TensorFlow 在 2015 年年底一出现就受到了极大的关注,在一个月内获得了 GitHub上超过一万颗星的关注,目前在所有的机器学习、深度学习项目中排名第一,甚至在所有的 Python 项目中也排名第一。
Google于2017年2月16日(北京时间)凌晨2点在美国加利福尼亚州山景城举办了首届TensorFlow开发者峰会。Google现场宣布全球领先的深度学习开源框架TensorFlow正式对外发布V1.0版本,并保证Google的本次发布版本的API接口满足生产环境稳定性要求。
本文我们将主要介绍TensorFlow的技术相关,同时对比Caffe、Theano 、Torch、Keras、MXNet、CNTK等其他7种深度学习框架。本文节选自《TensorFlow实战》第二章。
深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe8、Keras9、CNTK10、Torch711、MXNet12、Leaf13、Theano14、DeepLearning415、Lasagne16、Neon17,等等。然而TensorFlow却杀出重围,在关注度和用户数上都占据绝对优势,大有一统江湖之势。表2-1所示为各个开源框架在GitHub上的数据统计(数据统计于2017年1月3日),可以看到TensorFlow在star数量、fork数量、contributor数量这三个数据上都完胜其他对手。
究其原因,主要是Google在业界的号召力确实强大,之前也有许多成功的开源项目,以及Google强大的人工智能研发水平,都让大家对Google的深度学习框架充满信心,以至于TensorFlow在2015年11月刚开源的第一个月就积累了10000+的star。其次,TensorFlow确实在很多方面拥有优异的表现,比如设计神经网络结构的代码的简洁度,分布式深度学习算法的执行效率,还有部署的便利性,都是其得以胜出的亮点。
如果一直关注着TensorFlow的开发进度,就会发现基本上每星期TensorFlow都会有1万行以上的代码更新,多则数万行。产品本身优异的质量、快速的迭代更新、活跃的社区和积极的反馈,形成了良性循环,可以想见TensorFlow未来将继续在各种深度学习框架中独占鳌头。
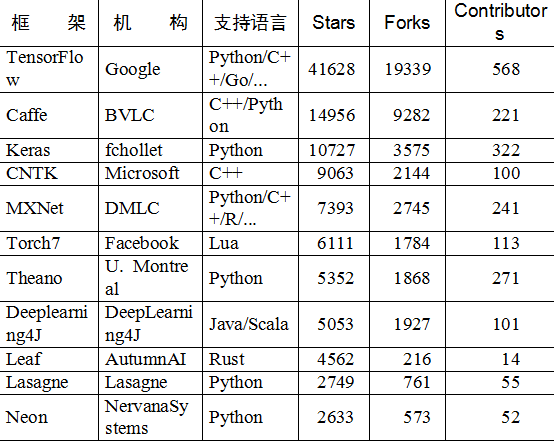
表2-1 各个开源框架在GitHub上的数据统计
观察表2-1还可以发现,Google、Microsoft、Facebook等巨头都参与了这场深度学习框架大战,此外,还有毕业于伯克利大学的贾扬清主导开发的Caffe,蒙特利尔大学Lisa Lab团队开发的Theano,以及其他个人或商业组织贡献的框架。
另外,可以看到各大主流框架基本都支持Python,目前Python在科学计算和数据挖掘领域可以说是独领风骚。虽然有来自R、Julia等语言的竞争压力,但是Python的各种库实在是太完善了,Web开发、数据可视化、数据预处理、数据库连接、爬虫等无所不能,有一个完美的生态环境。仅在数据挖据工具链上,Python就有NumPy、SciPy、Pandas、Scikit-learn、XGBoost等组件,做数据采集和预处理都非常方便,并且之后的模型训练阶段可以和TensorFlow等基于Python的深度学习框架完美衔接。
表2-2和图2-1所示为对主流的深度学习框架TensorFlow、Caffe、CNTK、Theano、Torch在各个维度的评分,本书2.2节会对各个深度学习框架进行比较详细的介绍。
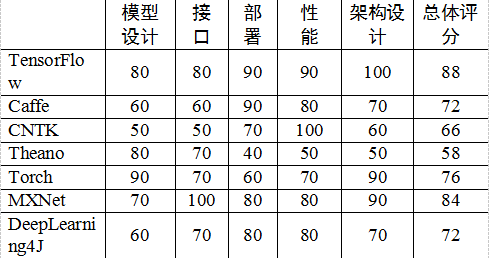
图2-1 主流深度学习框架对比图
TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA18代码。它和Theano一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和Caffe一样是用C++编写的,使用C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python则会比较消耗资源,并且执行效率不高)。
除了核心代码的C++接口,TensorFlow还有官方的Python、Go和Java接口,是通过SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用C++部署模型。SWIG支持给C/C++代码提供各种语言的接口,因此其他脚本语言的接口未来也可以通过SWIG方便地添加。
不过使用Python时有一个影响效率的问题是,每一个mini-batch要从Python中feed到网络中,这个过程在mini-batch的数据量很小或者运算时间很短时,可能会带来影响比较大的延迟。现在TensorFlow还有非官方的Julia、Node.js、R的接口支持,地址如下:
Julia:
github.com/malmaud/TensorFlow.jl
Node.js:
github.com/node-tensorflow/node-tensorflow
R:
github.com/rstudio/tensorflow
TensorFlow也有内置的TF.Learn和TF.Slim等上层组件可以帮助快速地设计新网络,并且兼容Scikit-learn estimator接口,可以方便地实现evaluate、grid search、cross validation等功能。同时TensorFlow不只局限于神经网络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。
事实上,只要可以将计算表示成计算图的形式,就可以使用TensorFlow。用户可以写内层循环代码控制计算图分支的计算,TensorFlow会自动将相关的分支转为子图并执行迭代运算。TensorFlow也可以将计算图中的各个节点分配到不同的设备执行,充分利用硬件资源。定义新的节点只需要写一个Python函数,如果没有对应的底层运算核,那么可能需要写C++或者CUDA代码实现运算操作。
在数据并行模式上,TensorFlow和Parameter Server很像,但TensorFlow有独立的Variable node,不像其他框架有一个全局统一的参数服务器,因此参数同步更自由。TensorFlow和Spark的核心都是一个数据计算的流式图,Spark面向的是大规模的数据,支持SQL等操作,而TensorFlow主要面向内存足以装载模型参数的环境,这样可以最大化计算效率。
TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。相比于Theano,TensorFlow还有一个优势就是它极快的编译速度,在定义新网络结构时,Theano通常需要长时间的编译,因此尝试新模型需要比较大的代价,而TensorFlow完全没有这个问题。
TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时一旦TensorFlow广泛地被工业界使用,将产生良性循环,成为深度学习领域的事实标准。
除了支持常见的网络结构[卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurent Neural Network,RNN)]外,TensorFlow还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。TensorFlow此前不支持symbolic loop,需要使用Python循环而无法进行图编译优化,但最近新加入的XLA已经开始支持JIT和AOT,另外它使用bucketing trick也可以比较高效地实现循环神经网络。TensorFlow的一个薄弱地方可能在于计算图必须构建为静态图,这让很多计算变得难以实现,尤其是序列预测中经常使用的beam search。
TensorFlow的用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU(最近也开始通过OpenCL支持AMD的GPU,但没有CUDA成熟),支持Linux和Mac,最近在0.12版本中也开始尝试支持Windows。在工业生产环境中,硬件设备有些是最新款的,有些是用了几年的老机型,来源可能比较复杂,TensorFlow的异构性让它能够全面地支持各种硬件和操作系统。同时,其在CPU上的矩阵运算库使用了Eigen而不是BLAS库,能够基于ARM架构编译和优化,因此在移动设备(Android和iOS)上表现得很好。
TensorFlow在最开始发布时只支持单机,而且只支持CUDA 6.5和cuDNN v2,并且没有官方和其他深度学习框架的对比结果。在2015年年底,许多其他框架做了各种性能对比评测,每次TensorFlow都会作为较差的对照组出现。那个时期的TensorFlow真的不快,性能上仅和普遍认为很慢的Theano比肩,在各个框架中可以算是垫底。但是凭借Google强大的开发实力,很快支持了新版的cuDNN(目前支持cuDNN v5.1),在单GPU上的性能追上了其他框架。表2-3所示为各个框架在AlexNet上单GPU的性能评测。
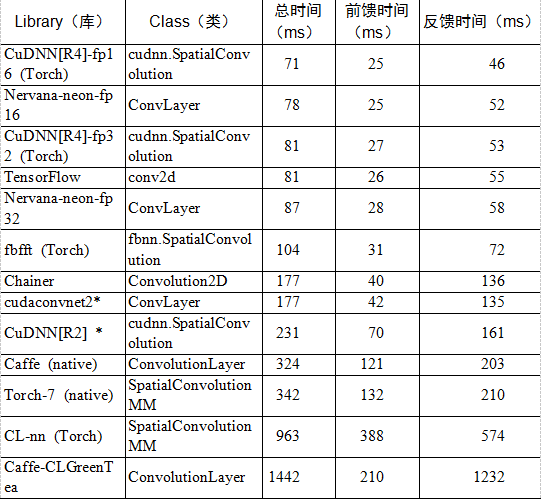
表2-3 各深度学习框架在AlexNet上的性能对比
目前在单GPU的条件下,绝大多数深度学习框架都依赖于cuDNN,因此只要硬件计算能力或者内存分配差异不大,最终训练速度不会相差太大。但是对于大规模深度学习来说,巨大的数据量使得单机很难在有限的时间完成训练。这时需要分布式计算使GPU集群乃至TPU集群并行计算,共同训练出一个模型,所以框架的分布式性能是至关重要的。
