在大多数机器学习竞赛中,特诊工程的质量通常决定着整个作品的得分与排名,也是参赛者们非常看重的一部分。
在 GitHub 上,作者 Nomi(专注于计算机视觉与嵌入式技术,也是 tiny-dnn 的原作者)向我们介绍了一个面向 kaggle 数据科学和离线竞赛的实用工具库 nyaggle,可供开发者专用于特征工程与验证。

作者简介 来源:
Nomi
工具库 nyaggle
在机器学习和模式识别中,特征工程的好坏将会影响整个模型的预测性能。
其中特征是在观测现象中的一种独立、可测量的属性。
选择信息量大、有差别性、独立的特征是模式识别、分类和回归问题的关键一步,可以帮助开发者最大限度地从原始数据中提取特征以供算法和模型使用。
数据科学思维导图 来源:
网络
而 nyaggle 就是一个特定于 Kaggle 和离线比赛的实用工具库,它主要作用于四个部分,即:
特征工程、模型验证、模型实验以及模型融合,尤其在特征工程和模型验证方面有较强的性能。
其中,在特征工程方面,nyaggle 包含了 K 个特征目标编码和 BERT 句子向量化。
目标编码使用的是目标变量的均值编码类别变量,为训练集中的每个分组计算目标变量的统计量,之后会合并验证集、测试集以捕捉分组和目标之间的关系。
BERT 句子向量化则是对 Bert 模型的输入做一个向量化,提取词句的三维信息。
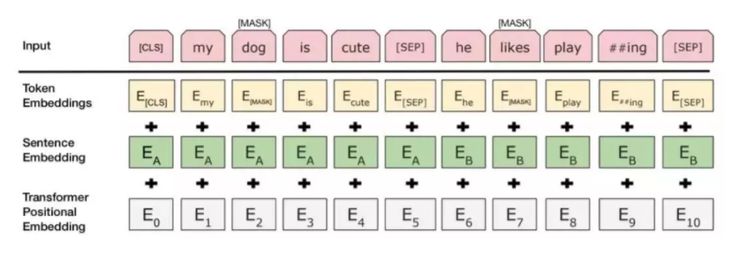
BERT 词句向量化示例 来源:
网络
nyaggle GitHub 地址:
https://github.com/nyanp/nyaggle
nyaggle 实验指南
API 详情说明:
nyaggle.experiment 类,实现模型实验的各个功能
classnyaggle.experiment.Experiment(logging_directory, overwrite=False, custom_logger=None, with_mlflow=False, mlflow_run_id=None, logging_mode='w')
nyaggle.experiment.add_leaderboard_score(logging_directory, score)
nyaggle.experiment.average_results(source_files, output_filename, weight=None, input_format='csv', sample_submission_filename=None)
nyaggle.experiment.find_best_lgbm_parameter(base_param, X, y, cv=None, groups=None, time_budget=None, type_of_target='auto')
nyaggle.experiment.run_experiment(model_params,X_train,y,X_test = None,logging_directory ='output / {time}',overwrite = False,eval_func = None,algorithm_type ='lgbm',fit_params = None,cv = None,groups = None,categorical_feature = None,sample_submission = None,submission_filename = None,type_of_target ='auto',feature_list = None,feature_directory = None,with_auto_hpo = False,with_auto_prep = False,with_mlflow = False)
实验详细代码
在典型的表格数据竞赛中,开发者可能会通过交叉验证重复进行评估,并记录参数和结果以跟踪实验。
其中,run_experiment()正是用于此类交叉验证实验的高级 API,它在指定目录下输出参数、指标、异常预测、测试预测、功能重要性和 Submitting.csv。
它可以与 mlflow 跟踪结合使用,如果使用 LightGBM 作为模型,则代码将非常简单如下所示:
import pandas as pdfrom nyaggle.experiment import run_experimentfrom nyaggle.experiment import make_classification_dfINPUT_DIR = '../input'target_column = 'target'X_train = pd.read_csv(f'{INPUT_DIR}/train.csv')X_test = pd.read_csv(f'{INPUT_DIR}/test.csv')sample_df = pd.read_csv(f'{INPUT_DIR}/sample_submission.csv') y = X_train[target_column]X_train = X_train.drop(target_column, axis=1)lightgbm_params = { 'max_depth': 8}result = run_experiment(lightgbm_params, X_train, y, X_test, sample_submission=sample_df)
值得注意的是,默认的验证策略是包含了 5 个特征的计算机视觉,开发者可以通过传递 cv 参数来更改此行为(可参阅 API 参考,
https://nyaggle.readthedocs.io/en/latest/source/nyaggle.html#
)。
之后,run_experiment API 执行交叉验证后,会将工件存储到日志目录。
输出文件存储如下:
output└── 20200130123456 # yyyymmssHHMMSS ├── params.txt # Parameters ├── metrics.txt # Metrics (single fold & overall CV score) ├── oof_prediction.npy # Out of fold prediction ├── test_prediction.npy # Test prediction ├── 20200130123456.csv # Submission csv file ├── importances.png # Feature importance plot ├── log.txt # Log file └── models # The trained models for each fold ├── fold1 ├── fold2 ├── fold3 ├── fold4 └── fold5
而如果要使用 XGBoost、CatBoost 或其他 sklearn 估计器,则需要在代码开头指定算法类型,其中的参数将传递给 sklearn API 的构造函数(例如 LGBMClassifier)。
'eval_metric': 'Logloss', 'loss_function': 'Logloss', 'depth': 8, 'task_type': 'GPU'}result = run_experiment(catboost_params, X_train, y, X_test, algorithm_type='cat') 'objective': 'reg:linear', 'max_depth': 8}result = run_experiment(xgboost_params, X_train, y, X_test, algorithm_type='xgb') 'alpha': 1.0}result = run_experiment(rigde_params, X_train, y, X_test, algorithm_type=Ridge)
如果想让 GUI 仪表板管理实验,开发者则可以通过只设置 with_mlfow = True 来将 run_experiment 与 mlflow 一起使用(需要预先安装 mlflow)。
然后在与执行脚本相同的目录中,运行即可。
result = run_experiment(params, X_train, y, X_test, with_mlflow=True)
然后在与执行脚本相同的目录中,运行即可,相关结果(带有 CV 得分和参数的实验列表)可在 http:
//localhost:
5000 页面上查看。








