标题:
NICE-SLAM:
Neural Implicit Scalable Encoding for SLAM
作者:
Zihan Zhu Songyou Peng Viktor Larsson Weiwei Xu Hujun Bao Zhaopeng Cu Martin R. Oswald Marc Pollefeys
来源:CVPR2022
编译:张海晗
审核:zhh
代码:
https://pengsongyou.github.io/nice-slam
.
这是泡泡图灵智库推送的第813
篇文章,欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权
大家好,今天介绍的文章是NICE-SLAM:用于SLAM的神经隐含可扩展编码
摘要
最近,神
经隐
含表征在各个
领
域
显
示出令人鼓舞的
结
果,包括在同步定位和映射(
SLAM
)方面取得的可喜
进
展。然而,
现
有的方法
产
生了
过
度平滑的
场
景重建,并且
难
以
扩
展到大
场
景。
这
些限制主要是由于其
简单
的全
连
接网
络结
构,没有将局部信息
纳
入
观
察范
围
。在本文中,我
们
提出了
NICE-SLAM
,
这
是一个密集的
SLAM
系
统
,通
过
引入分
层
的
场
景表示,
纳
入了多
层
次的本地信息。用
预
先
训练
好的几何先
验
来
优
化
这
个表示,可以在大的室内
场
景中
进
行
详细
的重建。与最近的神
经隐
含
SLAM
系
统
相比,我
们
的方法更具可
扩
展性、效率和
鲁
棒性。在五个具有挑
战
性的数据集上
进
行的
实验
表明,
NICE
-
SLAM
在映射和跟踪
质
量方面都具有
竞
争力。
Project
page: https://pengsongyou.github.io/nice-slam.
主要
贡
献
我
们
提出了
NICE-SLAM
,一个密集的
RGB-D
SLAM
系
统
,它具有
实时
性、可
扩
展性、
预测
性和
对
各种挑
战
性
场
景的
鲁
棒性。
NICE-SLAM
的核心是一个分
层
的、基于网格的神
经隐
式
编码
。与全局神
经场
景
编码
相比,
这
种表示法允
许
局部更新,
这
是大
规
模方法的一个先决条件。
我
们
在各种数据集上
进
行了广泛的
评
估,
证
明了在映射和跟踪方面具有
竞
争力的性能。
主要方法
我
们
的方法将
RGB-D
图
像流作
为输
入,并以分
层
特征网格的形式
输
出
摄
像机的姿
势
和学
习
到的
场
景表示。从右到左,我
们
的管道可以被解
释为
一个生成模型,它根据
给
定的
场
景表示和
摄
像机姿
势
渲染深度和
颜
色
图
像。在
测试时
,我
们
通
过
逆向
传
播
图
像和深度重建
损
失来解决逆向
问题
,并通
过
可区分的渲染器(从左到右)来估
计场
景表
现
和
摄
像机的姿
势
。
这
两个
实
体都是在交替
优
化中估
计
的。映射:逆
传
播只更新
层
次化的
场
景表示。跟踪:逆
传
播只更新
摄
像机的姿
态
。
为
了提高可
读
性,我
们
将用于几何
编码
的
细
尺度网格与同等大小的
颜
色网格
结
合起来,并将它
们显
示
为
具有两个属性(
红
色和橙色)的一个网格。
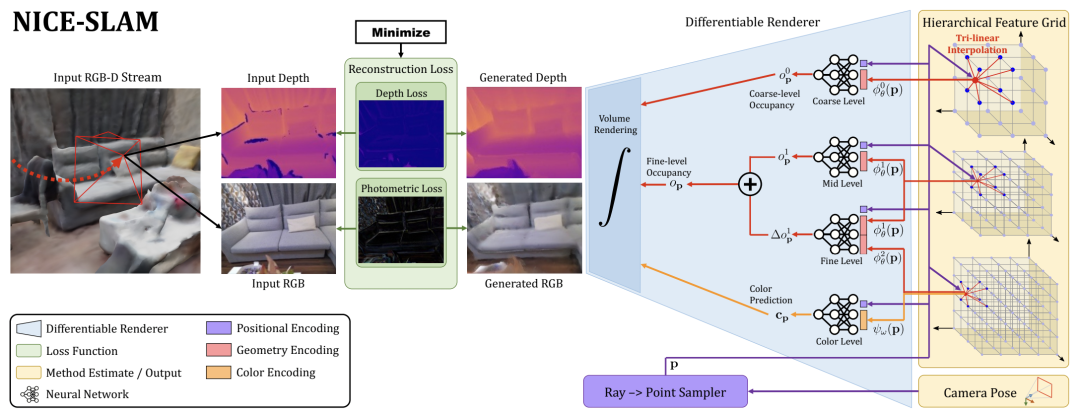
1.
