
print("爬取第 %s 页评论" % i)
commentList = res['data']['commentList']
C_list.append(commentList)
time.sleep(1)
try:
mongo_collection.insert_many(commentList)
except:
continue
return C_list
except:
raise
最后爬取完成之后,总共是七千多条数据,下面就可以根据个人需要做一些分析了。
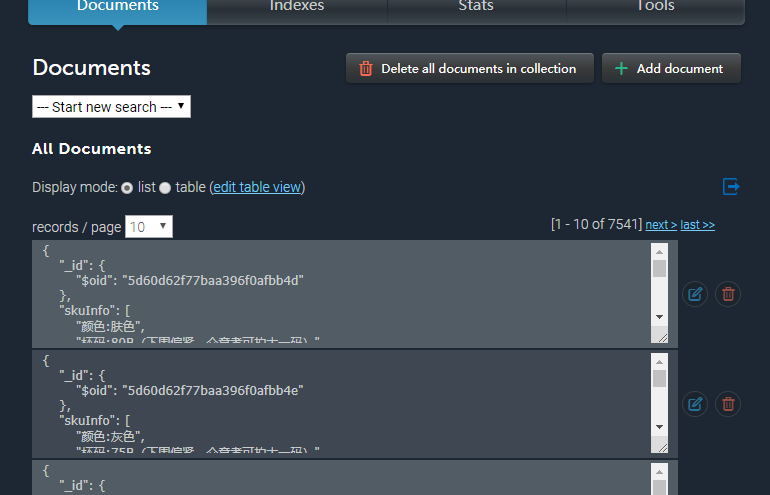
爬取的数据 MongoDB 链接
conn = MongoClient("mongodb://%s:%[email protected]:49974/you163" % ('you163', 'you163'))
db = conn.you163
mongo_collection = db.you163
商品评论数据分析
下面就到了激动人心的时刻了,一探妹子偏好!
偏好颜色










