板块配置上我们持续推荐拐点较大,业绩持续兑现的信创方向。
2021
年招标体量较大,且
2020
年有部分收入延迟到
2021
年确认,因此
2021
年相关企业的收入有望达到翻倍以上,招标驱动相关公司股价继续反弹,推荐景嘉微、东方通、中国长城、中国软件、太极股份、神州数码,关注中科曙光、中孚信息等。其次我们推荐景气度高、估值便宜的网络安全,推荐奇安信、启明星辰、绿盟科技、安恒信息,关注深信服等;云计算方面,企业数字化国产化需求持续高景气,竞争格局逐渐清晰,龙头加速受益,标的上推荐:用友网络、金山办公、广联达,关注明源云、金蝶国际等。
GPU
赛道持续高景气度,未来
7
年复合增速超
30%
。
GPU
被广泛用于游戏,高清显示,元宇宙,数据中心,车联网等领域,下游需求旺盛。根据
Verified Market Research
数据,
2020
年全球
GPU
市场价值为
254.1
亿美元,
2027
年有望达到
1853.1
亿美元,年平均增速高达
32.82%
。我们估算
2020
年中国大陆的独立
GPU
市场规模为
47
亿美元,
2027
年市场规模超过
346
亿美元。
国产
GPU
龙头景嘉微技术领先,
7
系产品推动芯片业务快速增长。
景嘉微是国内唯一一家实现国产
GPU
大规模商业化生产的
GPU
公司,技术完全自主研发,公司
2018
年推出的
7
系产品已经广泛应用于党政信创市场,截至
2021
年
8
月,我们预计
2021
年出货量市占率接近
100%
,出货量有望达到
300
万片,芯片业务收入可达
6
亿元以上,同比实现
700%
以上增长;我们预计
2022
年出货量超过
500
万片。
景嘉微新一代
9
系产品支持高性能计算、高清显示和游戏,
2023
年有望推出
AR/VR
、
AI
计算系列产品。
公司新一代
9
系芯片有望
2021
年下半年推出,
9
系相对
7
系制程从
28nm
提升到
14nm
,应用领域从图形显控拓展到高性能计算,同时显控能力大幅提升可以支持
3D
显示和
4k
游戏;
GPU
产品有望从信创领域拓展到民品市场,打开新的市场空间。
2. GPU是什么
GPU
最初是为了更好的做图形处理而专门设计的微处理器。
GPU
的全称是
GraphicsProcessing Unit
,图形处理单元。它最初的功能主要用于绘制图像和处理图元数据的特定芯片,后来增加了许多其他功能。
