
本文简要介绍
CVPR2020
录用论文
“SwapText: Image Based Texts Transfer in Scenes”
的主要工作。该论文主要针对自然场景图片文字替换问题,提出了一个包含三个子网络的文本图像分割迁移方法,可以做到在保留场景文字风格的情况下替换文字内容,替换后的文字与背景无缝融合,在视觉上达到了十分逼真的效果。
文字替换任务与许多任务和应用相关,如文字检测、文字识别、海报文字修改、图像文字翻译以及其他一些具有创意性的应用。目前对于检测和识别任务来说,难以获得大量含标注信息数据已经成为限制其性能提升的一个瓶颈。常见且简单的数据增广方法有平移、旋转、镜像等。近期也有研究
[1][2][3]
提出利用合成数据进行训练。但这些数据与真实场景中的数据还是存在较大差距。而文字替换则可以生成接近真实场景的含标注信息的数据,其对检测和识别任务而言是十分有用的数据增广方法。
图
2
是这篇文章所提方法的整体结构,
由于场景文字复杂多样,本文方法采取模块分解的思路将前景和背景分开进行处理。网络
主要可以分为
3
个部分,分别是
Text Swapping Network、Background Completion Network
和
Fusion Network
。
Text Swapping Network
:
该网络主要学习生成目标图像的前景部分也就是文字内容,包括文字的几何形状以及字体风格两个方面。几何形状上,一个轻量级全连接网络被用于从风格图像
I
s
的解码器中得到输入并回归出控制点(表征文字内容的几何形状),该回归过程通过
Smooth
L1
Loss
进行监督。得到控制点后对内容图像
Ic
进行
TPS
变换从而达到改变其几何形状的目的。
字体风格迁移:
几何变形后的图像
Ic
与
Is
一样经过
Encoder
和
Resnet Block
进行特征提取。得到的特征
Concat
在一起之后喂入一个自注意力(
Self-attention
)网络用来学习两者特征之间的联系。此外,这里作者还提出用一个多层次的自注意力网络来进一步利用全局信息,如图
3(b)
所示。然后通过
Decoder
输出字体风格改变后的图像
Ic
,该输出由
L2 Loss
进行监督。

图
3 (a)
自注意力网络,
(b)
多层次自注意力网络
Background Completion Network:
主要负责将输入风格图片中的文字进行擦除,同时修复纹理信息,保证生成的背景图片无瑕疵、自然清晰。该网络采用
Encoder-decoder
的结构,在
Encoder
之后采用了空洞卷积(
Dilated Convolutional Layer
)以提高感受野。此外该网络还将编码器和解码器的特征图使用跳跃连接进行信息传递,同时将解码器的特征输入到随后的融合模块解码阶段,辅助融合过程,有效改善背景模糊和虚影的情况。该过程通过条件
GAN Loss
和
L1 Loss
进行监督,如公式
1
(
Background Completion Network
的损失函数)
所示。

F
usion Network:
负责将生成好的前景和背景进行有机融合,产生最终结果。在这个部分本文将前景图片编码后的特征结合背景填充模块解码阶段的特征,使得前景和背景能适宜、渐进地进行无缝结合。该模块的损失函数由
L1 Loss
,条件
GAN Loss
以及
VGG Loss
(包含两部分)。
VGG Loss
如公式
2
所示。
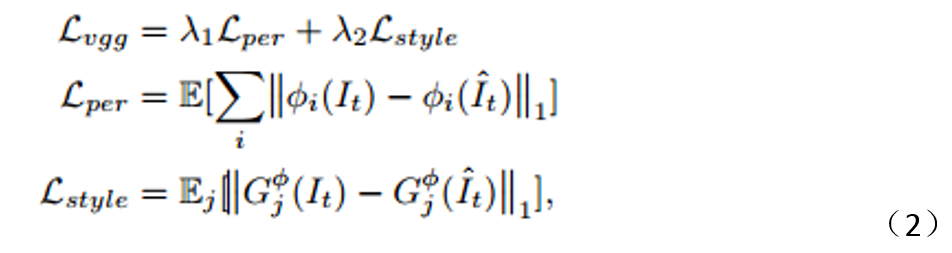
整个网络利用合成数据进行端到端的训练。






图
7
在
IC15
和
IC17
数据集上的替换效果
从图
4
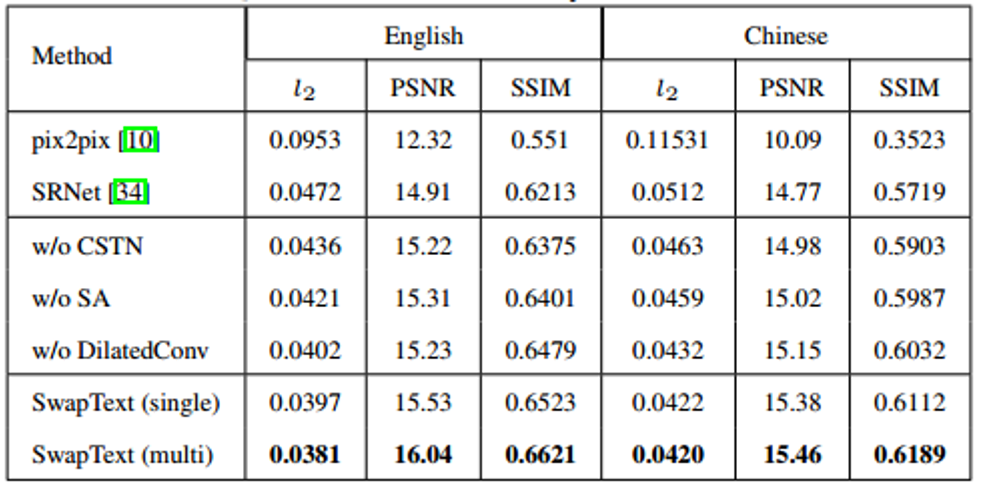
和表
1
中的消融实验结果可以看到,文中采用的几何形状转化、空洞卷积、自注意力网络、多层次自注意力网络等策略都具有各自的有效性。此外,图
4
和表
1
还验证了文章方法优于
Pix2pixp[4]
和
SRNet[5]
。进一步的,表
2
和表
3
分别利用检测和识别效果验证文章所提出方法在生成图像的真实性方面具有比
Pix2pixp
和
SRnet
更好的效果。图
5
验证了不同语言文字间替换的有效性。更多可视化效果如图
7
中所示。此外,由于训练数据有限,此方法有时还不能很好的覆盖现实场景中文字的几何形变和字体样式空间,因此还不能很好处理图6
中所示的波浪形的文字。在
IC15
和
IC17
数据上的可视化效果如图
7
所示。
本文提出了一种用于自然场景文本替换任务的端到端网络,它可以在保持场景文本图像原有风格的同时,替换其中的文字内容,并与原图片达到一致的可视化效果。实现这一功能主要分为三个步骤:(
1
)
Text Swapping Network
:提取代待替换图像的前景文字的几何形状和风格特征,并将其转换到输入文本图像上;(
2
)
Background Completion Network
:擦除风格图片中的文字并用合适的纹理修复,得到背景图像,并把
Decoder
中的权值共享给F
usion Network
;(
3
)
Fusion Network
:将被转换的文本与已擦除的背景合并。
本文
的方法在主观视觉真实性和客观定量评分方面取得了优异的结果。同时,该网络还具有跨语言替换的能力,
本文还










