当前这篇文章至少比计划拖后了两个月。在上一篇文章《
条分缕析分布式:到底什么是一致性?
》中,我们仔细辨析了「一致性」相关的几个容易混淆的概念。而在本文中,我们会沿着逐步深入的思路,跟大家继续讨论顺序一致性、线性一致性、最终一致性等几个概念。
为了避免产生歧义,我们先明确一下这几个概念的英文表达:
-
顺序一致性的英文是:
sequential consistency
。
-
线性一致性的英文是:
linearizability
。实际上,它就是CAP定理中的C,我们在
上一篇文章
中已经提到过。
-
最终一致性的英文是:
eventual consistency
。
在进行详细的技术性讨论之前,我们先把本文要讨论的几个重点问题和结论列出如下:
-
线性一致性和顺序一致性,属于分布式系统的一致性模型 (
consistency model
)。这代表了分布式系统的一个非常非常重要的方面。
-
通常人们把线性一致性称为「强一致性」,把最终一致性称为「弱一致性」,但线性一致性和最终一致性其实存在本质的区别。严格来说,它们并不是一个范畴的概念。
-
一致性模型之间的「强弱」比较,是一个相对的概念。比如,线性一致性是比顺序一致性更强的一致性模型。当然,除了线性一致性和顺序一致性,也存在其它一些一致性模型(其中很多都比顺序一致性要弱)。
-
满足线性一致性的系统,也必定满足顺序一致性,但反过来不一定。这是由一致性模型之间的强弱关系决定的。
下面,我们就开始详细的解析。
我们之所以使用分布式系统,无非是因为分布式系统能带来一些「好处」,比如容错性、可扩展性等等。为了获得这些「好处」,分布式系统实现上常用的方法是复制 (
replication
) 和分片 (
sharding
)。而我们将要讨论的一致性模型 (
consistency model
),主要是与复制有关。因此这里我们先关注一下复制的机制。
复制指的是将同一份数据保存在多个网络节点上。而保存同一份数据拷贝的节点,被称为副本 (replica)。复制带来的具体「好处」主要是体现在两个方面:
一方面,复制带来了诸多好处;另一方面,它也带来了很多挑战,其中最重要的一个就是数据的一致性问题。由于同一份数据保存在了多个副本节点上,它们之间就存在数据不一致的风险。我们当然希望同一份数据的不同副本总是保持一致。换句话说,我们希望在其中一个副本上所做的修改,在其它副本上也能随时观察到(即读取到)。
当然我们心里都清楚,让所有副本在任何时刻都保持一致,是不可能的。因为副本之间的数据同步即使速度再快,也是需要时间的。不过幸运的是,我们其实并不关心所有时刻的数据一致性情况。只要系统能够保证,每当我们去「观察」的时候(即读取数据副本的时候),系统表现出来的行为是一致的,就可以了。换句话说,即使在两次「观察」之间,系统内部出现了短暂的数据不一致的情况,只要系统保证外部用户无论如何都发现不了,我们也是可以满意的。
这意味着,我们应该从系统用户(使用系统的开发者)的角度,来对数据一致性的要求进行定义。
实际上,早期的分布式系统设计者们对系统设计的要求,也是按照类似的思路进行的。在理想情况下,系统应该维持类似SSI (
