近日,人工智能初创公司 Vicarious 在官网了发表了一篇名为《General Game Playing with Schema Networks》的文章,提出了一种可以进行游戏泛化的新型网络:图式网络。该网络可通过训练学习环境动态,进而泛化到多种游戏环境之中;同时它还具有概念学习和推理能力,这就克服了深度强化学习的弊端,从而做到像人类一样重复使用概念。机器之心对该文进行了编译,原文链接请见文末。
深度强化学习(deep reinforcement learning)在游戏界的成功已经在 AI 界产生了轰动 (Mnih et al., 2015; Mnih et al., 2016; Silver et al., 2016; Van Hasselt et al., 2016)。人工智能在很多不同的游戏中的最新得分现在已经超越了人类的水平。但是这些成果又能在多大程度上说明人工智能已经可以像人类一样去思考游戏中的事物呢?
当人类接触一个新的游戏时,他们首先要对游戏进行概念性的理解。假设你第一次接触一个类似于打砖块(Breakout)的游戏(见下文)。
通过几秒或几十秒的观察,你已经开始对游戏有了一定的理解,这是因为你对这个世界有着先验的认知(prior experience)。你可能会把移动的红色像素理解为在「墙」上进行「弹跳」的「球」,并且可以识别一个「拍子」来对球进行击打。你明白拍子是可以用来击球的。你会观察到当球碰击到顶部的「砖」时,那些「砖」就会消失。你开始的时候甚至都没有去关注得分的情况,但是后来你开始注意到打碎一个「砖」你就可以得到一定的分数,而且如果你让「球」出现在「拍子」的下方,你就会丢掉一定分数;你已经发现了这个游戏的目的。仅仅通过对游戏进行短时间的简单观察,你就很有可能会理解游戏的相关概念。
从因果(cause and effect)的角度来理解这个世界是人类智力的重要标志之一。这种能力可以让我们通过对我们已有的知识信息进行「迁移」(transferring),从而快速地理解新的情境,比如一个新的电子游戏。
那么随之而来的问题就是:深度强化学习智能体(deep reinforcement learning agents)会对概念和因果进行理解吗?
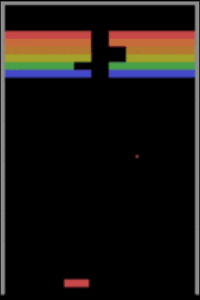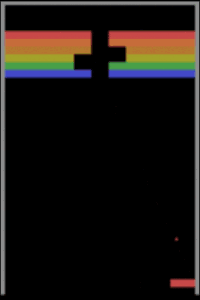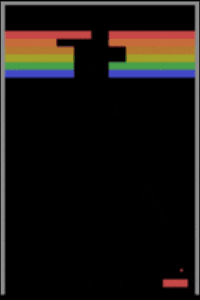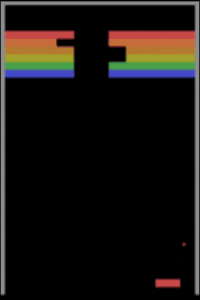
一个在打砖块的 Vicarious 标准版本上用先进的 Asynchronous Advantage Actor-Critic(A3C)方法来训练的深度强化学习智能体
深度强化学习赢了游戏却错失了要点
