下面是我写的一个表单,模拟了卖家发布信息的几个关键流程。
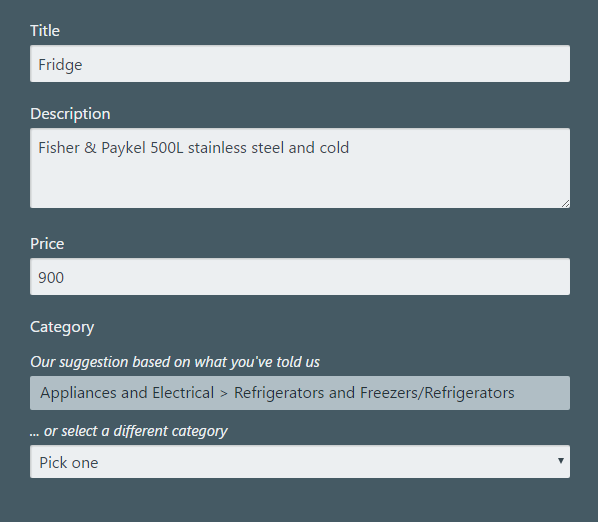
下面的结果一定会让你对机器学习保持兴趣。你只要相信我,建议类别是由深度学习模拟预测出来的。
让我们去卖一个冰箱
再来试一下卖个水族馆:

这个云机器人居然能识别出水族馆!
当我看到这个结果的时候,手舞足蹈,是不是棒棒哒?
(我偷偷的告诉你我是怎么实现的:React, Redux, JQuery, Mox, RxJs, BlueBird, Bootstrap, Sass, Compass, NodeJs, Express, Loadsh。项目是使用 webpack 打包。最后生成的文件在1M左右)
嗯。不 BB 了。开始讲正经事。
一开始为了拿到机器学习用的数据。我也是想破了头。我大概需要10K条数据。后来是在一个当地的交易网站上面发现有这些数据。看了一下 URL 和 DOM 结构之后,我用 Google Scraper 插件提取了一些数据。
导出成 CSV 文件。在这些数据上我大概花费了四个小时。将近整个项目时间的一半了。
数据整理好之后,上传到了 Amazon S3 上,配置了一下机器学习的参数,设置了数据模型。整个学习的 CPU 耗时才3分钟。
界面上还有一个实时预测功能,所以我打算用一些参数测试一下。
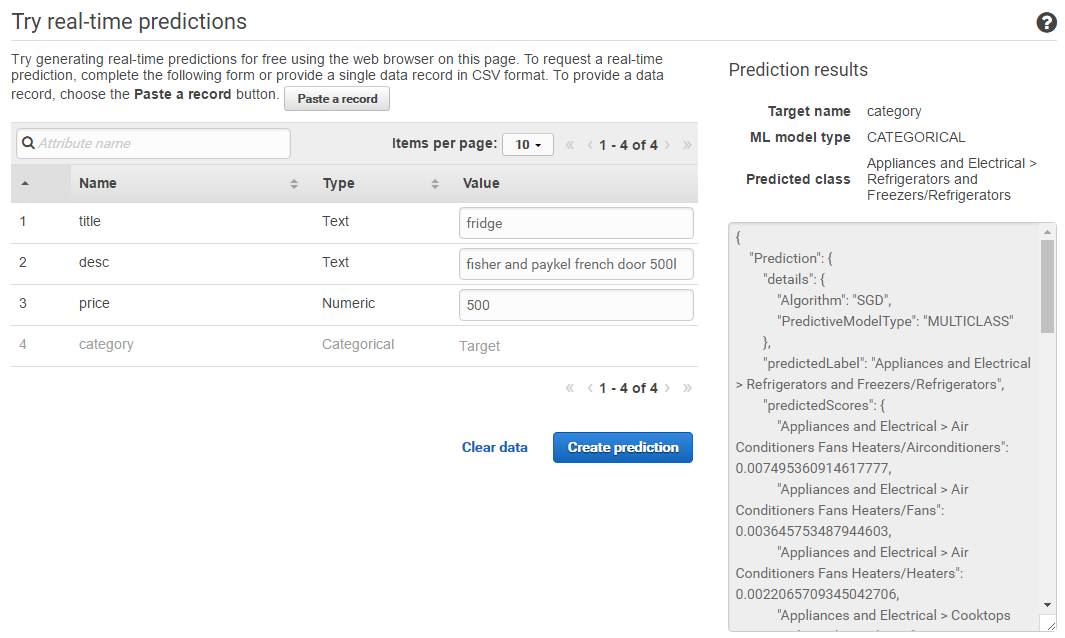
嗯。还挺好用的。
为了不在浏览器里面暴露出我的 Amazon API ,所以我把 API 放到了 Node 服务器上。