层
次化的
场
景表示
现
在我
们
介
绍
一下我
们
的分
层场
景表示,它
结
合了多
级
网格特征和
预训练
的解
码
器,用于占用率
预测
。几何
图
形被
编码
成三个特征网格
j l θ
和它
们
相
应
的
MLP
解
码
器
f l
,其中
l
∈
{0
,
1
,
2}
是指粗、中、
细
三
级场
景
细节
。此外,我
们还
有一个
单
一的特征网格
ψω
和解
码
器
gω
来模
拟场
景外
观
。
这
里
θ
和
ω
表示几何和
颜
色的可
优
化参数,即网格中的特征和
颜
色解
码
器中的
权
重。
2.
深度和色彩渲染
给
定相机的固有参数和当前相机的姿
势
,我
们
可以
计
算出一个像素坐
标
的
观
察方向
r
。我
们
首先沿着
这
条射
线对
Nstrat
点
进
行分
层
采
样
,同
时对
靠近深度的
Nimp
点
进
行均匀采
样
1
。我
们对
每条射
线总
共取
样
N=Nstrat+Nimp
点。更正式地
说
,
让
pi = o + dir, i
∈
{1, - -, N}
表示
给
定
摄
像机原点
o
的射
线
r
上的采
样
点,
di
对应
于
pi
沿
该
射
线
的深度
值
。
对
于每一个点
pi
,我
们
可以
计
算出它
们
的粗粒度占用概率
o
0 pi
,
细
粒度占用概率
opi
,和
颜
色
值
cpi
。
最后,
对
于每条射
线
,在粗略和精
细层
面的深度,以及
颜
色可以被呈
现为:
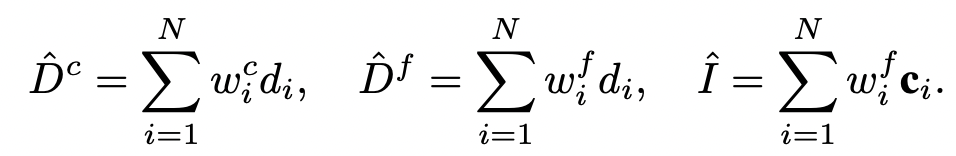
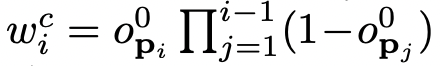
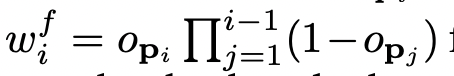
3.