single-system image
)[1]或
distribution transparency
[2]的特性。这两个概念要表达的核心意思是,系统内部有关分布式实现的复杂性应该对系统的外部用户透明;也就是说,对于系统的外部用户来说,系统应该表现得就好像只有一个单一的副本一样。如果系统能够提供这种「单一系统视图」或「透明性」,那么系统的使用者就能以比较简单的方式来使用系统;否则就可能带来很大的负担。
系统“表现得就好像只有一个单一的副本”,这是一个相当「笼统」的说法。在此我们讨论3个具体的例子:
-
我们先向一个副本节点写入
x
=42,然后读取数据对象
x
的值。显然,不管我们从哪个副本节点上进行读取,我们都希望读到最新写入的值(也就是42)。只有这样才合理。
-
两个系统用户分别在两个副本节点上同时执行写操作。其中,用户A在第1个副本上执行
x
=42;用户B在第2个副本上执行
x
=43。然后用户C读取
x
的值。虽然两个写操作是「同时」进行的,但为了让系统“表现得像只有一个副本”,我们还是需要对它们进行一个先后排序。又因为它们是「同时」执行的,所以谁先谁后都有可能是合理的。如果我们认为
x
=42在
x
=43之前先执行,那么读取到的
x
的值就应该是43;反过来,如果我们认为
x
=43在x=42之前先执行,那么读取到的
x
的值就应该是42。
-
用户A先在第1个副本上执行
x
=42,然后用户B再在第2个副本上执行
x
=43,最后用户C在第3个副本上读取
x
的值。仍然为了让系统“表现得像只有一个副本”,直觉上看,用户C读取到的
x
的值似乎应该是43。但是,也不一定非要如此。因为两个写操作是分别由用户A和用户B发起的,他们并不知道彼此谁先谁后(虽然从时间上看用户A的写操作确实在先)。所以,我们也可以选择认为用户B执行
x
=43在用户A执行
x
=42之前。这样的话,用户C读取到的
x
的值就应该是42。当然,根据本文后面的讨论,这种排序就不满足线性一致性了,但却满足顺序一致性。
从这些例子不难看出,一个系统在数据一致性上的具体表现如何,取决于系统对关键事件(读写操作)的排序和执行采取什么样的规则和限制。比如在上面第3个例子中,出现了两种对于读写操作的排序。前一种排序是:
-
用户A执行
x
=42。
-
用户B执行
x
=43。
-
用户C读取到
x
的值是43。
而第3个例子中的后一种排序是:
-
用户B执行
x
=43。
-
用户A执行
x
=42。
-
用户C读取到
x
的值是42。
虽然这两种排序结果不同,但它们都做到了让系统“表现得像只有一个副本”。它们的不同在于,前一种排序遵循了不同用户的操作的时间先后顺序,而后一种排序没有。实际上,如果我们要求系统满足线性一致性,就只能得到前一种排序结果;而如果只要求系统满足顺序一致性,就有可能得到后一种排序结果(等看完本文后面的讨论,你就能自己得到这些结论)。
可以这么说,一个分布式系统对于读写操作的某种排序和执行规则,就定义了一种一致性模型 (
consistency model
)。当一个系统选定了某种特定的一致性模型(比如线性一致性或顺序一致性),那么你就只能看到这种一致性模型所允许的那些操作序列。还是拿前面第3个例子来说明:如果你选定了线性一致性模型,那么系统就不会向你呈现后一种排序,你只能看到前一种排序。
