选自makegirlsmoe
作者:Yingtao Tian
机器之心编译
参与:Pandas(经原作校对)
相信每个人都会被卡哇伊的二次元妹子萌到,我们很多人也可能梦想自己创作二次元人物,但奈何技艺不精、功力不足,得到的结果往往无法达到我们的期望。现在人工智能来帮你了!近日,来自复旦大学、纽约州立大学石溪分校和同济大学的一些研究者打造了一个基于 GAN 的动漫人物面部图像生成器,并且还开放了一个网页版本。研究者近日发表了一篇博客对该项研究进行了介绍。
我们都喜欢动漫人物,也可能会想自己创作一些,但我们大多数人因为没经过训练所以无法做到。如果可以自动生成专业水准的动漫人物呢?现在,只需指定金发/双马尾/微笑等属性,无需任何进一步干预就能生成为你定制的动漫人物!
在动漫生成领域,之前已经有一些先驱了,比如:
ChainerDCGAN:https://github.com/pfnet-research/chainer-gan-lib
Chainer を使ってコンピュータにイラストを描かせる:http://qiita.com/rezoolab/items/5cc96b6d31153e0c86bc
IllustrationGAN:https://github.com/tdrussell/IllustrationGAN
AnimeGAN:https://github.com/jayleicn/animeGAN
但这些模型得到的结果往往很模糊或会扭曲变形,要生成业界标准的动漫人物面部图像仍然是一大难题。为了帮助解决这一难题,我们提出了一种可以相当成功地生成高质量动漫人物面部图像的模型。
数据集:模型要想质量好,首先需要好数据集
要教计算机学会做事,就需要高质量的数据,我们的情况也不例外。Danbooru(https://danbooru.donmai.us)和 Safebooru(https://safebooru.org )等大规模图像讨论版的数据有很多噪声,我们认为这至少一定程度上解释了先前工作的问题所在,所以我们使用了在 Getchu 上销售的游戏的立绘(立ち絵)图像。Getchu 是一家展示日本游戏的信息并进行销售的网站。立绘具有足够的多样性,因为它们具有不同的风格,来自不同主题的游戏;但它们也具有很好的一致性,因为它们全部都是人物图像。
我们也需要分类的元数据(即标签/属性),比如头发颜色、是否微笑。Getchu 并没提供这样的元数据,所以我们使用了 Illustration2Vec,这是一个基于卷积神经网络的用于预测动漫标签的工具,地址:https://makegirlsmoe.github.io/main/2017/08/14/saito2015illustration2vec
模型:核心部分
为了实现我们的目标,就必须要有一个优秀的生成模型。这个生成器需要能理解并遵从用户给出的关于特定属性的要求,这被称为我们的先验(prior);而且它还需要足够的自由度来生成不同的详细的视觉特征,这是利用噪声(noise)建模的。为了实现这个生成器,我们使用了生成对抗网络(GAN)这种流行的框架。
GAN 使用一个生成器网络根据前提和噪声输入来生成图像,GAN 还有另一个网络会试图将生成的图像和真实图像区分开。我们同时训练这两个网络,最终会使得生成器生成的图像无法与对应前提下的真实图像区分开。但是众所周知要训练一个合适的 GAN 是非常困难的,而且非常耗时。幸运的是,利用最近发表的相关进展 DRAGAN,可以仅需相对很少的计算能力,就能实现可与其它 GAN 媲美的结果。我们成功训练了一个 DRAGAN,它的生成器类似于 SRResNet。
我们也需要我们的生成器能理解标签信息,这样才能将用户给出的要求整合进来。受 ACGAN 的启发,我们向生成器输入标签以及噪声,并在鉴别器的顶层增加了一个多标签分类器,用来预测图像所分配的标签。
使用这些数据和这个模型,我们就能在有 GPU 的机器上进行训练。
本节所涉及的技术:
GAN:https://papers.nips.cc/paper/5423-generative-adversarial-nets
DRAGAN:https://arxiv.org/abs/1705.07215
SRResNet:https://arxiv.org/abs/1609.04802
ACGAN:https://arxiv.org/abs/1610.09585
样例:一张图片胜过千言万语
为了一窥我们的模型的质量,请参看下面的图像,可见我们的模型能很好地处理不同的属性和视觉特征。

