在之前的一篇
缓存穿透、缓存并发、缓存失效之思路变迁
文章中介绍了关于缓存穿透、并发的一些常用思路,但是个人感觉文章中没有明确一些思路的使用场景,本文将继续深化与大家共同探讨,同时也非常感谢这段时间给我提宝贵建议的朋友们(注:本文中提到的缓存可以理解为Redis)。
相信不少朋友之前看过很多类似的文章,但是归根结底就是二个问题:
当并发较高的时候,其实我是不建议使用缓存过期这个策略的,我更希望缓存一直存在,通过后台系统来更新缓存系统中的数据达到数据的一致性目的,有的朋友可能会质疑,如果缓存系统挂了怎么办,这样数据库更新了但是缓存没有更新,没有达到一致性的状态。
解决问题的思路是
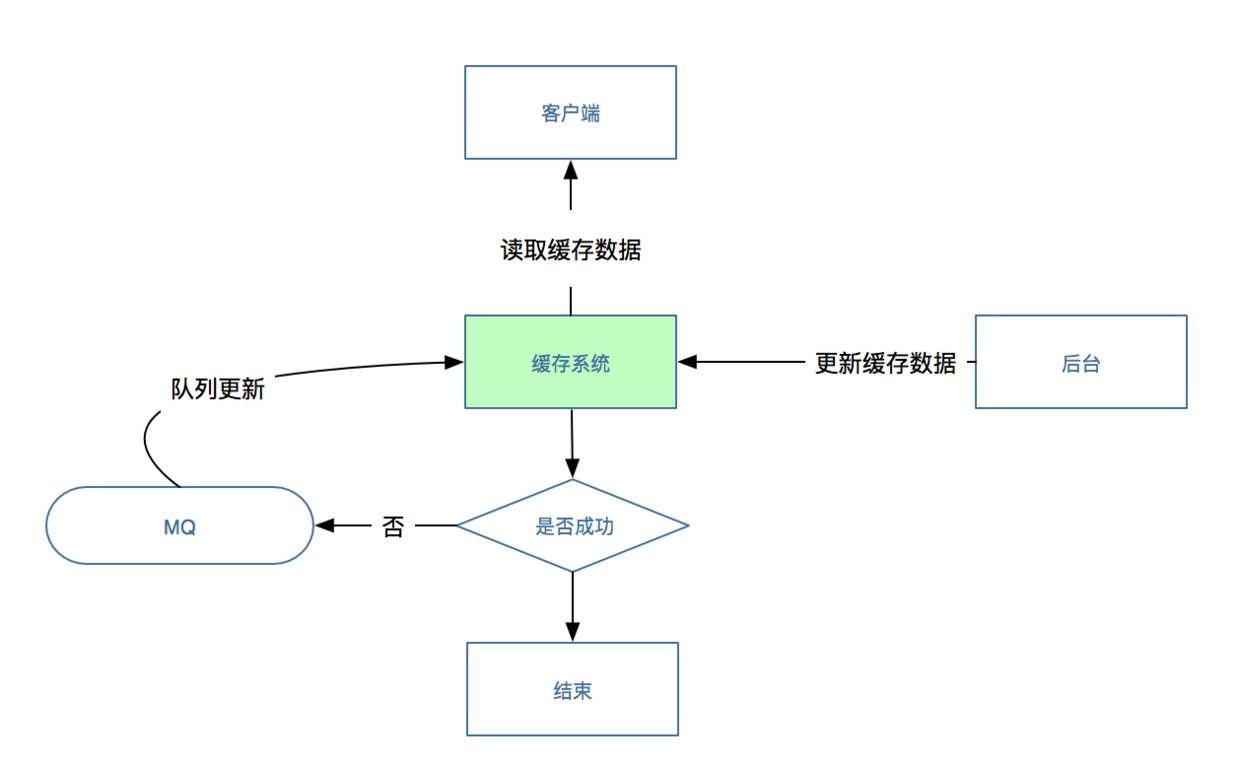
如果缓存是因为网络问题没有更新成功数据,那么建议重试几次,如果依然没有更新成功则认为缓存系统出错不可用,这时候客户端会将数据的KEY插入到消息系统中,消息系统可以过滤相同的KEY,只需保证消息系统不存在相同的KEY,当缓存系统恢复可用的时候,依次从MQ中取出KEY值然后从数据库中读取最新的数据更新缓存。
注意:更新缓存之前,缓存中依然有旧数据,所以不会造成缓存穿透。
下图展示了整个思路的过程:
看完上面的方案以后,又会有不少朋友提出疑问,如果我是第一次使用缓存或者缓存中暂时没有我需要的数据,那又该如何处理呢?
