李林 编译整理
量子位 报道 | QbitAI 出品
今天,马斯克和YC总裁Altman等创办的人工智能非营利组织OpenAI,发布了DQN及其三个变体的TensorFlow实现,以及根据复现过程总结的强化学习模型最佳实现方法。
以下是OpenAI博客文章的主要内容,量子位编译:
我们宣布开源OpenAI Baselines,这是我们内部对发表论文的复现,结果能与论文所公布的相媲美。今天要发布的,包括DQN和它的三个变体。接下来的几个月里,我们将继续发布这些算法。
复现强化学习的结果并非易事:模型的性能有很多噪声、算法的活动件可能包含微小的bug、很多论文也没有写明复现所需的所有技巧。要正确地实现一个强化学习模型,往往需要修复很多不起眼的bug。
我们计划发布一些效果良好的实现,并写明完成这些实现的过程,借此来确保明显的RL进步,不是与现有算法的错误版本或未经微调的版本进行比较得来的。
最佳方法
与随机基准相比
下图中的agent,正在游戏H.E.R.O.中进行随机行动,如果你在训练早期看见这样的行为,很可能相信agent正在学习。所以,你总是应该验证自己的agent是否比随机行动更强。
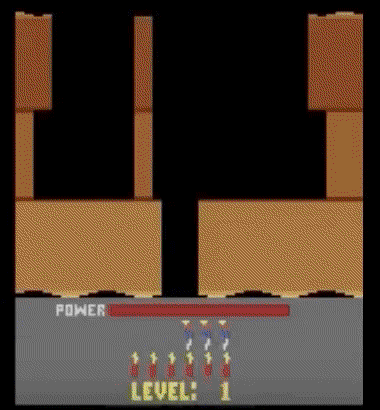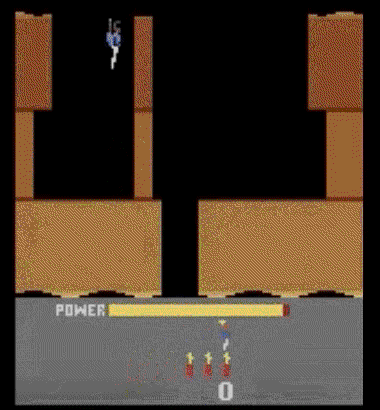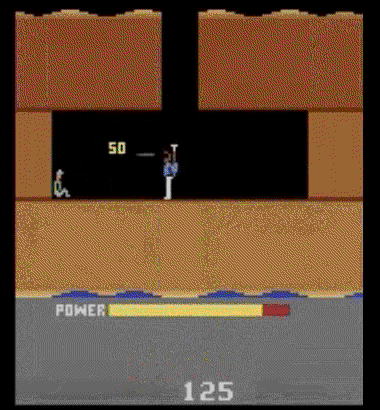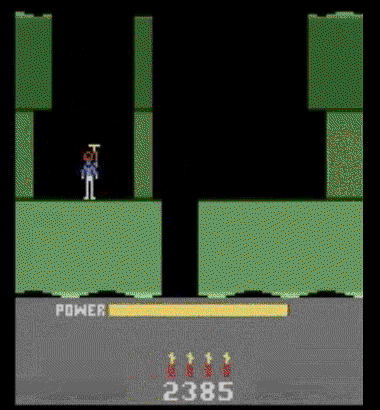
警惕不严重的bug
我们看了十个流行的强化学习算法复现的样本,其中六个有社区成员发现提交,并获得作者确认的微小bug。
这些bug有的非常轻微,有的是忽略了梯度,有的甚至会虚报得分。
从agent的角度看世界
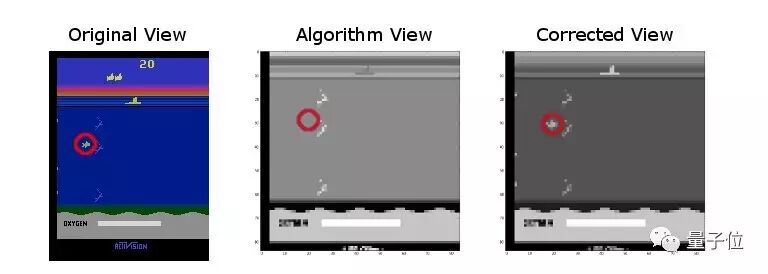
和大多数深度学习方法一样,我们在训练DQN时,也会将环境图像转换为灰度,以降低计算量。这有时候会带来bug。我们在Seaquest上运行DQN算法时,发现自己的实现表现不佳。当我们检查环境时,发现这是因为处理成灰度的图像上根本看不见鱼,如下图所示。
△
游戏Seaquest的三个图像。左图显示原始图像,中间显示已经转换为灰度的版本,鱼不见了,右侧显示经调整让鱼可见的的灰度版本。
当将屏幕图像转换为灰度图像时,我们错误地调整了绿色值的系数,导致鱼的消失。在注意到这个bug之后,我们调整了颜色值,就又可以看见鱼了。
为了将来能调试这样的问题,我们的强化学习工具包gym现在有播放功能,让研究者轻松地看到与AI agent相同的观察结果。
修复bug,然后调整超参数
bug修完,就该开始调整超参数了。我们最终发现,为控制探索率的超参数epsilon设定退火程序对性能有很大的影响。我们的最终实现方法在前100万步中将epsilon降至0.1,然后在接下来的2400万步中降至0.01。如果我们的实现有bug,就可能会为了应对没有诊断出的错误,而提出不同的超参数。
仔细检查你对论文的解读
在Nature上发表的DQN论文中,作者写道:
We also found it helpful to clip the error term from the update […] to be between -1 and 1.