固定随机噪声并且采样随机先验是一个很有意思的设置。现在,该模型被要求生成具有相似主要视觉特征的图像,并与之同时结合不同的属性,结果也很不错:

另外,通过固定前提和采样随机噪声,该模型可以生成具有不同视觉特征,但具有相同属性的图像:

网页界面:在你的浏览器上使用神经生成器
为了将我们的模型提供给大家使用,我们使用 React.js 构建了一个网站界面,公开在:http://make.girls.moe。通过利用 WebDNN 并将训练后的 Chainer 模型转换成基于 WebAssembly 的 Javascript 模型,我们使得生成过程完全在浏览器上完成。为了更好的用户体验(因为用户在生成之前需要下载该模型),我们限制了生成器模型的大小。我们选择了 SRResNet 生成器,使得该模型比流行的 DCGAN 生成器小了好几倍,而且也不会影响到生成结果的质量。速度方面,即使所有的计算都在客户端上完成,一般生成一张图像也只需要几秒钟。
论文:使用人工智能创造动漫人物!(Create Anime Characters with A.I. !)

链接:https://makegirlsmoe.github.io/assets/pdf/technical_report.pdf
自从生成对抗网络(GAN)问世之后,面部图像的自动生成已经得到了很好的研究。在将 GAN 模型应用到动漫人物的面部图像生成问题上已经有过一些尝试,但现有的成果都不能得到有前途的结果。在这项成果中,我们探索了专门用于动漫面部图像数据集的 GAN 模型的训练。我们从数据和模型方面解决了这一问题——通过收集更加清洁更加合适的数据集以及利用 DRAGAN 的合适实际应用。通过定量分析和案例研究,我们表明我们的研究可以得到稳定且高质量的模型。此外,为了协助从事动漫人物设计的人,我们建立了一个网站,通过在线的方式提供了我们预训练的模型,从而让大众可以方便的访问模型。
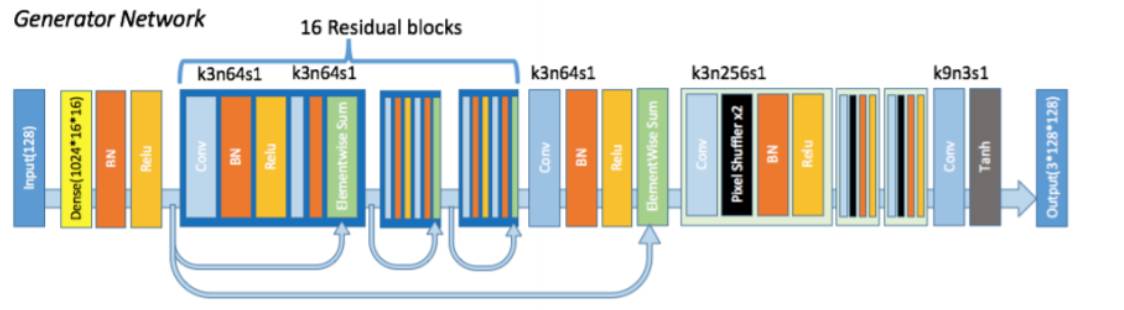
生成器架构
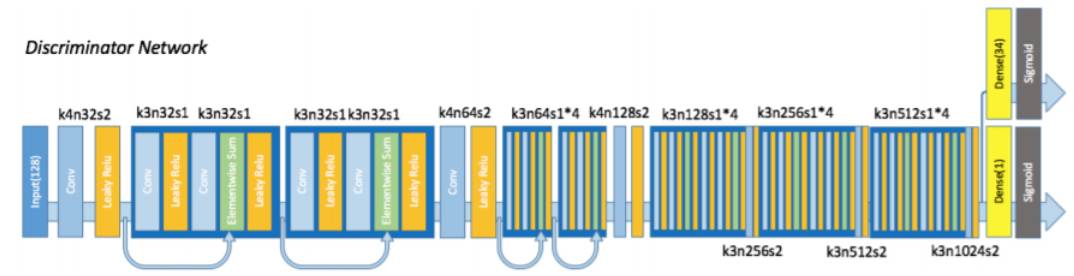
鉴别器架构 
原文链接:https://makegirlsmoe.github.io/main/2017/08/14/news-english.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]