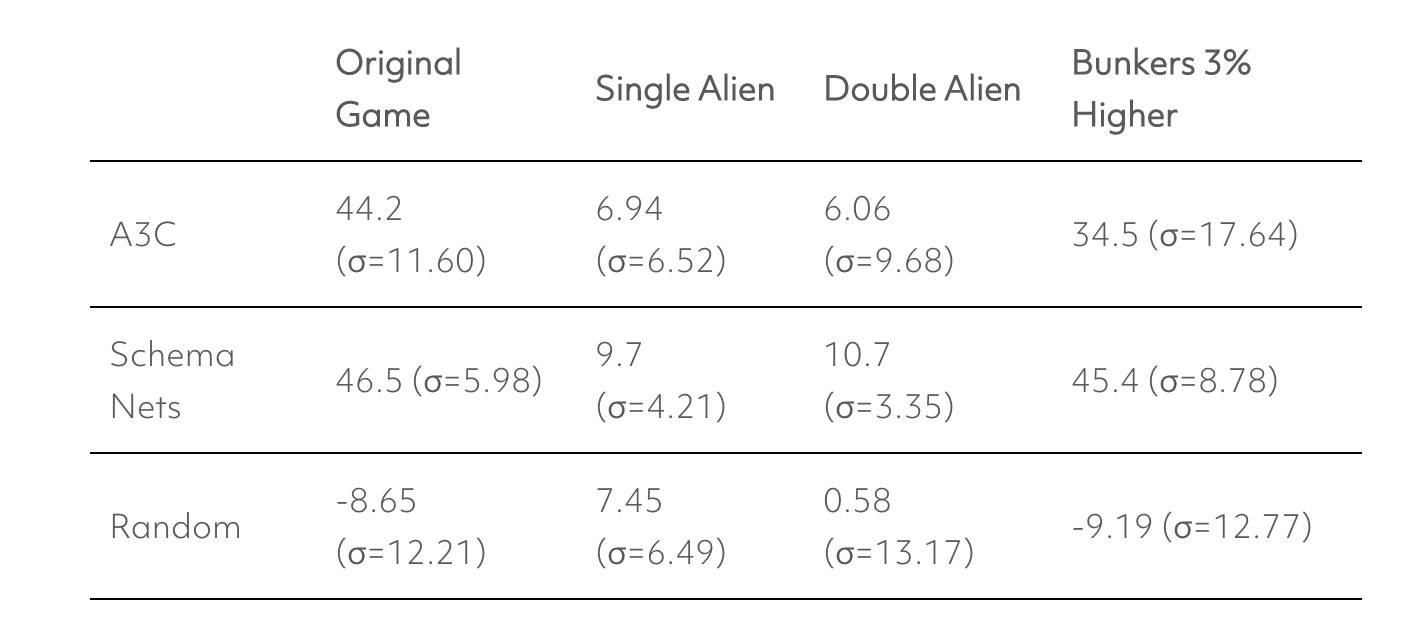
我们用先进的 Asynchronous Advantage Actor-Critic (A3C) (Mnih et al., 2016) 方法去训练一个深度强化学习智能体(deep RL agent),让它去玩一个典型的打砖块游戏,它可以玩的非常好。一个能够玩打砖块标准游戏的智能体应该可以轻易地根据游戏中的小变动进行调整,这些变动包括更高的拍子(paddle)或一堵额外的墙 (Rusu et al., 2016)。
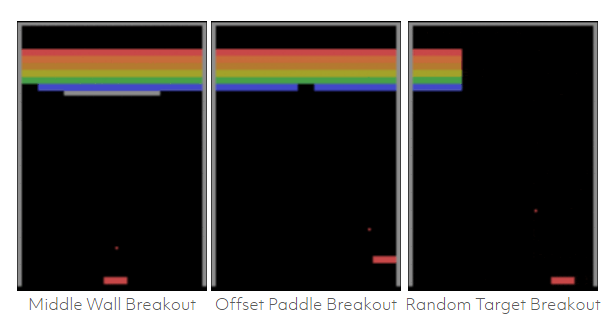
上图图展示了相同的 A3C 智能体可以在玩过一些简单的变体游戏之后,在原始游戏中也拿到专家级的分数。如果 A3C 智能体已经学会了对因果进行概念性的理解,那么根据游戏中的新局势进行调整对智能体来说应该不是问题。
很明显深度学习智能体无法去应对这些小的变化,因为 A3C 和其它的深度学习智能体是通过输入像素到动作(the input pixels to an action)的映射模式来运行的,比如向左或向右移动。智能体从一系列输入像素回归到特定动作,从大量的试验和误差中进行学习。A3C 智能体会对一个特定策略进行「过拟合」(overfit),去开发训练过的游戏版本中的特定数据。但是它没有对游戏的动态变化和规则进行概念性的理解。经常被理解为「智能」的「深度强化学习表现形式」,其实就是简单的基于弱提示的「刺激与反应」(stimulus-response)间的映射关系。
图式网络
在即将到来的 2017 机器学习国际会议(ICML)中,我们将会介绍一种图式网络(Schema Network),这是一种基于模型的强化学习方法,它展现出了一些强大的泛化能力,我们相信这是真正和人类相类似的通用智能的关键所在。图式网络是一种生成图模型,它可以对未来和因果缘由(reason about cause and effect)进行模拟仿真,并且对如何能得到长远的奖励(distant rewards)进行规划。在这篇 ICML 论文中,我们描述了图式网络怎样直接从数据中进行学习,并且展示了 zero-shot 泛化能力——例如,仅在基本游戏类型中进行训练后就可以在上述打砖块游戏的不同变体中获得高分——在传统深度强化学习失效的地方进行精确地设置。
我们使用了一个类似于打砖块的游戏来展示图式网络学习概念(concept)的能力,即从一种变体迁移到下一种变体。
图式网络在其它游戏中也同样展现出了可观的结果。
我们还重点强调了我们测试过的另外两种游戏类型:太空侵略者(Space Invaders)和推箱子(Sokoban)。类似于太空侵略者的游戏包括了很多不同的来源于打砖块的机制,包括常见的物体创造(bullets)和敌军行动的固有随机性。
推箱子与打砖块和太空侵略者有很大的不同,因为这个游戏中的可获得的奖励非常少,要想得分,需要对对象交互进行更长时间范围的推理。
