AI科技评论按:本文内容来自新加坡国立大学【
机器学习与视觉实验室
】
负责人
冯佳时博士在【
硬创公开课
】的分享。冯佳时博士梳理了关于生成对抗网络(GAN)的全景图,解答了
涉及GAN方方面面的问题,包括其
基本框架、原理、应用案例、优缺点、发展方向等,感谢冯佳时老师及其实验室同学为本次公开课精心的筹备工作。另外,如果各位读者想要获得本次公开课的PPT,可在后台回复关键词【GAN】,即可下载。
近年来,基于数据而习得“特征”的深度学习技术受到狂热追捧,而其中GAN模型训练方法更加具有激进意味:
它生成数据本身
。
GAN是“生成对抗网络”(Generative Adversarial Networks)的简称,由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域。2016年,GAN热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨。Yann LeCun曾评价GAN是“
20年来机器学习领域最酷的想法
”。
在GAN这片新兴沃土,除了Ian Goodfellow所在的OpenAI在火力全开,Facebook的人工智能实验室也在这一领域马不停蹄深耕,而苹果近日曝出的首篇AI论文,就是基于GANs的变种“SimGAN”。从学术界到工业界,GANs席卷而来。
经360首席科学家、人工智能研究院院长颜水成强力推荐,【硬创公开课】特邀冯佳时博士,在1月5日为大家带来了一期以《深度学习新星:GANs的诞生与走向》为主题的演讲,拨开围绕GANs的迷雾。
|
嘉宾介绍
冯佳时,现任新加坡国立大学电子与计算机工程系助理教授,机器学习与视觉实验室负责人。
中国科学技术大学自动化系学士,新加坡国立大学电子与计算机工程系博士。2014-2015年在加州大学伯克利分校人工智能实验室从事博士后研究。现研究方向为图像识别、深度学习及面向大数据的鲁棒机器学习。
冯佳时博士曾获ICCV’2015 TASK-CV最佳论文奖,2012年ACM多媒体会议最佳技术演示奖。担任ICMR 2017技术委员会主席,JMLR, IEEE TPAMI, TIP, TMM, TCSVT, TNNLS及 CVPR, ICCV, ECCV, ICML, NIPS, AAAI, IJCAI等期刊、会议审稿人。冯佳时博士已在计算机视觉、机器学习领域发表论文60余篇。

以下内容整理自公开课分享。
GANs是深度学习领域比较重要的一个模型,也是人工智能研究的一个重要工具。
我们现在所追求的人工智能,
一个很重要的特性就是能够像我们人类一样,理解周围复杂的世界
。包括识别和理解现实中的三维世界,人类、动物和各种工具。这样才能在对现实世界理解的基础上,进行推理和创造。
而正像著名物理学家,理查德•费曼说的一样,如果要真正理解一个东西,我们必须要能够把它创造出来。