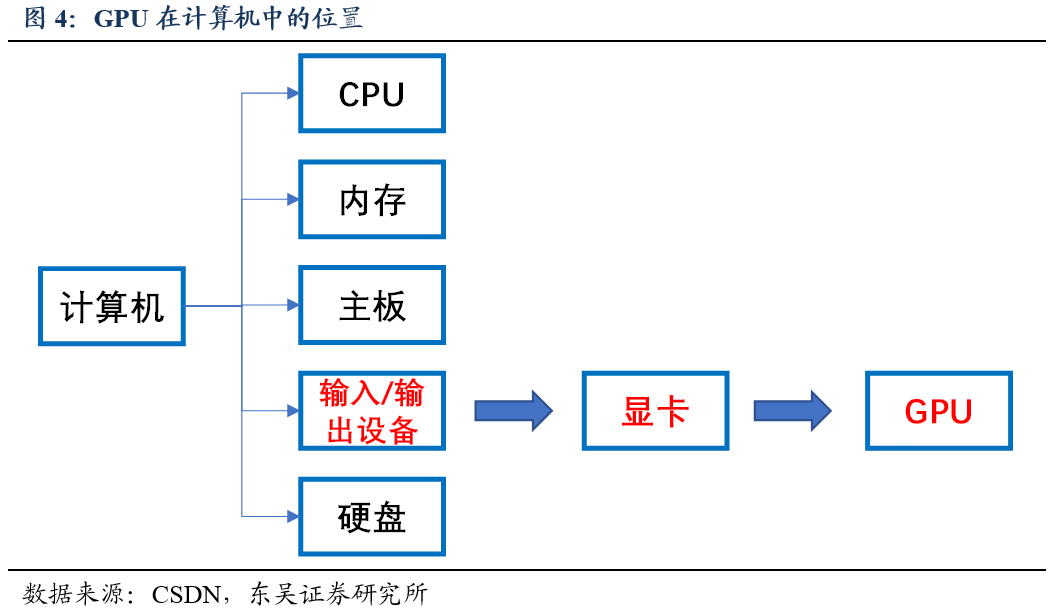
GPU
是显卡最核心的部件。
显卡(显示接口卡),负责把
CPU
(
CentralProcessing Unit
,中央处理器)送来的影像数据(显示信号)处理成显示器可以认知的格式(一般电器信号),再送到显示屏上形成影像。
GPU
就是显卡的核心,决定如何处理屏幕上的每个像素点。显卡里除了
GPU
外,还有散热器、通讯元件、与主板和显示器连接的各类插槽。
3
. GPU的工作原理
GPU
将
3D
图形映射到相应的像素点上,对每个像素进行计算,确定最终颜色并完成输出。
其中工作内容包括:
1
)
顶点处理
,
GPU
读取描述
3D
图形外观的顶点数据,并根据顶点数据确定
3D
图形的形状及位置,建立
3D
图形骨架。
2
)
光栅化
,显示器实际显示的图像是由像素点组成的。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,把一条线段转化为阶梯状的连续像素点。
3
)纹理贴图
,顶点单元生成的多边形只构成了
3D
物体的外轮廓,纹理贴图将多边形的表面贴上相应的图片,从而生成完整的
3D
图形。
4
)最终
输出
,由
ROP
(光栅化引擎)最终完成像素的输出,
1
帧图像渲染完毕后,被送到显存帧缓冲区。
GPU
比
CPU
擅长并行计算。
正如上段所说,一个
3D
图形最终会被分解为许多个像素点来计算,如果要渲染速度快,这就要求
GPU
的硬件结构是满足同时进行大量的简单计算的,这个需求导致了
GPU
与
CPU
的硬件架构不同。从芯片设计思路看,
CPU
是以低延迟为导向的计算单元,通常由专为串行处理而优化的几个核心组成,而
GPU
是以吞吐量为导向的计算单元,由数以千计的更小、更高效的核心组成,专为并行多任务设计。微架构的不同最终导致
CPU
中大部分的晶体管用于构建控制电路和缓存,只有少部分的晶体管完成实际的运算工作,功能模块很多,擅长分支预测等复杂操作。
GPU
的流处理器(承担简单计算任务)和显存控制器占据了绝大部分晶体管,而控制器相对简单,擅长对大量数据进行简单操作,拥有远胜于
CPU
的强大浮点计算能力,从而更擅长并行计算,比如图像处理计算,物理仿真,深度学习等。

4
. GPU
发展史:从固定功能到统一渲染架构
4
.1.