TensorFlow在2016年4月开源了分布式版本,使用16块GPU可达单GPU的15倍提速,在50块GPU时可达到40倍提速,分布式的效率很高。目前原生支持的分布式深度学习框架不多,只有TensorFlow、CNTK、DeepLearning4J、MXNet等。不过目前TensorFlow的设计对不同设备间的通信优化得不是很好,其单机的reduction只能用CPU处理,分布式的通信使用基于socket的RPC,而不是速度更快的RDMA,所以其分布式性能可能还没有达到最优。
Google 在2016年2月开源了TensorFlow Serving19,这个组件可以将TensorFlow训练好的模型导出,并部署成可以对外提供预测服务的RESTful接口,如图2-2所示。有了这个组件,TensorFlow就可以实现应用机器学习的全流程:从训练模型、调试参数,到打包模型,最后部署服务,名副其实是一个从研究到生产整条流水线都齐备的框架。
这里引用TensorFlow内部开发人员的描述:“TensorFlow Serving是一个为生产环境而设计的高性能的机器学习服务系统。它可以同时运行多个大规模深度学习模型,支持模型生命周期管理、算法实验,并可以高效地利用GPU资源,让TensorFlow训练好的模型更快捷方便地投入到实际生产环境”。除了TensorFlow以外的其他框架都缺少为生产环境部署的考虑,而Google作为广泛在实际产品中应用深度学习的巨头可能也意识到了这个机会,因此开发了这个部署服务的平台。TensorFlow Serving可以说是一副王牌,将会帮TensorFlow成为行业标准做出巨大贡献。
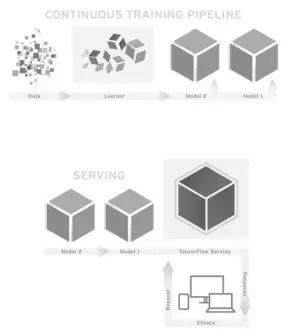
图2-2 TensorFlow Serving架构
TensorBoard是TensorFlow的一组Web应用,用来监控TensorFlow运行过程,或可视化Computation Graph。TensorBoard目前支持5种可视化:标量(scalars)、图片(images)、音频(audio)、直方图(histograms)和计算图(Computation Graph)。TensorBoard的Events Dashboard可以用来持续地监控运行时的关键指标,比如loss、学习速率(learning rate)或是验证集上的准确率(accuracy);Image Dashboard则可以展示训练过程中用户设定保存的图片,比如某个训练中间结果用Matplotlib等绘制(plot)出来的图片;Graph Explorer则可以完全展示一个TensorFlow的计算图,并且支持缩放拖曳和查看节点属性。TensorBoard的可视化效果如图2-3和图2-4所示。
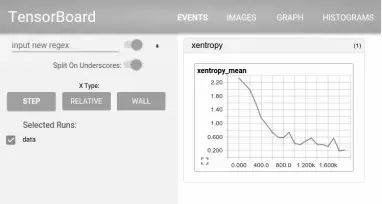
图2-3 TensorBoard的loss标量的可视化
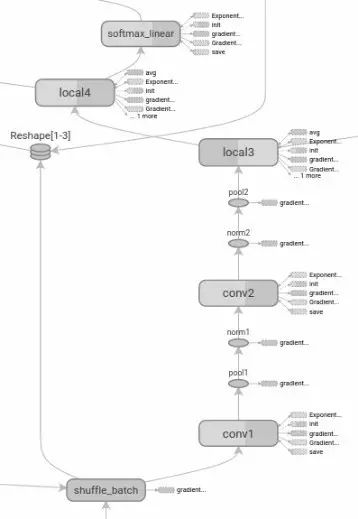
图2-4 TensorBoard的模型结构可视化
TensorFlow拥有产品级的高质量代码,有Google强大的开发、维护能力的加持,整体架构设计也非常优秀。相比于同样基于Python的老牌对手Theano,TensorFlow更成熟、更完善,同时Theano的很多主要开发者都去了Google开发TensorFlow(例如书籍Deep Learning的作者Ian Goodfellow,他后来去了OpenAI)。Google作为巨头公司有比高校或者个人开发者多得多的资源投入到TensorFlow的研发,可以预见,TensorFlow未来的发展将会是飞速的,可能会把大学或者个人维护的深度学习框架远远甩在身后。
官方网址:
caffe.berkeleyvision.org/
GitHub:
github.com/BVLC/caffe
Caffe是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目),目前由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。Caffe的创始人是加州大学伯克利的Ph.D.贾扬清,他同时也是TensorFlow的作者之一,曾工作于MSRA、NEC和Google Brain,目前就职于Facebook FAIR实验室。Caffe的主要优势包括如下几点:
-
容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。
-
训练速度快,能够训练state-of-the-art的模型与大规模的数据。
-
组件模块化,可以方便地拓展到新的模型和学习任务上。
Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络(通过写protobuf配置文件定义)。比如卷积的Layer,它的输入就是图片的全部像素点,内部进行的操作是各种像素值与Layer参数的convolution操作,最后输出的是所有卷积核filter的结果。
每一个Layer需要定义两种运算,一种是正向(forward)的运算,即从输入数据计算输出结果,也就是模型的预测过程;另一种是反向(backward)的运算,从输出端的gradient求解相对于输入的gradient,即反向传播算法,这部分也就是模型的训练过程。实现新Layer时,需要将正向和反向两种计算过程的函数都实现,这部分计算需要用户自己写C++或者CUDA(当需要运行在GPU时)代码,对普通用户来说还是非常难上手的。
正如它的名字Convolutional Architecture for Fast Feature Embedding所描述的,Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但对时间序列RNN、LSTM等支持得不是特别充分。同时,基于Layer的模式也对RNN不是非常友好,定义RNN结构时比较麻烦。在模型结构非常复杂时,可能需要写非常冗长的配置文件才能设计好网络,而且阅读时也比较费力。
Caffe的一大优势是拥有大量的训练好的经典模型(AlexNet、VGG、Inception)乃至其他state-of-the-art(ResNet等)的模型,收藏在它的Model Zoo(github.com/BVLC/ caffe/wiki/Model-Zoo)。因为知名度较高,Caffe被广泛地应用于前沿的工业界和学术界,许多提供源码的深度学习的论文都是使用Caffe来实现其模型的。在计算机视觉领域Caffe应用尤其多,可以用来做人脸识别、图片分类、位置检测、目标追踪等。
虽然Caffe主要是面向学术圈和研究者的,但它的程序运行非常稳定,代码质量比较高,所以也很适合对稳定性要求严格的生产环境,可以算是第一个主流的工业级深度学习框架。因为Caffe的底层是基于C++的,因此可以在各种硬件环境编译并具有良好的移植性,支持Linux、Mac和Windows系统,也可以编译部署到移动设备系统如Android和iOS上。和其他主流深度学习库类似,Caffe也提供了Python语言接口pycaffe,在接触新任务,设计新网络时可以使用其Python接口简化操作。
不过,通常用户还是使用Protobuf配置文件定义神经网络结构,再使用command line进行训练或者预测。Caffe的配置文件是一个JSON类型的.prototxt文件,其中使用许多顺序连接的Layer来描述神经网络结构。Caffe的二进制可执行程序会提取这些.prototxt文件并按其定义来训练神经网络。理论上,Caffe的用户可以完全不写代码,只是定义网络结构就可以完成模型训练了。
Caffe完成训练之后,用户可以把模型文件打包制作成简单易用的接口,比如可以封装成Python或MATLAB的API。不过在.prototxt文件内部设计网络节构可能会比较受限,没有像TensorFlow或者Keras那样在Python中设计网络结构方便、自由。
更重要的是,Caffe的配置文件不能用编程的方式调整超参数,也没有提供像Scikit-learn那样好用的estimator可以方便地进行交叉验证、超参数的Grid Search等操作。Caffe在GPU上训练的性能很好(使用单块GTX 1080训练AlexNet时一天可以训练上百万张图片),但是目前仅支持单机多GPU的训练,没有原生支持分布式的训练。庆幸的是,现在有很多第三方的支持,比如雅虎开源的CaffeOnSpark,可以借助Spark的分布式框架实现Caffe的大规模分布式训练。
官方网址:
http://www.deeplearning.net/software/theano/
GitHub:
github.com/Theano/Theano
Theano诞生于2008年,由蒙特利尔大学Lisa Lab团队开发并维护,是一个高性能的符号计算及深度学习库。因其出现时间早,可以算是这类库的始祖之一,也一度被认为是深度学习研究和应用的重要标准之一。Theano的核心是一个数学表达式的编译器,专门为处理大规模神经网络训练的计算而设计。它可以将用户定义的各种计算编译为高效的底层代码,并链接各种可以加速的库,比如BLAS、CUDA等。Theano允许用户定义、优化和评估包含多维数组的数学表达式,它支持将计算装载到GPU(Theano在GPU上性能不错,但是CPU上较差)。与Scikit-learn一样,Theano也很好地整合了NumPy,对GPU的透明让Theano可以较为方便地进行神经网络设计,而不必直接写CUDA代码。Theano的主要优势如下:
-
集成NumPy,可以直接使用NumPy的ndarray,API接口学习成本低。
-
计算稳定性好,比如可以精准地计算输出值很小的函数(像log(1+x))。