正是基于这样的想法,机器学习以及人工智能的研究者们提出了概率生成模型,致力于用概率和统计的语言,描述周围的世界。
|
作为一种概率生成模型:GAN
简单说,
概率生成模型的目的,就是找出给定观测数据内部的统计规律,并且能够基于所得到的概率分布模型,产生全新的,与观测数据类似的数据
。
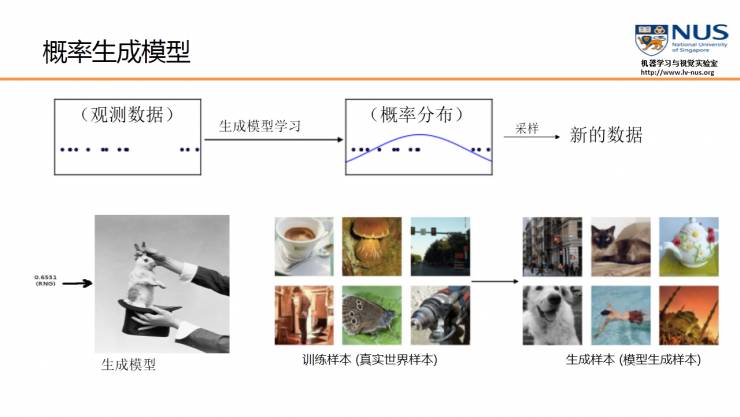
举个例子,概率生成模型可以用于自然图像的生成。假设给定1000万张图片之后,生成模型可以自动学习到其内部分布,能够解释给定的训练图片,并同时生成新的图片。
与庞大的真实数据相比,概率生成模型的参数个数要远远小于数据的数量。因此,在训练过程中,生成模型会被强迫去发现数据背后更为简单的统计规律,从而能够生成这些数据。
现在比较流行的生成模型,其实可以分为三类:
-
生成对抗网络(GAN)
。这个是我们今天要重点介绍的内容。
-
变分自动编码模型(VAE)
。它依靠的是传统的概率图模型的框架,通过一些适当的联合分布的概率逼近,简化整个学习过程,使得所学习到的模型能够很好地解释所观测到的数据。
-
自回归模型(Auto-regressive)
。在这种模型里,我们简单地认为,每个变量只依赖于它的分布,只依赖于它在某种意义上的近邻。例如将自回归模型用在图像的生成上。那么像素的取值只依赖于它在空间上的某种近邻。现在比较流行的自回归模型,包括最近刚刚提出的像素CNN或者像素RNN,它们可以用于图像或者视频的生成。
|
GAN热度从学术界蔓延至工业界
这三种生成模型都有各自的优缺点,然后也在不同的领域上得到广泛的关注。而今天我们要介绍的GAN实际上是一种比较年轻的方法。两年半之前, Ian Goodfellow的一篇论文首次将其引入,虽然时间很短,但我们看Google的搜索热度和Google学术上论文引用的次数,它一直受到学术界广泛的关注,而且热度一直快速增长。
除了学术界,GAN还受到工业界的广泛关注。
有许多做人工智能研究的公司正在投入大量的精力来发展和推广GAN模型
。其中包括 Ian Goodfellow 如今所在的 OpenAI 公司。这个公司一直在致力于研究推广GAN,并将其应用在不同的任务上。同时 Facebook 和 Twitter 最近两年也投入了大量的精力来研究,并将GAN应用在了图像生成和视频生成上。尤其值得一提的是,Apple最近发表了其关于人工智能研究的首篇论文,恰恰是应用GAN来做数据的生成,帮助更好地训练机器学习模型。

那么,GAN为什么会受到这样广泛的关注呢?
Goodfellow在他的论文中,给出了一些解释。

GAN是更好的生成模型,在某种意义上避免了马尔科夫链式的学习机制
,这使得它能够区别于传统的概率生成模型。传统概率生成模型一般都需要进行马可夫链式的采样和推断,而GAN避免了这个计算复杂度特别高的过程,直接进行采样和推断,从而提高了GAN的应用效率,所以其实际应用场景也就更为广泛。
其次
GAN是一个非常灵活的设计框架
,各种类型的损失函数都可以整合到GAN模型当中,这样使得针对不同的任务,我们可以设计不同类型的损失函数,都会在GAN的框架下进行学习和优化。
再次,最重要的一点是,当概率密度不可计算的时候,传统依赖于数据自然性解释的一些生成模型就不可以在上面进行学习和应用。
但是GAN在这种情况下依然可以使用
,这是因为GAN引入了一个非常聪明的内部对抗的训练机制
,可以逼近一些不是很容易计算的目标函数。
Facebook人工智能研究院的Yann LeCun也一直是GAN的积极倡导者。其中一个最重要的原因就是GAN为无监督学习提供了一个强有力的算法框架,而无监督学习被广泛认为是通往人工智能重要的一环。就像Yann LeCun所给出的一个比喻一样:
“如果人工智能是一块蛋糕,那么强化学习是蛋糕上的一粒樱桃,监督学习是外面的一层糖霜,无监督/预测学习则是蛋糕胚。目前我们只知道如何制作糖霜和樱桃,却不知如何制作蛋糕胚。“

虽然还在快速的发展当中,但是GAN确实为无监督学习,提供了一个非常有潜力的解决方案。
|
朴素GAN的基本框架
一个最朴素的GAN模型,实际上是将一个随机变量(可以是高斯分布,或0到1之间的均匀分布),通过参数化的概率生成模型(通常是用一个神经网络模型来进行参数化),进行概率分布的逆变换采样,从而得到一个生成的概率分布(图中绿色的分布模型)。
而GAN的或者一般概率生成模型的训练目的,就是要使得生成的概率分布和真实数据的分布尽量接近,从而能够解释真实的数据。但是在实际应用中,我们完全没有办法知道真实数据的分布。我们所能够得到的只是从这个真实的数据分布中所采样得到的一些真实数据。