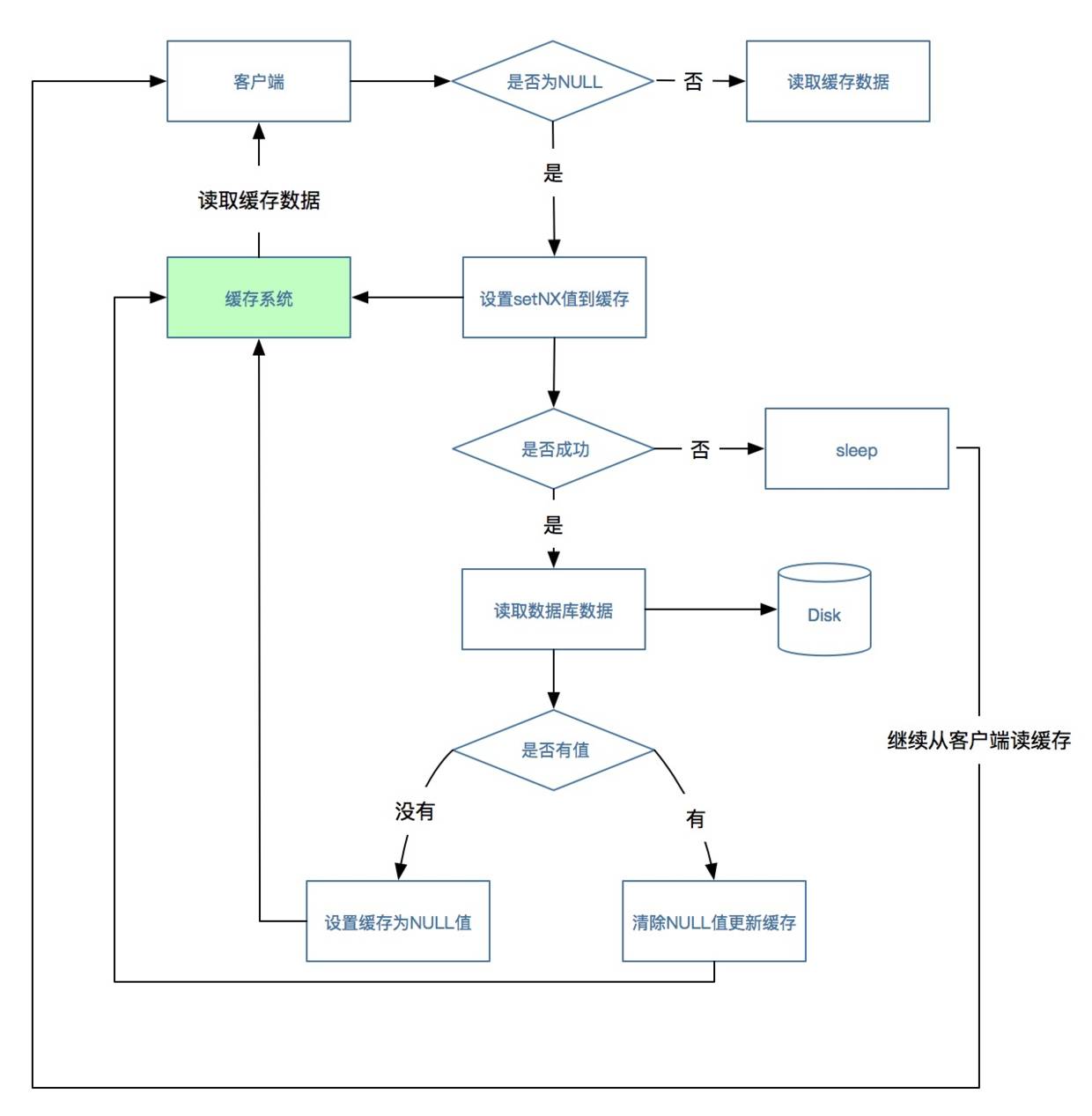
在这种场景下,客户端从缓存中根据KEY读取数据,如果读到了数据则流程结束,如果没有读到数据(可能会有多个并发都没有读到数据),这时候使用缓存系统中的setNX方法设置一个值(这种方法类似加个锁),没有设置成功的请求则sleep一段时间,设置成功的请求读取数据库获取值,如果获取到则更新缓存,流程结束,之前sleep的请求这时候唤醒后直接再从缓存中读取数据,此时流程结束。
在看完这个流程后,我想这里面会有一个漏洞,如果数据库中没有我们需要的数据该怎么处理,如果不处理则请求会造成死循环,不断的在缓存和数据库中查询,这时候我们会沿用我之前文章中的如果没有读到数据则往缓存中插入一个NULL字符串的思路,这样其他请求直接就可以根据“NULL”进行处理,直到后台系统在数据库成功插入数据后同步更新清理NULL数据和更新缓存。
流程图如下所示:
在实际工作中,我们往往将上面二个方案组合使用才能达到最佳效果,虽然第二种方案也会造成请求阻塞,但是只是在第一次使用或者缓存暂时没有数据的情况下才会产生,在生产中经过检验在TPS没有上万的情况下是不会造成问题的。