这句话有两种解释:一是裁剪目标,二是在计算梯度时裁剪乘法项。前者似乎更自然,但是一个DQN实现显示,它会导致次优性能。所以说,后者才是正确的,有一个简单的数学解释:胡伯损失。你可以通过检查梯度是否符合预期,来发现这些错误,用TensorFlow的compute_gradients命令就能轻松完成。
文章中提到的大多数错误都是通过多次遍历代码,并思考每行可能出错的情况发现的。每个bug在事后看起来都是显而易见的,但是即使是经验丰富的研究人员,也会低估检查多少遍代码中,才能找到实现中的所有错误。
Deep Q-Learning
我们的实现基于Python 3和TensorFlow。今天发布的实现包括DQN和它的三个变体:
DQN
:强化学习算法,将Q-Learning与深层神经网络结合起来,使强化学习适用于复杂,高维度的环境,如视频游戏或机器人。
Double Q Learning:
修正了传统DQN算法有时会高估与特定行为相关价值的趋势。
Prioritized Replay:
通过在真正的奖励与预期奖励明显不同时学习重播记录,来扩展DQN的经历重播功能,让agent在做出不正确假设时进行调整。
决斗DQN(Dueling DQN):
将神经网络分为两个,一个学习提供每个时间步长值的估计,另一个计算每个动作的潜在优势,两个组合为一个action-advantage Q function。
GitHub地址:
https://github.com/openai/baselines
基准
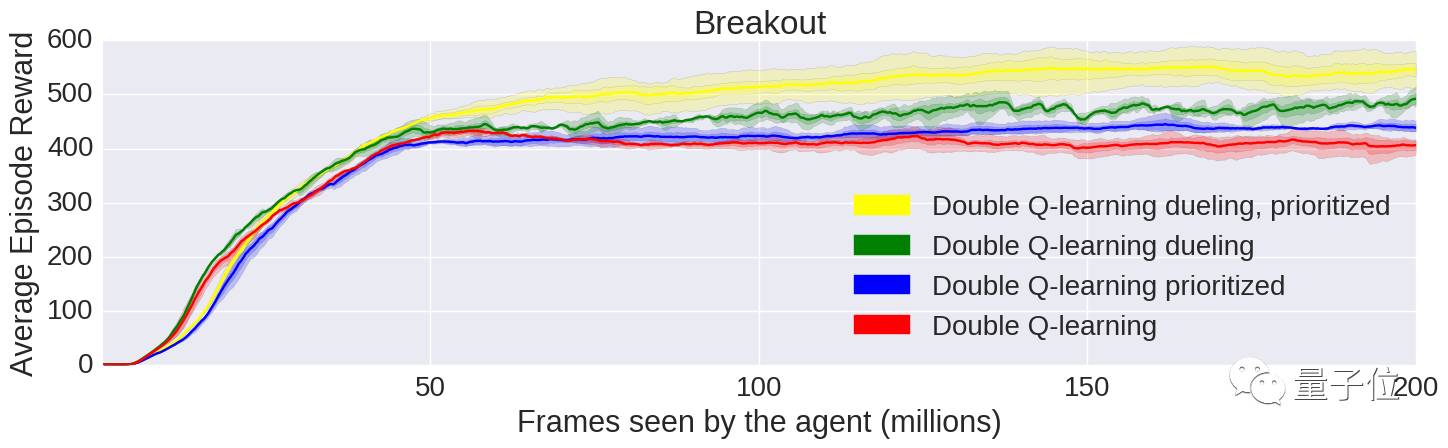
我们提供一个iPython笔记本,显示了我们的DQN实现在Atari游戏上的性能。上图是各种算法的性能比较。
IPython笔记:
https://github.com/openai/baselines-results/blob/master/dqn_results.ipynb
【完】
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
One More Thing…
今天AI界还有哪些事值得关注?在量子位(QbitAI)公众号对话界面回复“今天”,看我们全网搜罗的AI行业和研究动态。笔芯~
另外,欢迎加量子位小助手的微信:qbitbot,如果你研究或者从事AI领域,小助手会把你带入量子位的交流群里。
△
扫码强行关注『量子位』
追踪人工智能领域最劲内容