图式网络(Schema Networks)依赖于全部状态中的输入,而非原生图像。本质上,任何可追踪的图像特征可以是一个实体,大多数情况下通常包括物体本身, 它们的边界和它们的表面。实际上,我们假设视觉系统是一个从图像中对实体进行检测和追踪的系统。从 Atari 电子游戏中提取实体并不是一个困难的机器视觉问题,而且最近的新成果 (Garnelo et al., 2016) 已经提出了一种使用自编码器(auto encoder)进行无监督实体构造(unsupervised entity construction)的方法。
通过图式网络学习可重复使用的概念
在图式网络中,对世界上的知识信息的学习是通过小图模型片段 (small graphical model fragments) 进行的,这些片段被称作图式(schemas)。这些图式代表其在实体(名词)、属性(形容词)、实体的交互(动词)等方面的所学内容 (c.f., Diuk et al., 2008)。在新情景下,适当的知识片段被自动实例化,从而来理解情景并引导智能体取得成功。由于实例化模型可表征为概率图模型(PGM/probabilistic graphical model),表征可以自动处理不确定的证据,并解释多种原因。而且,规划问题可被看作成一个推理问题,并通过有效的 PGM 推理算法解决 (Attias, 2003)。
图式网络的核心基底是「图式」。图式描述了一个实体属性的未来值是如何依赖于其属性以及其他可能的邻近实体的当前值的。每一个图式可被看作一个预测变量(predictor),这些预测因子自动从数据中学习。例如,基于当前速率以及砖块(brick)的相对位置,一个图式可能会判定打砖块游戏中球的速率会在下一帧发生改变。另一个图式也许会预测当人类玩家「左」进行移动且左方有空间时,拍子(paddle)也会随之左移。图式还可以预测奖励、实体创建和删除。图式表征允许进行自动的前向与后向因果推理。
图式网络完全由一组图式表征。结果,模型具备高度的可阐释性。检查每一个图式并立即理解其含义是可能的。由于图式网络是一个因子图,可基于当前状态使用不同的概率推断算法预测未来状态和奖励。由于模型是生成性的,相同的算法可用于从目标状态进行后向推理。我们在 ICML 论文中展示了如何使用 MPBP(Max-Product Belief Propagation)高效地寻找打砖块游戏中的可达成奖励。相同的 MPBP 计划机制可用于下文所述的推箱子游戏。前向网络足以应对太空入侵者,我们使用蒙特卡罗树搜索对它做了展示。
图式网络中的学习是图模型中结构学习的一个实例,我们使用了一个基于线性和二进制编程的贪婪算法(详见 ICML 论文)。
突破性结果
我们在 ICML 论文中报道称图式网络能够学习打砖块游戏的标准版本并很好地泛化到上述的其他游戏变体中。它们在变体游戏上的表现如下图所示:
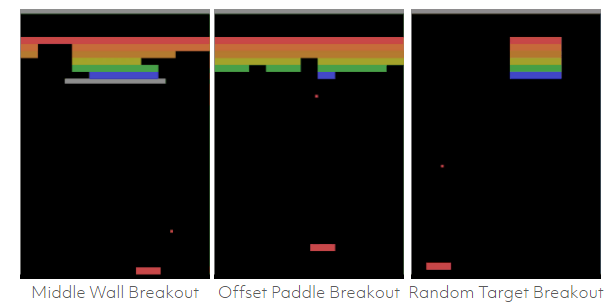
通过学习游戏的概念性表征,图式网络可以推理奖励机制。在下面这张动图中,图式网络通过使用其关于世界的因果模型,演示了如何对很多潜在的未来进行推理:


太空入侵者
打砖块与太空入侵者有一些共同的动力学特点,比如玩家的移动和其他游戏对象相对持续的动量。然而,太空入侵者与打砖块在很多方面又有着有趣的不同,比如,一个新的「射击」动作引起了一个只能被玩家创建的子弹实体。游戏之间的不同并没有为图示网络造成理论障碍,但是带来了相对较小的不多的工程学挑战:我们已经在学习管道中引入了实体「创建」与「删除」图示。此外,我们通过保证可靠地过滤掉噪杂和不可预测的现象而优化了学习。
我们也注意到,在随机动作很快会得到积极与消极奖励的意义上,太空入侵者比打砖块更容易获得奖励。我们把这看作一次使用更简单更快速计划方法——蒙特卡罗树搜索(MCTS,其只需要前向推理)——进行实验的机会。
正如在打砖块中所做的那样,我们使用了自己的太空入侵者版本,以允许我们便捷地对游戏动力学做出小的修缮,比如出于测试 zero-shot 迁移的目的而调整子弹速度,或改变掩体高度。下面是太空入侵者的再实现,它带有一个通过 MCTS 控制玩家的已训练的图式网络。

一个在太空入侵者上训练的图式网络,玩着相同的游戏。
超过 30 次尝试之后,图示网络在太空入侵者上的得分为 46.5 (σ=6.0),而游戏的满分为 50。大致来讲,46.5 的得分意味着在超过一半的时间里算法的表现堪称完美。作为参考,随机策略的得分为 -9.8 (σ=11.6)。
图式网络真的可以瞄准、射击外星人并躲过他们的子弹吗?还是仅仅由于运气?下面是环境的两个较小变体,较好地阐明了智能体的「意图性」。比如,观察右方的玩家如何避开子弹的火力,寻求掩体的遮护,并适时抓住机会回击外星人。它的世界模型并不完美——不是所有的子弹都射向外星人——但是对于玩好太空入侵者的变体游戏,它的预测已经超过需求。

一个在太空入侵者上训练的图式网络,玩着相同的游戏。

相同的图式网络玩着一个「双外星人」变体游戏。
我们也可以可视化计划过程以看到智能体在每一个行动之间「思考」了什么。由于我们使用了 MCTS 而不是基于 MPBP 的计划算法,探索模型和可视化下面的计划看起来并不相同。MPBP 算法首先找到了可达成的奖励,接着通过具体目标展开后向推理。相反,MCTS 则是通过明断地选择假设性动作和累加已发现的奖励探索了可能的未来状态。由于 MCTS 探索了多个可能的未来,我们根据它们的可视化位置的概率来遮蔽目标。

玩太空入侵者的图式网络(彩色)与该游戏的模拟(白色)相互交替。
从打砖块到太空入侵者,我们付出了较小的工程学努力就做到了,我们很受鼓舞,相信图式网络也可以泛化到其他领域内类似于 Atari 的游戏中。