有很多个人工智能(AI)框架供你选择来开发AI算法。同样你也可以选择各种硬件来训练和部署AI模型。框架和硬件的多样性对于保持AI生态系统的健康至关重要。但是,这种多样性也为AI开发人员带来了几个挑战。本文将简要介绍这些挑战,并引入一个编译器解决方案来辅助解决这些问题。
下面,我们首先回顾挑战,介绍华盛顿大学和AWS研究团队,然后介绍编译器的工作原理。
三大挑战
首先,由于前端接口和后端实现之间的差异,从一个AI框架切换到另一个AI框架是很麻烦的。此外,算法开发人员在开发和交付流程中可能会使用多个框架。在AWS,我们有客户希望在MXNet上部署其Caffe模型,从而享受Amazon EC2上的加速性能。根据Joaquin Candela最近的博客,用户可能会使用PyTorch快速开发,然后在Caffe2上部署。但是,我们也听到有人表示在将模型从一个框架转换到另一个框架之后调试结果差异十分困难。
其次,框架开发人员需要维护多个后端,才能确保从智能手机芯片到数据中心GPU的各种硬件的性能。以MXNet为例,MXNet有一个从头构建的便携式C++实现,还附带了专门的后端支持,比如英伟达GPU的CuNNN和英特尔CPU的MKLML。确保这些不同的后端为用户提供一致的数值结果十分具有挑战性。
最后,芯片厂商制造的每款新芯片也需要支持多个AI框架。每个框架中的workload都以独特的方式进行表征和执行,因此即使像卷积一样的运算也可能需要以不同的方式进行定义。因此,在芯片设计和制造方面,支持多个框架也需要大量的工程设计。
华盛顿大学和AWS研究团队
不同的AI框架和硬件为用户带来巨大的收益,但AI开发人员为终端用户提供一致性却是非常具有挑战性的事情。幸运的是,我们并不是第一个面对这种问题的人。计算机科学在不同硬件上运行各种编程语言的历史由来已久。解决这个问题的一个关键技术是编译器。由编译技术驱动,来自华盛顿大学(UW)计算机科学与工程系保罗·艾伦学院的陈天奇,Thierry Moreau,Haichen Shen,Luis Ceze,Carlos Guestrin和Arvind Krishnamurth等一批研究人员,与AWS AI团队的Ziheng Jiang,提出了TVM堆栈来简化这个问题。
今天,AWS很高兴与UW研究团队一起宣布基于TVM堆栈的端到端编译器,它将workload直接从各种深度学习前端编译成优化的机器代码。
架构
下面,我们先来看这个编译器架构。

我们可以注意到,典型的AI框架大致分为三部分:
前端开放一个易于使用的界面给用户;
从前端收到的workload通常被表示为由数据变量(a,b和c)和运算符(*和+)组成的计算图;
从基本的算术运算到神经网络层的运算符都可以针对多个硬件进行实现和优化。
新的编译器,NNVM编译器,基于TVM堆栈中的两个组件:用于计算图的NNVM和用于张量运算符的TVM。
实战真功夫,操盘终极技巧 —abc三浪法实战视频直播课程
该赚的赚到,该亏的亏掉,该扛的扛住。
交易,学到这里就够了。
实战真功夫,操盘终极技巧
—abc三浪法实战视频直播课程
2017
年10月30日-11月10日 网络直播课程
报名电话/微信:18516600808

NNVM - 计算图中间表示(IR)堆栈
NNVM的目标是将不同框架的workload表示为标准计算图,然后将这些高级图转换为执行图。这种计算图的灵感来自Keras中的层定义和numpy的张量运算符。
NNVM还随附例程,名叫Pass,遵循LLVM约定。这些例程可以向图中添加新属性来执行它们或修改图以提高效率。
TVM - 张量IR堆叠
源自Halide的TVM实现了计算图中使用的运算符,并针对目标后端硬件进行了优化。与NNVM不同,TVM提供了一种独立于硬件的域特定语言,简化张量索引级别中的操作符实现。TVM还提供调度原语(如多线程,平铺和高速缓存)来优化计算以充分利用硬件资源。这些计划与硬件有关,可以手动编码,也可以自动搜索优化的模式。
支持的前端框架和后端硬件
支持的前端和后端如下图所示。

MXNet直接将其计算图转换为NNVM图得到支持,Keras也以类似的方式得到支持,不过正在开发中。NNVM编译器也可以采用模型格式,如CoreML。因此,凡是能够使用这些格式框架都可以使用此编译堆栈。
TVM目前随附多个代码生成器,支持各种后端硬件。例如,TVM为CPU(如X86和ARM)生成LLVM IR,也可以为各种GPU输出CUDA,OpenCL和Metal内核。
添加新的支持的操作也很简单。对于新的前端,我们只需要将其workload转换为定义计算图和运算符规范的NNVM即可。要添加新的硬件,我们可以重复使用TVM的运算符实现,只需要指定有效schedule即可。
性能结果
我们使用MXNet展示NNVM编译器性能,前端硬件配置是:ARM上的Raspberry PI和AWS上的英伟达GPU。虽然这两种芯片间的架构差异巨大,但代码上的唯一差异在于调度部分。
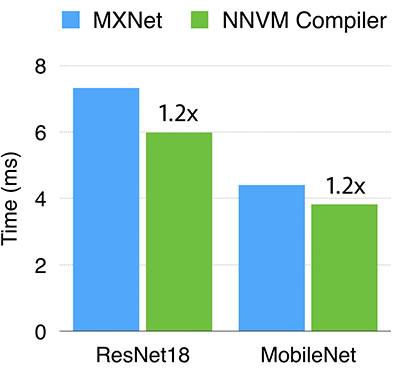
GPU的schedule主要由Leyuan Wang(AWS)和Yuwei Hu(TuSimple)在实习期间编写。比较NNVM编译器与MXNet,英伟达K80的cuDNN后端。像深度卷积的运算符这样在cuDNN中没有有效支持的,通过手动优化的CUDA内核来实现。可以看出,NNVM编译器运行ResNet18和MobileNet比cuDNN后端略好(1.2倍快)。
在Raspberry PI的情况下,我们通过自动调谐器选择最佳schedule。我们通过在Raspberry Pi上对运算符性能进行基准测试,给出了每个运算符在给定形状的最佳schedule。
还是比较NNVM编译器与MXNet。MXNet默认启用OpenBLAS和NNPACK,我们还手动打开了NNPACK中的winograd卷积以获得最佳性能。
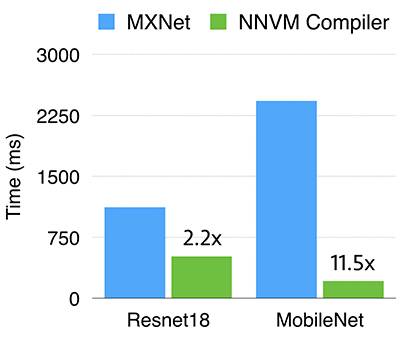
可以看出,NNVM编译器在Resnet18上快了2.2倍。而MobileNet上更有11.5倍的差异。这主要是由于在MXNet中没有优化深度卷积(因为dnn库中缺少这样的运算符),而NNVM编译器则受益于直接生成高效的代码。
结论
我们介绍了NNVM编译器,它将高级计算图编译成优化的机器代码。NNVM编译器基于TVM堆栈中的两个组件:NNVM使用图优化例程提供计算图和运算符的specification,运算符通过使用TVM针对目标硬件实现和优化。我们证明,只需花费很少的精力,这种编译器可以匹配甚至超过两个完全不同的硬件(ARM CPU和Nvidia GPU)上的state-of-the-art性能。
我们希望NNVM编译器可以大大简化新的AI前端框架和后端硬件的设计,并帮助在各种前端和后端为用户提供一致的结果。
来源:AWS AI Blog
作者:李沐