另外,在前面的三个例子中,不管系统最终给出了哪种排序结果,所有系统的用户其实都对那种操作序列达成了一致的看法。还有一些一致性模型,并不要求所有用户对操作排序的结果达成唯一的一种看法。这样的一致性模型稍显复杂,我们会放在下一篇文章中再讨论(比如因果一致性)。
接下来,为了更清晰地认识一致性模型,我们来深入到线性一致性和顺序一致性的一些细节中去。
在讨论之前,我们先把组成分布式系统的一些关键概念定义清楚:
-
整个系统可以看成由多个
进程
和一个共享的
数据存储
组成。对于数据存储的读写操作由进程发起。这里的进程,相当于本文前面提到的系统用户或系统使用者。
-
同一个进程发起的读写操作是先后顺序执行的。注意,这里的「进程」概念跟我们平常编程时用到的进程有所不同,进程里面不再分多个线程了。
-
数据存储可能有多个副本,但我们在讨论一致性模型的时候,把它看成一个整体来看待,不区分读写操作提交到了具体哪个副本上。
-
每个操作的执行,从开始调用到执行结束,都需要花一定的时间。因此,一个进程发起的操作还没有执行完的时候,另一个进程的操作可能就已经开始了。
可见,系统的多个进程是并发执行的。下面我们通过一个例子来说明这种并发执行的情况,进而解释顺序一致性的概念。
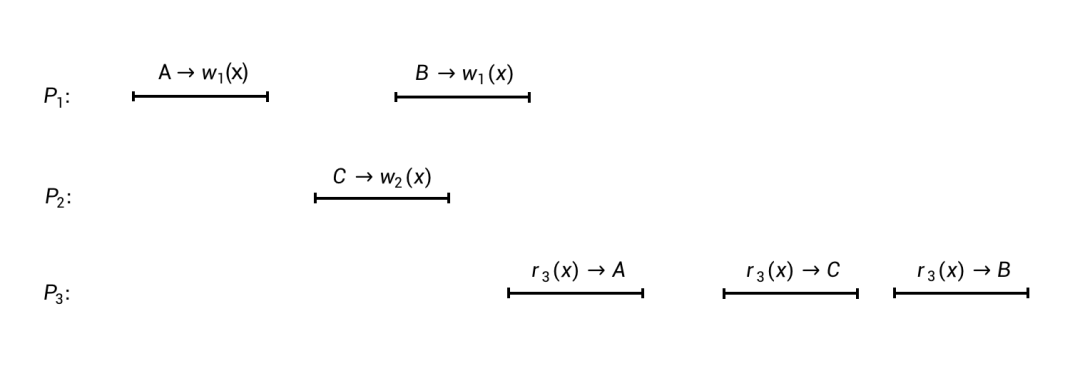
上面是一个类似「时空图」的图像,表达了3个进程(
P
1
、
P
2
和
P
3
)对于数据存储的读写执行过程。在这个图中,横向从左到右表示时间递增,黑色的线段表示每个操作的执行起止。线段上面的符号表示具体的读写操作:
现在我们要考察的问题是:上图的这样一个执行过程,是否满足顺序一致性?要回答这个问题,我们首先得知道顺序一致性的定义是什么。
顺序一致性
定义[3,4]:如果一个并发执行过程所包含的所有读写操作能够重排成一个全局线性有序的序列,并且这个序列满足以下两个条件,那么这个并发执行过程就是满足顺序一致性的:
以上图的执行过程为例,我们重排所有的6个读写操作,可以得到如下的有序序列:
-
A
-->
w
1
(
x
)
-
r
3
(
x
) -->
A
-
C
-->
w
2
(
x
)
-
r
3
(
x
) -->
C
-
B
-->
w
1
(
x
)
-
r
3
(
x
) -->
B
很容易看出,这个序列是满足前面顺序一致性定义中的两个条件的:
-
条件I:在这个重排后的序列中,每个读操作都返回了前面最近一次写入的值,比如第2个操作读到的值
A
,是前面第1个操作写入的;第4个操作读到的值
C
,是前面第3个操作写入的。
-
条件II:原来进程
P
1
中的两个写操作,
A
-->
w
1
(
x
)和
B
-->
w
1
(
x
),在这个重排后的序列中仍然保持了先后顺序。与此类似,原来进程
P
3
中的3个读操作,在这个重排后的序列中也保持了原来的先后顺序。
所以现在我们可以回答前面的问题了:上图中的执行过程,是满足顺序一致性的。
你可能会问,顺序一致性为什么会这样定义呢?这个定义的初衷是什么?