2000
年之前:固定功能架构时代
一切的开端,计算图形学。
1962
年,麻省理工大学的博士伊凡·苏泽尔的论文以及他的画板程序奠定了计算机图形学的基础。
1962-1984
年,这一阶段,没有专门的图形处理硬件,图形处理任务都由
CPU
完成。
萌芽时期,专门的图形处理硬件出现。
随着计算机的发展,图像处理需求逐步增加。
1984
年,美国
SGI
公司推出了面向专业领域的高端图形工作站。
1984-1995
年,
SGI
又不断研发出了一系列性能更好的图形工作站。但由于价格昂贵,无法面向消费级市场。在消费级领域,还没有专门的图形处理硬件。
茁壮成长,消费级显卡出现,图形处理硬件发展加速。
1995
年,
3DFX
公司发布一款消费级
3D
显卡
Voodoo
。此时,图形显示硬件赛道已经开始变得火热,
AMD
、
ATI
(
2006
年被
AMD
收购)、
NVIDIA
都开始推出自己的显卡产品。
CPU
得以摆脱部分图形处理任务,但是顶点变换等任务仍需
CPU
完成。
GPU
时代来临。
1999
年
NVIDIA
发布的
GeForce 256
图形芯片,首次引入
GPU
的概念,
GPU
时代来临。
GeForce 256
采用了“
T&L
”硬件,立方环境材质贴图和顶点混合等先进技术。
此阶段为固定功能架构时代。
在这一时期,各硬件单元形成一条图形处理流水线,每个流水级功能固定,硬化了一些给定的函数,多条像素流水线对各自的输入数据进行相同的操作,不可对硬件进行编程。
4
.2. 2001-2005年:分离架构渲染时代
GPU
具备了可编程属性。
GPU
用顶点渲染器替换了变换与光照相关的固定单元、用可编程的像素渲染器替换了纹理采样与混合相关的固定单元。
2003
年,
NVIDIA
和
ATI
发布的新产品都同时具备了可编程顶点处理和可编程像素处理器,具备了良好的编程性。
顶点渲染器和像素渲染器在硬件上相互分离。
顶点渲染器和像素渲染器在物理上是两部分硬件,不可相互通用,这个时期叫做分离渲染架构时代。
GPU
开始采用统一渲染架构。
传统的
GPU
采用分离架构,顶点处理(由
Vertex Shader
硬件单元完成)和像素处理(由
Pixel Shader
硬件单元完成)在硬件上相互分离,于是,当
GPU
核心设计完成时,
PS
和
VS
的数量便确定下来了。但是不同的游戏对于两者处理量需求是不同的,这种固定比例的
PS VS
设计显然不够灵活。为了解决这个问题,
DirectX10
规范中提出了统一渲染架构。在统一渲染架构中,
PS
单元和
VS
单元都被通用的
US
单元所取代,
NVIDIA
的产品中称其为
SP
(
Streaming Processer
),即流处理器,这种
US
单元既可以处理顶点数据,又可以处理像素数据,因而
GPU
可以根据实际处理需求进行灵活的分配,这样便有效避免了传统分离式架构中
VS
和
PS
工作量不均的情况。
GPGPU
出现,功能从图形显示拓向高性能计算。
统一渲染架构的采用,
GPU
硬件单元更加灵活,进一步增强了
GPU
的可编程属性。大数据时代的到来,
GPU
并行计算的能力被进一步发掘,
GPU
被用于图形处理之外的其他领域,如人工智能、挖矿等,
GPGPU
(通用
GPU
,指利用处理图形任务的
GPU
来处理原本由中央处理器处理的通用计算任务)的概念开始出现。
GPU
厂商们洞察到了这一商机,也开始从硬件和软件上提供对
GPGPU
的专门支持。
NVIDIA
毫无争议是这一商机的首先发现者与推进者,伴随着
Tesla
系列
GPU
,
2006
年发布了
CUDA
软件平台,来支持
GPU
用于非图形处理的其他用途。
AMD
也不甘示弱,针对
FireStream
系列
GPU
,
2016
年发布了
ROCm
软件平台。
4
.4.