建
图
和跟踪
建
图
。
为
了
优
化上文提到的
场
景表示,我
们
从当前
帧
和
选
定的关
键帧
中均匀地取
样
共
M
个像素。接下来,我
们
以分
阶
段的方式
进
行
优
化,以最小化几何和光度
损
失。
几何
损
失
仅仅
是
观测值
和
预测
深度之
间
的
L1
损
失,在粗略的或精
细
的水平上
为:
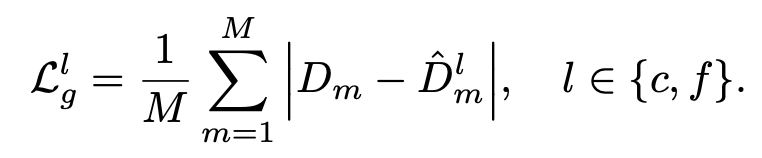
光度损失为:
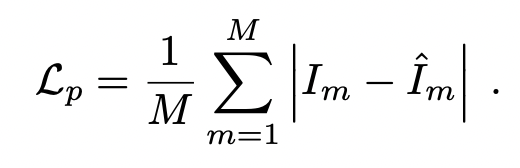
相机跟踪
。除了
优
化
场
景表示外,我
们还
平行运行
摄
像机跟踪,以
优
化当前
帧
的
摄
像机姿
势
,即旋
转
和平移
{R
,
t}
。
为
此,我
们对
当前
帧
中的
Mt
像素
进
行采
样
,并
应
用上面相同的光度
损
失,但使用一个修改
过
的几何
损
失
:
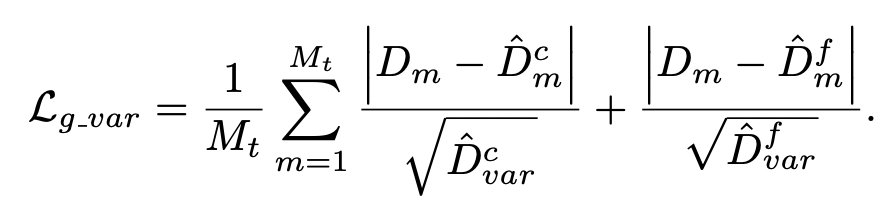
修改后的
损
失在重建的几何形状中减少了某些区域的