我们可以试着这样理解:首先,重排成一个全局线性有序的序列,相当于系统对外表现出了一种「假象」,原本多进程并发执行的操作,好像是顺序执行的一样。本文前面提到过,理想情况下,分布式系统应该“表现得像只有一个副本”一样。顺序一致性正是遵循了这种「系统假象」,系统对外表现就好像在操作一个单一的副本,执行顺序也必然是可以看做顺序执行的。而条件I规定了系统的表现是合理的(即合乎逻辑的);条件II则保证了以任何进程的视角来看,它所发起的操作执行顺序都是符合它原本的预期的。总之,一个满足顺序一致性的系统,对外表现就好像总是在操作一个副本一样。
我们再通过一个例子来看一看这个问题的反面——不满足顺序一致性的执行过程是怎样的。
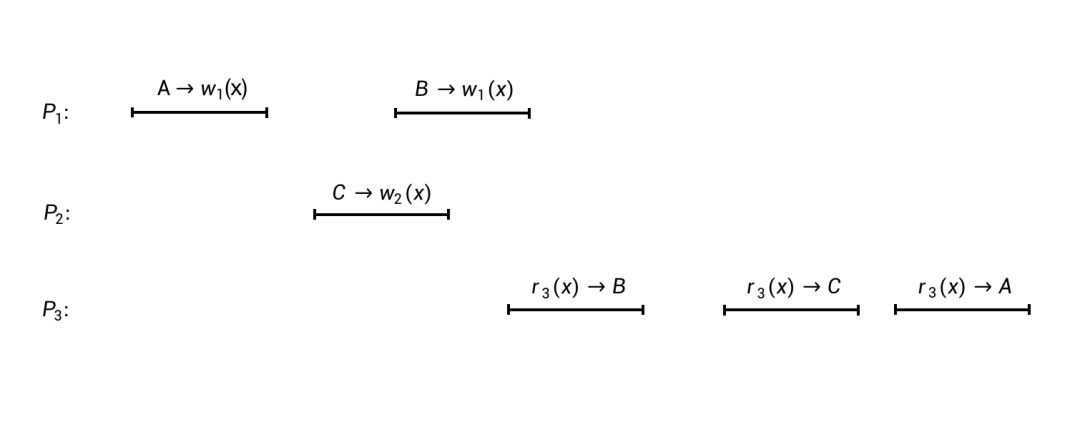
这个图中的执行过程,与前面第一个图的执行过程非常相似,只是进程
P
3
的几个操作的执行顺序稍有变化。
我们根据前面顺序一致性的定义再来试着对这个执行过程中的所有操作进行重排:首先根据条件II和进程
P
1
的执行顺序,我们知道,
A
-->
w
1
(
x
)一定要排在
B
-->
w
1
(
x
)前面;再根据条件I,进程
P
1
的
B
-->
w
1
(
x
)一定要排在进程
P
3
的
r
3
(
x
) -->
B
前面。最后,再结合条件II和进程
P
3
的执行顺序,我们能够得出结论,进程
P
1
和进程
P
3
的所有操作,在最终重排后的完整序列中,必然保持以下的顺序:
-
A
-->
w
1
(
x
)
-
B
-->
w
1
(
x
)
-
r
3
(
x
) -->
B
-
r
3
(
x
) -->
C
-
r
3
(
x
) -->
A
我们会发现,上面的序列有两个地方不满足条件I:
我们还剩一个进程
P
2
的写操作,即
C
-->
w
2
(
x
),没有放到最后这个序列中。也许我们可以试着将它放置到第3和第4个操作之间,这样就能把前面第一个不满足条件I的地方修复掉。但无论如何,也无法得到一个完全符合条件I和条件II的完整序列了。因此,前面第二个图中的执行过程,是不满足顺序一致性的。进一步说,如果一个系统的执行呈现出了这样的一种执行过程(如前面第二个图所示),那我们可以肯定地说,这个系统是没有遵守顺序一致性的。
我们再来考察一下线性一致性的概念。线性一致性的定义[5],与顺序一致性非常相似,也是试图把所有读写操作重排成一个全局线性有序的序列,但除了满足前面的条件I和条件II之外,还要同时满足一个条件:
根据最新定义的条件III,我们来重新评判一下前面第一个图所展现出来的执行过程是不是满足它。为了阅读和讨论方便,我们把第一个图重新展示在下面:





