编者按:人们每天都在面临取舍,如何能够做出机会成本最低且收益最为理想的选择,这让很多选择恐惧症们陷入无限纠结的境地。
看似无比困难的权衡问题,如今组合在线学习就能帮你“算出”最优解,轻松破解传统组合优化问题。本文中,我们邀请到微软亚洲研究院资深研究员陈卫为大家多面解读组合在线学习的奥妙之处。
什么是组合在线学习?大家都曾有过这样的经历,在我们刷微博或是阅读新闻的时候,经常会看到一些自动推荐的内容,这些信息可以根据你对推送的点击情况以及阅读时间等来调整以后的推送选择。再比如,手机导航往往会在你输入地点时推荐一条最合适的路线,当你按照推荐走的时候,手机导航也会收集这次行程的信息,哪里比较堵,哪里很顺畅,从而可以调整系统今后的推荐。
有人会提出质疑:这不就是推荐系统吗?是的,但是传统的推荐系统只能离线学习用户和对象的各种特征,作出尽量合适的推荐,是一个相对静态的系统。而我们这里强调的是在线学习(online learning),即迅速利用在线反馈,不断迭代调整推荐策略,从而尽快提高学习效果和整体收益。而组合在线学习(combinatorial online learning)的组合性则体现在学习的输出上,它不是一个简单结果,而是一个组合对象。比如上述情形中,手机导航输出的路线其实是若干路段的组合或者包括不同交通工具换乘的组合,而手机助手的推荐也是不同消息渠道的组合。
传统的推荐系统通过与组合在线学习相结合,就可以通过即时反馈调整策略达到更好的推荐效果。而组合在线学习应用范围远不止推荐系统,任何传统的组合优化问题,只要问题的输入有不确定性,需要通过在线反馈逐步学习的,都可以应用组合在线学习方法。组合在线学习也是当前大热的强化学习(reinforcement learning)的一个组成部分,而组合在线学习的强大理论支持也会给强化学习提供很好的理论指导。所以组合在线学习就是下面图示所表达的组合优化和在线学习不断交互迭代更新的反馈环路。
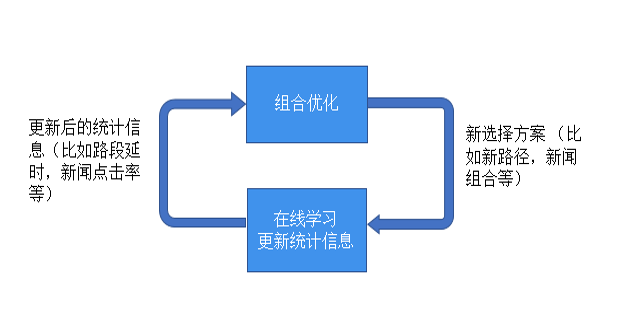

在线学习的核心:权衡探索和守成
要介绍组合在线学习,我们先要介绍一类更简单也更经典的问题,叫做多臂老虎机(multi-armed bandit或MAB)问题。赌场的老虎机有一个绰号叫单臂强盗(single-armed bandit),因为它即使只有一只胳膊,也会把你的钱拿走。而多臂老虎机(或多臂强盗)就从这个绰号引申而来。假设你进入一个赌场,面对一排老虎机(所以有多个臂),由于不同老虎机的期望收益和期望损失不同,你采取什么老虎机选择策略来保证你的总收益最高呢?这就是经典的多臂老虎机问题。
这个经典问题集中体现了在线学习及更宽泛的强化学习中一个核心的权衡问题:我们是应该探索(exploration)去尝试新的可能性,还是应该守成(exploitation),坚持目前已知的最好选择?在多臂老虎机问题中,探索意味着去玩还没玩过的老虎机,但这有可能使你花太多时间和金钱在收益不好的机器上;而守成意味着只玩目前为止给你收益最好的机器,但这又可能使你失去找到更好机器的机会。而类似抉择在日常生活中随处可见:去一个餐厅,你是不是也纠结于是点熟悉的菜品,还是点个新菜?去一个地方,是走熟知的老路还是选一条新路?而探索和守成的权衡就是在线学习的核心。
多臂老虎机的提出和研究最早可以追述到上世纪三十年代,其研究模型和方法已有很多。想进一步了解其技术细节的读者可参考综述[1]。其中一类重要的模型是随机多臂老虎机,即环境给予的反馈遵从某种随机但未知的分布,在线学习的过程就是要学出这个未知分布中的某些参数,而且要保证整个学习过程的整体收益尽量高。这其中最有名的一个方法是UCB(Upper Confidence Bound)方法,能够通过严格的理论论证说明UCB可达到接近理论最优的整体收益。
组合在线学习:组合优化和在线学习的无缝对接