权
重,例如物体的
边缘
。
摄
像机跟踪最
终
被表述
为
以下最小化
问题:
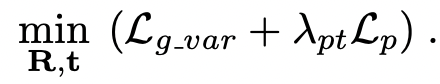
4.
关
键帧
的
选择
与其他
SLAM
系
统
类
似
我
们
用一
组选
定的关
键帧
不断
优
化我
们
的分
层场
景表示。我
们
按照
iMAP
的方法
维护
一个全局关
键帧
列表,我
们
根据信息增益逐步添加新的关
键帧
。然而,与
iMAP
相比,我
们
在
优
化
场
景几何
时
只包括与当前
帧
有
视觉
重叠的关
键帧
。
这
是可能的,因
为
我
们
能
够
对
我
们
的基于网格的表示
进
行局部更新,而且我
们
不会像
iMap
那
样存在关键帧消失的问题
。
这
种关
键帧选择
策略不
仅
确保了当前
视图
之外的几何形状保持静
态
,而且
还导
致了一个非常有效的
优
化
问题
,因
为
我
们
每次只
优
化必要的参数。在
实
践中,我
们
首先随机地
对
像素
进
行采
样
,并使用
优
化后的相机姿
势对
相
应
的深度
进
行反投影。然后,我
们
将点云投影到全局关
键帧
列表中的每个关
键帧
。从
这
些有点投射到的关
键帧
中,我
们
随机
选择
K-2
帧
。此外,我
们还
将最近的关
键帧
和当前的
帧
包括在
场
景表示
优
化中,形成
总
共
K
个活
动帧
。
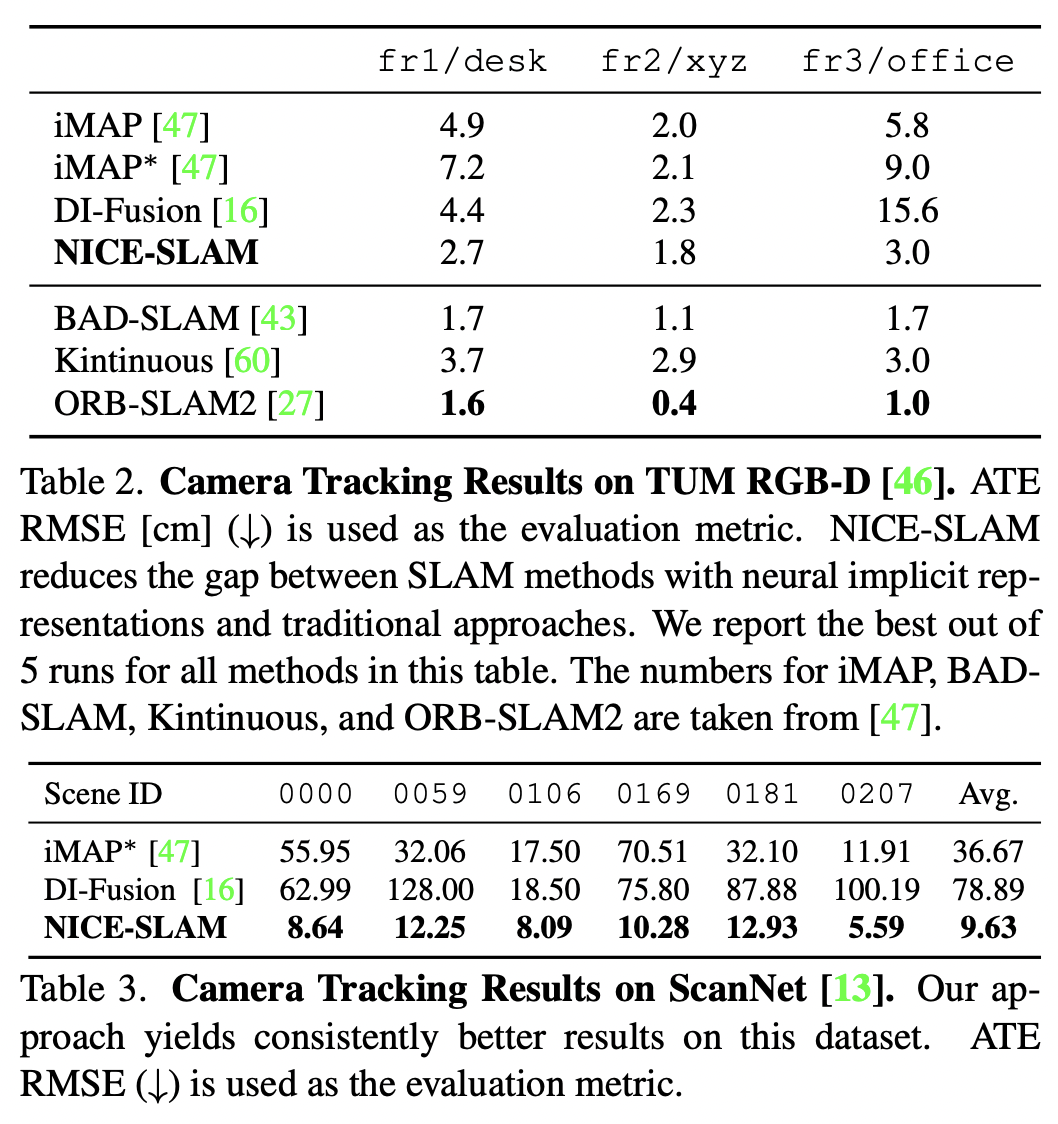
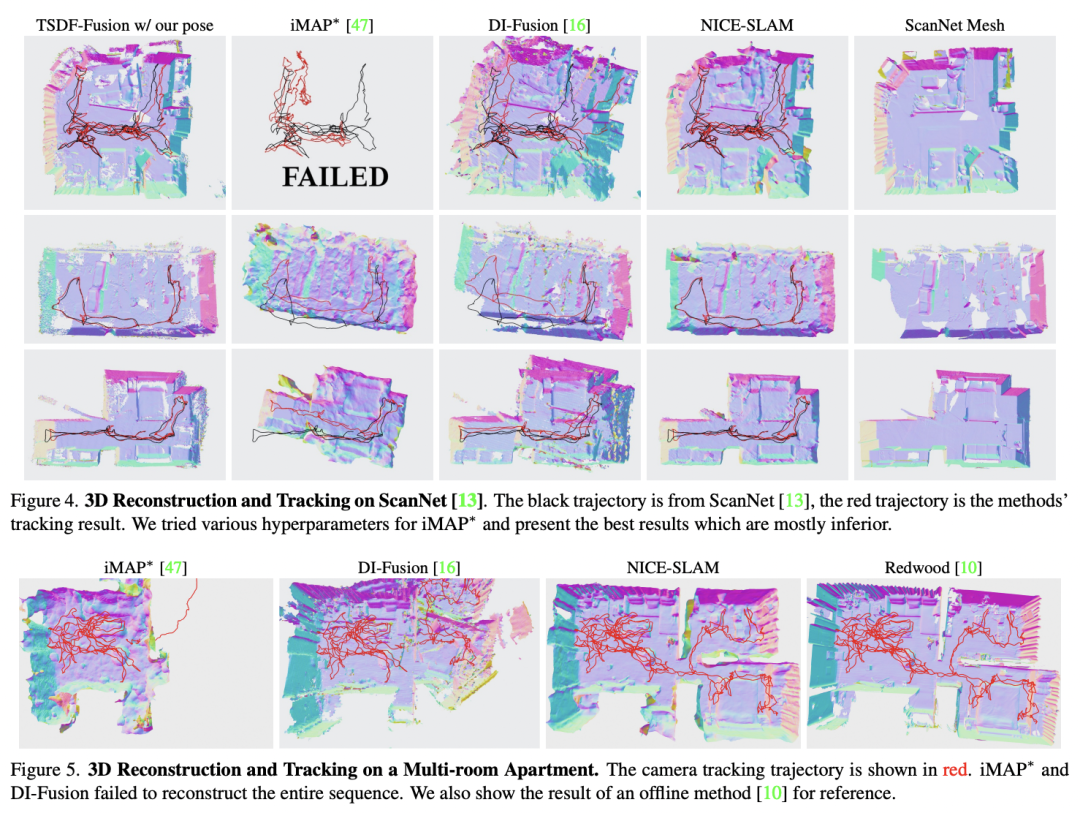
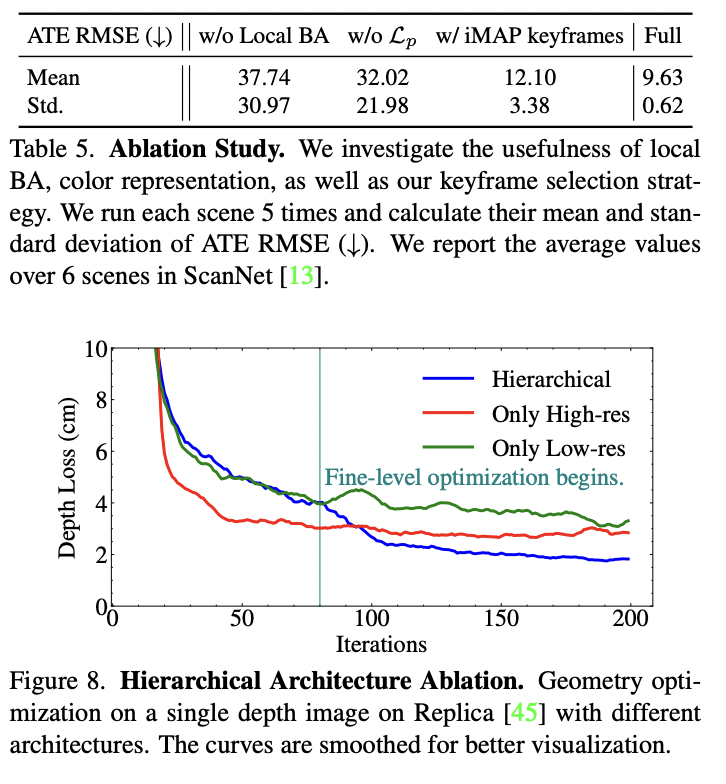
主要
结
果

如果你对本文感兴趣,请点击点击
阅读原文
下载完整文章,如想查看更多文章请关注
【泡泡机器人SLAM】公众号(paopaorobot_slam)
。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/
泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!