从NVIDIA Fermi
架构看GPU微观硬件架构组成
进入统一渲染架构时代后,
GPU
架构快速发展。
NVIDIA
的
GPU
架构历经多次变革,约
2
年更新一次。
NVIDIA
为了纪念物理学家,把每代
GPU
架构都用物理学家名字来命名:特斯拉(
Tesla
)、费米(
Fermi
)、开普勒(
Kepler
)、麦克斯韦(
Maxwell
)、帕斯卡(
Pascal
)、伏特(
Volta
)、安培(
Ampere
)。
2010
年发布的
Fermi
是第一个完整的
GPU
计算架构。
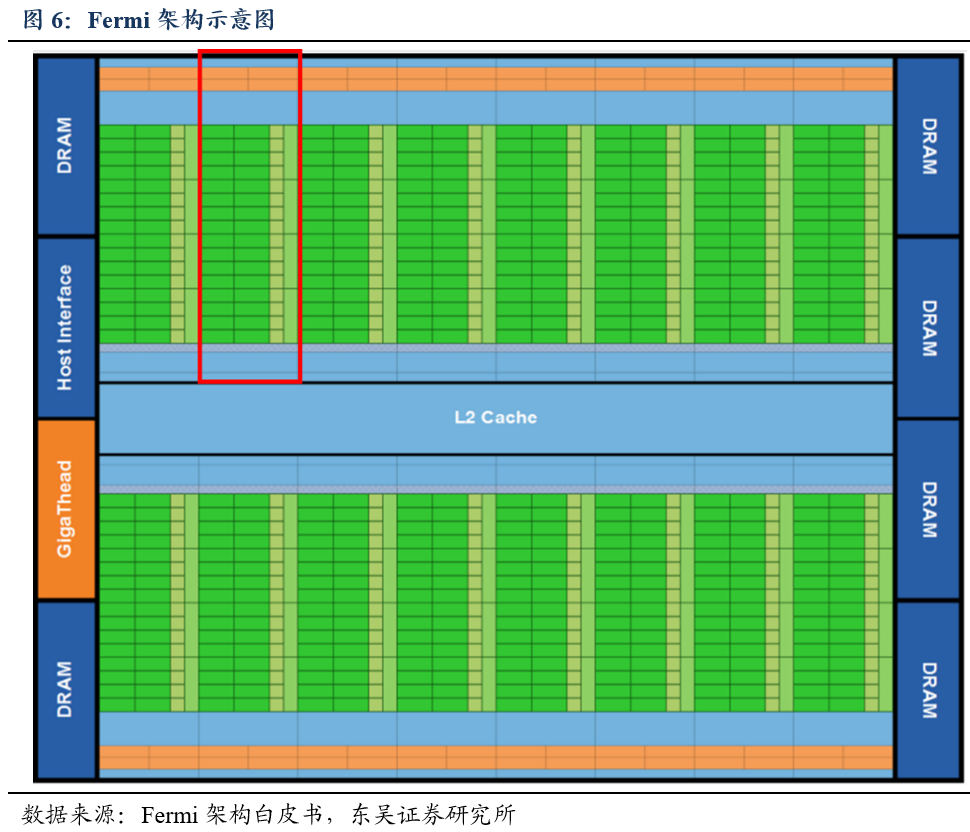
第一个基于
Fermi
架构的
GPU
,使用
30
亿个晶体管实现,共计
512
个
CUDA
内核(绿色小块,负责数学运算)。这
512
个
CUDA
内核被组织成
16
个
SM
(流处理器,
Streaming Multiprocessor
),每个
SM
是一个垂直的矩形条带
(
红框
)
,分别位于一个普通的
L2cache
周围,每个
SM
有
32
个
CUDA
内核。
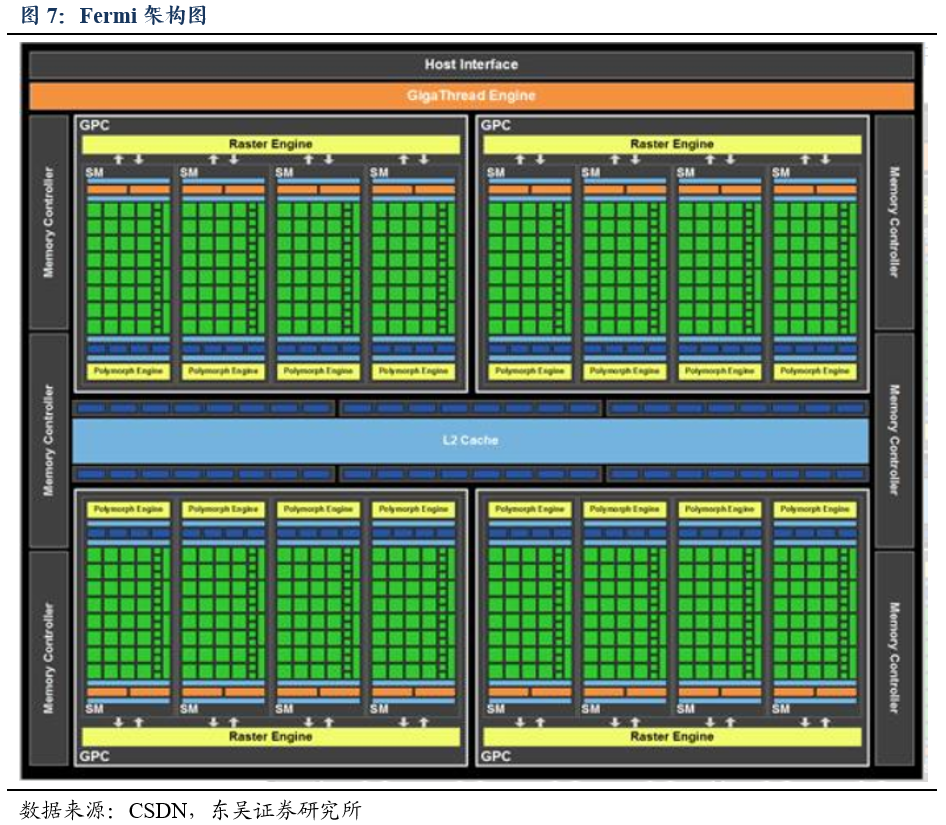
GPU
中包含多个
GPC
。
GPC
可以被认为是一个独立的
GPU
。整个
GPU
有多个
GPC(
图形处理集群
)
,单个
GPC
包含
1
个光栅引擎
(Raster Engine)
,
4
个
SM
(流式多处理器),它们其中有很多连接。所有从
Fermi
开始的
NVIDIA GPU
,都有
GPC
。主机接口
(Host Interface )
通过
PCI-Express
将
GPU
连接到
CPU
。
Giga Thread
全局调度器将线程块分发给
SM
线程调度器。
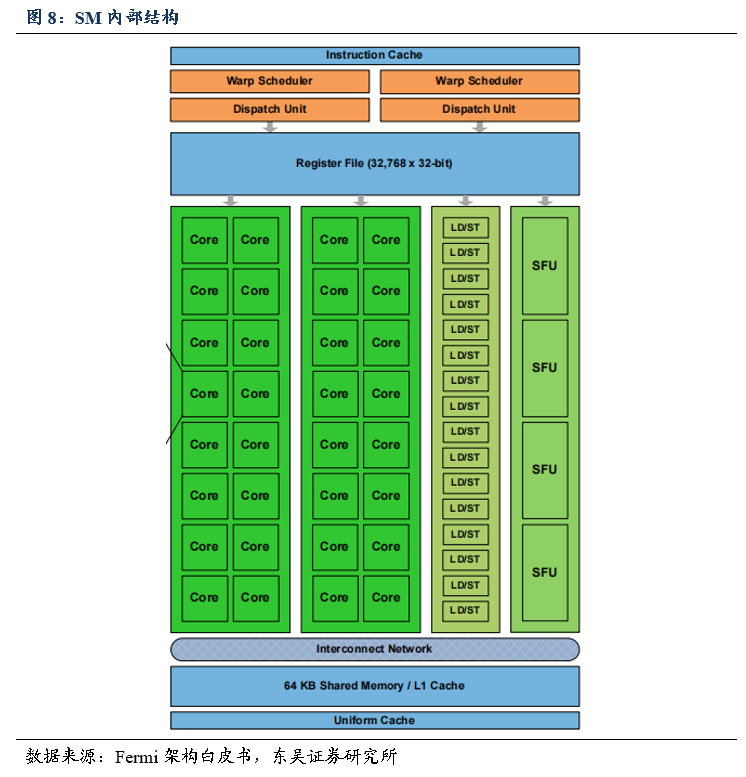
GPC
的主要组成部分
SM
(
Streaming Multiprocessors
)。单个
GPC
包含
1
个光栅引擎
(Raster Engine)
,
4
个
SM
。
GPU
硬件的并行性就是由
SM
决定的。每个
SM
具有
32
个
CUDA
内核(绿色方块),每个
CUDA
内核都有一个完全流水线化的整数算术逻辑单元
(ALU)
和浮点单元
(FPU)
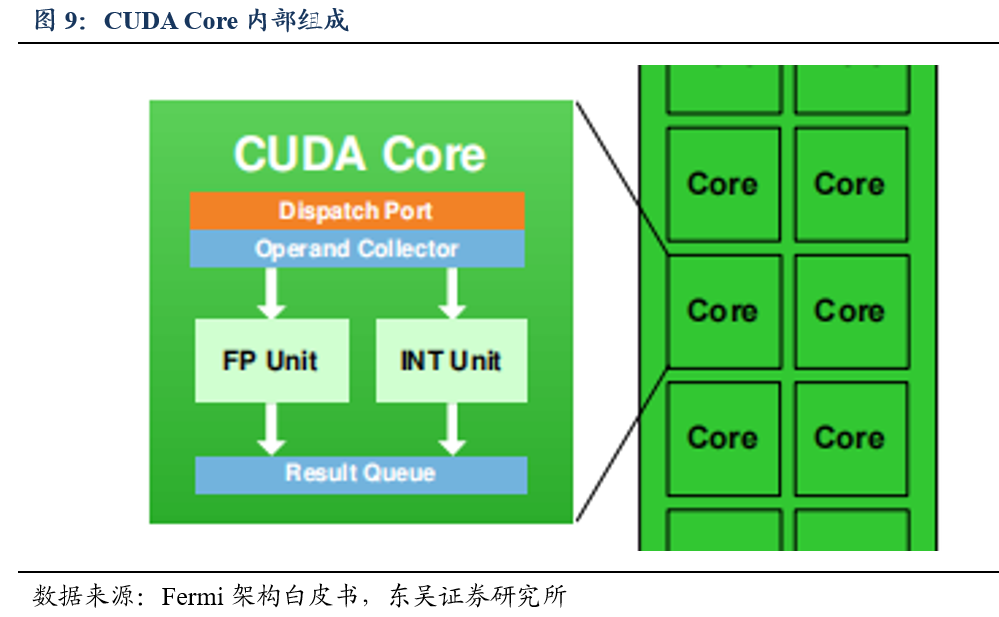
,其负责计算。这些
Core
由
Warp Scheduler
驱动,
Warp Scheduler
管理一组线程束(
Warp
)并将要执行的指令移交给
Dispatch Unites
,
Dispatch Unites
再通过寄存器(
Register File
)将任务分给每个
Core
。
LD/ST
(
Load/Store
)模块来加载和存储数据,
SFU
(
Special Function Units
)执行特殊数学运算(
sin
、
cos
、
log
等)。
5
. GPU
重要参数解释及GPU性能比较
5
.1. GPU
重要参数解释
显存,全称显示内存,暂时储存显示芯片要处理的数据和处理完毕的数据。
图形核心的性能愈强,需要的显存也就越多。显存类型从原来的容量不大的
SDR
,发展到
DDR
、
SDRAM
、
DDR3
、
DDR4
等。从
Pascal
架构开始,
NVIDIA
已经开始提供
HBM2
类型的显存,最新针对专业计算的
Tesla A100
采用
HBM2
,显存容量可达
40GB
,为游戏设计的
RTX 8080 Ti
采用
DDR6
,显存容量也可达
12GB
。显存主要由传统的内存制造商提供,比如三星、现代、
Kingston
等。
显存位宽,指一个时钟周期内能传输数据的位数(
bit
)。
显存位宽位数越大则瞬间所能传输的数据量越大,这是显存的重要参数之一。显存位宽越高,性能越好价格也就越高,因此
512
位宽的显存更多应用于高端显卡。
显存频率指显存在显卡上工作时的频率,以
MHz
(兆赫兹)为单位。
显存频率一定程度上反应着该显存存取的速度。显存频率随着显存的类型、性能的不同而不同,
DDR
、
SDRAM
显存则能提供较高的显存频率,因此是采用最为广泛的显存类型。近年来,
GPU
显存频率已经从百级提升到万级,
GTX 1080 Ti
的显存频率已经高达
10000MHz
。
显存带宽,指显示芯片与显存之间的数据传输速率,单位是字节
/
秒。
显卡的显存是由一块块的显存芯片构成的,显存总位宽同样也是由显存颗粒的位宽组成,显存带宽=显存频率×显存位宽
/8
。显存带宽是决定显卡性能和速度最重要的因素之一。
制作工艺,指的是晶体管与晶体管之间的距离,单位是纳米。
制作工艺越小说明集成度越高,功耗越小,性能越好。目前
NVIDIA
最先进的
Tesla
采用
7nm
制程,
GTX 1080 Ti
采用
16nm
制程。
像素填充速率,指
GPU
一秒钟内能处理多少个像素,单位是
GPixel/S
(每秒十亿像素),或
MPixel/S
(每秒百万像素)。
像素填充速率是较好衡量
GPU
图像显示功能的整体指标,说明了显卡能以多快的速度对图像进行光栅化处理。显卡的硬件指标对其速度具有直接影响。
纹理填充率,指对多边形图像进行纹理贴图、实现
3D
效果的速度,和像素填充率类似,单位是
GTexels/S
或
MTexels/S
。
游戏采用了多纹理贴图的方式,使画面具有更好的光影效果。像素填充率和纹理填充率反映的是
GPU
的性能,而显存带宽则体现了显存的性能。
功率,集显依靠
CPU
的主板连接提供电源,但独显性能较强,需要单独接电源。
如
RTX 3080 Ti
功率为
750w
。
总线接口,显示卡要插在主板上才能与主板互相交换数据,现在主流接口为
PCLe
(
PCI-Express
)。
接口提供数据流量带宽,目前主流采用
PCLe4.0
版本,
16
个通道。
Directx
支持,简称
DX
,是一种应用程序接口(
API
)。
DX
由微软编写,由很多的
API
组成,包括显示、声音、输入和网络。
DirectX 11
还支持高质量实时渲染和预渲染场景,目前
DX
已发展到
Directx 12
版本,提高了多线程效率,可以充分发挥多线程硬件的潜力。
CUDA Core
和
Tensor Core
,为
GPU
提供计算能力的硬件单元。
CUDA core
也叫
Streaming Processor
(
SP
),是单精度,组成
SM
的重要部分。
Tensor Core
已发展到第三代,
Tensor Core
大幅减少了深度学习需要的时间。
Core
的数量越多,并行运算的线程越大,计算的峰值越高。
5
.2. 如何去对比GPU
GPU
性能最直接的体现就是画图的速度,对应的指标就是像素填充率和纹理填充率。其他一些指标,也可以间接的反应
GPU
的性能,如
CUDA Core
、
Tensor Core
的数量、核心频率(显示核心的工作频率)、显存位宽、显存频率等。这些值越大,往往意味着性能更强。
6. GPU投资机会及相关标的
人工智能时代来临,
GPU
应用领域不断扩展,市场需求愈加旺盛。
自统一渲染架构提出以来,
GPU
技术快速发展,新兴应用场景的不断涌现,如车载,摄像头等,有望进一步催生市场需求,打开更广阔的市场空间。在此背景下,我们预计
2027
年中国独立
GPU
市场规模有望超过
346
亿美元,推荐
GPU
相关标的景嘉微,关注中科曙光、航锦科技等。
信创:中国软件、东方通、卫士通、中国长城、太极股份、神州数码、景嘉微;
网安:安恒信息、启明星辰、拓尔思、美亚柏科、绿盟科技、卫士通、格尔软件、中新赛克、奇安信;
风险提示:
1、
信息创新、网络安全进展低于预期:
网安政策进展低于预期,央企安全运营低于预期,智慧城市安全运营推进缓慢,工控、云安全需求低于预期;
2、
行业后周期性:
经济增长不及预期,计算机属于后周期性行业,会导致下游信息化投入放缓;
3、
疫情风险超预期:
疫情导致的风险偏好下降超过市场预期。