我们拿用户中心的一个案例来说明。每个用户都会首先获取自己的用户信息,然后再进行其他相关的操作,有可能会有如下一些场景情况:
-
会有大量相同用户重复访问该项目。
-
会有同一用户频繁访问同一模块。
-
因为用户本身是不固定的而且用户数量也有几百万尤其上千万,我们不可能把所有的用户信息全部缓存起来,通过第一个场景情况可以看到一些规律,那就是有大量的相同用户重复访问,但是究竟是哪些用户重复访问我们也并不知道。
-
如果有一个用户频繁刷新读取项目,那么对数据库本身也会造成较大压力,当然我们也会有相关的保护机制来确实恶意攻击,可以从前端控制,也可以有采黑名单等机制,这里不在赘述。如果用缓存的话,我们又该如何控制同一用户繁重读取用户信息呢。
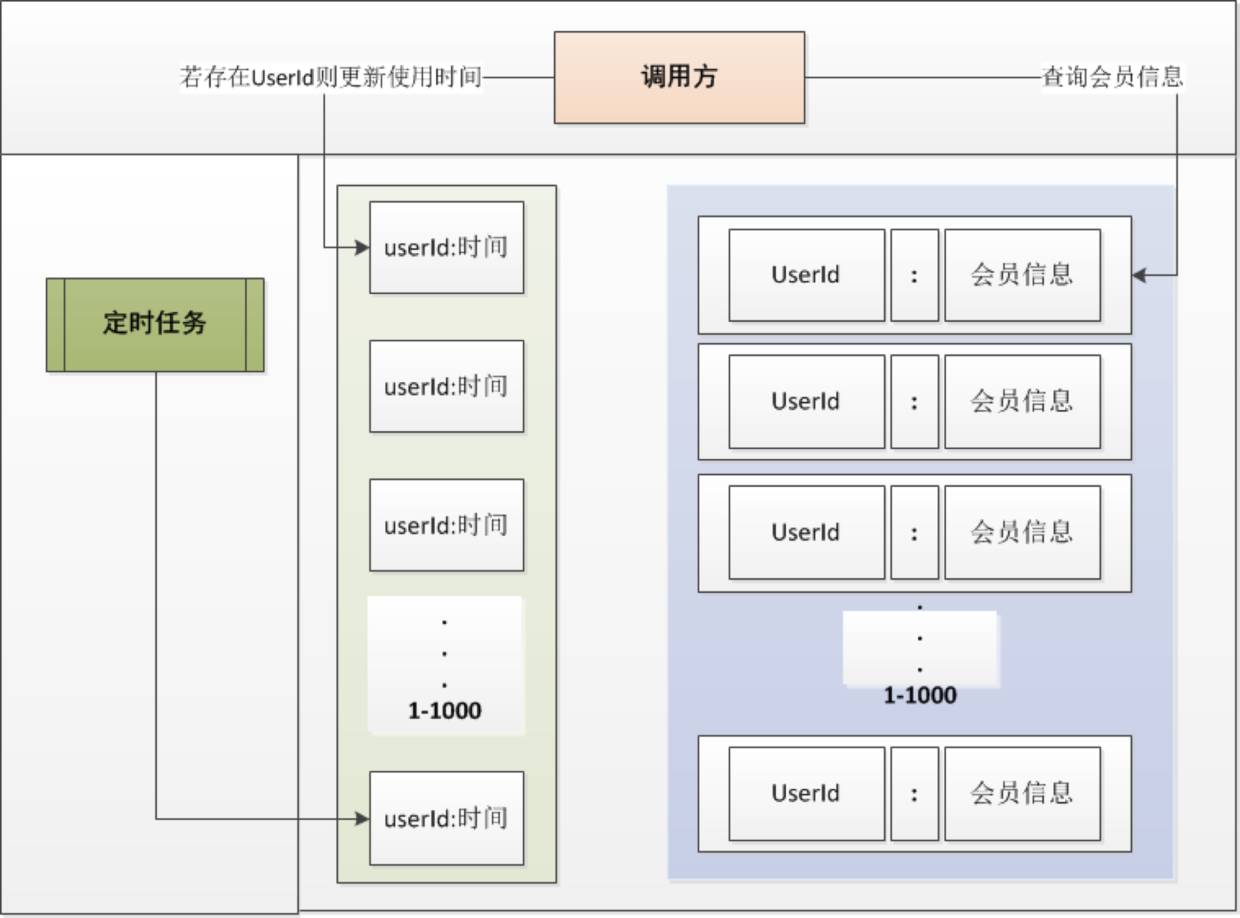
我们会通过缓存系统做一个排序队列,比如1000个用户,系统会根据用户的访问时间更新用户信息的时间,越是最近访问的用户排名越排前,系统会定期过滤掉排名最后的200个用户,然后再从数据库中随机取出200个用户加入队列,这样请求每次到达的时候,会先从队列中获取用户信息,如果命中则根据userId,再从另一个缓存数据结构中读取用户信息,如果没有命中则说明该用户请求频率不高。