通过优化目标,使得我们可以调节概率生成模型的参数\theta,从而使得生成的概率分布和真实数据分布尽量接近。
那么怎么去定义一个恰当的优化目标或一个损失?传统的生成模型,一般都采用数据的似然性来作为优化的目标,但
GAN创新性地使用了另外一种优化目标
。首先,它引入了一个判别模型(常用的有支持向量机和多层神经网络)。其次,它的优化过程就是在寻找生成模型和判别模型之间的一个纳什均衡。
GAN所建立的一个学习框架,
实际上就是生成模型和判别模型之间的一个模仿游戏
。生成模型的目的,就是要尽量去模仿、建模和学习真实数据的分布规律;而判别模型则是要判别自己所得到的一个输入数据,究竟是来自于真实的数据分布还是来自于一个生成模型。通过这两个内部模型之间不断的竞争,从而提高两个模型的生成能力和判别能力。

如果我们把生成模型比作是一个
伪装者
的话,那么判别模型就是一个
警察
的角色。伪装者的目的,就是通过不断的学习来提高自己的伪装能力,从而使得自己提供的数据能够更好地欺骗这个判别模型。而判别模型则是通过不断的训练来提高自己判别的能力,能够更准确地判断数据来源究竟是哪里。

当一个判别模型的能力已经非常强的时候,如果生成模型所生成的数据,还是能够使它产生混淆,无法正确判断的话,
那我们就认为这个生成模型实际上已经学到了真实数据的分布
。
|
GAN的基本原理
GAN模型包括了一个生成模型G和一个判别模型D,GAN的目标函数是关于D与G的一个零和游戏。也是一个最小-最大化问题。
这里判别模型D实际上是对数据的来源进行一个判别:究竟这个数据是来自真实的数据分布Pdata,还是来自于一个生成模型G所产生的一个数据分布Pg。
判别模型D的训练目的就是要尽量最大化自己的判别准确率
。当这个数据被判别为来自于真实数据时,标注 1,自于生成数据时,标注 0。
而与这个目的相反的是,
生成模型G的训练目标,就是要最小化判别模型D的判别准确率
。在训练过程中,GAN采用了一种非常直接的交替优化方式,它可以分为两个阶段,第一个阶段是固定判别模型D,然后优化生成模型G,使得判别模型的准确率尽量降低。而另一个阶段是固定生成模型G,来提高判别模型的准确率。
下面这张图,可视化了GAN学习的过程,从左到右是随着训练过程的进展,依次得到的训练结果。

图(a)中黑色大点虚线P(x)是真实的数据分布,绿线G(z)是通过生成模型产生的数据分布(输入是均匀分布变量z,输出是绿色的曲线)。蓝色的小点虚线D(x)代表判别函数。
在图(a)中,我们可以看到,绿线G(z)分布和黑色P(x)真实分布,还有比较大的差异。这点也反映在蓝色的判别函数上,判别函数能够准确的对左面的真实数据输入,输出比较大的值。对右面虚假数据,产生比较小的值。但是随着训练次数的增加,图(b)和图(c)反映出,绿色的分布在逐渐靠近黑色的分布。到图(d),产生的绿色分布和真实数据分布已经完全重合。这时,
判别函数对所有的数据(无论真实的还是生成的数据),输出都是一样的值,已经不能正确进行分类
。G成功学习到了数据分布,这样就达到了GAN的训练和学习目的。
但是GAN有一些待加强的理论保证,其中一个是说,GAN是存在全局最优解的。这个全局最优解可以通过一些简单的分析得到。首先,如果固定G,那么D的最优解就是一个贝叶斯分类器。将这个最优解形式带入,可以得到关于G的优化函数。简单的计算可以证明,当产生的数据分布与真实数据分布完全一致时,这个优化函数达到全局最小值。

另外一点,是关于GAN的收敛性。如果G和D的学习能力足够强,两个模型可以收敛。但在实际中,GAN的优化还存在诸如不稳定等一些问题。如何平衡两个模型在训练中是一个很重要的问题。
GAN的优点很多,前面我们提到了一部分。这里要提到的一个重要优点,就是
生成模型G的参数更新不是来自于数据样本本身(不是对数据的似然性进行优化),而是来自于判别模型D的一个反传梯度
。
GAN可以和CNN、RNN结合在一起
。任何一个可微分的函数,都可以用来参数化GAN的生成模型和判别模型。那么,在实际中,我们就可以使用深度卷积网络,来参数化生成模型。另外,GAN和RNN结合在一起,用来处理和描述一些连续的序列数据,可以学习到序列数据的分布,同时也可以产生序列数据应用,包括对音乐数据或者是一些自然语言数据的建模和生成。

但GAN的缺点也同样明显。
第一个是GAN的
可解释性非常差
,因为我们最后所学到的一个数据分布Pg(G),没有显示的表达式。它只是一个黑盒子一样的映射函数:输入是一个随机变量,输出是我们想要的一个数据分布。
其次,在实际应用中
GAN比较难训练
。因为GAN要交替优化两个部件,而这两个部件之间的优化需要很好的同步。例如,在实际中我们常常需要 D 更新 K次, G 才能更新 1 次,如果没有很好地平衡这两个部件的优化,那么G最后就极大可能会坍缩到一个鞍点。
|
GAN的应用实例
作为一个生成模型,GAN最直接的应用,就是用于真实数据分布的建模和生成,包括可以生成一些图像和视频,以及生成一些自然语句和音乐等。其次,因为内部对抗训练的机制,GAN可以解决一些传统的机器学习中所面临的数据不足的问题,因此可以应用在半监督学习、无监督学习、多视角、多任务学习的任务中。还有,就是最近有一些工作已经将进行成功应用在强化学习中,来提高强化学习的学习效率。因此GAN有着非常广泛的应用。
Twitter 公司最近发表了一篇图像超分辨率的论文,就是应用了GAN模型。图像超分辨率的目的,是将一个低分辨率的模糊图像,进行某种变换,得到一个高分辨率的带有丰富细节的清晰图像。

超分辨率问题,实际上是一个病态问题,
因为在图像分辨率降低的过程中,
丢失的高频细节很难恢复
。但是GAN在某种程度上可以学习到高分辨率图像的分布,从而能够生成质量比较好的高分辨率图像。
生成模型要将模糊的低分辨率图像作为输入,并输出一个高分辨率的清晰图像。而判别模型,就要判断所输入的图像究竟是“真实高分辨率图像”还是由低分辨率图像“转化来的高分辨率图像”。而这就
大大简化了图像超分辨率模型的学习过程
。因为传统上做一个图像超分辨率,都要去对一些高频细节进行建模,而这里生成模型训练目的就简化为迷惑判别模型。

为了使得整个GAN能够取得比较好的结果,我们常常要求生成模型和判别模型都要有很强的学习能力,所以在实际应用中,我们常常用一个多层的神经网络来参数化生成模型或者判别模型。

在 Twitter 这篇论文中,他们用一个16个残差块的网络来参数化生成模型。而判别模型使用的是一个VGG网络。这个实验结果也说明了使用GAN模型能够得到更好的结果。与以往基于深度学习模型做图像超分辨率的结果相比的话(比如SRResNet等),我们可以看到GAN的结果图能够提供更丰富的细节。
这也就是GAN做图像生成时的一个显著优点,即能够提供更锐利的数据细节
。

Apple最近刚刚发表了其第一篇AI论文,论文要解决的问题,就是如何使得模拟的数据更加逼真,与真实图像的差异性尽量小。
这篇论文中使用了类似GAN的框架,将模拟器(Simulator)产生的虚拟数据作为输入,通过一个叫做改进器(Refiner)的模型(对应生成模型)来产生改进后的虚拟数据。再同样的,使用一个判别器,来判断所产生的图像是真实的,还是虚拟的 。
Apple对GAN主要做了两个方面的改进。
第一个就是,为了最大程度保留虚拟图像的类别,
引入了额外的一个自正则项(Self-Regularization Term)
,最小化生成图像与合成图像的绝对值误差,从而保留图像的标注信息,如眼睛视线的方向,使得生成图像可以用于训练机器学习模型。
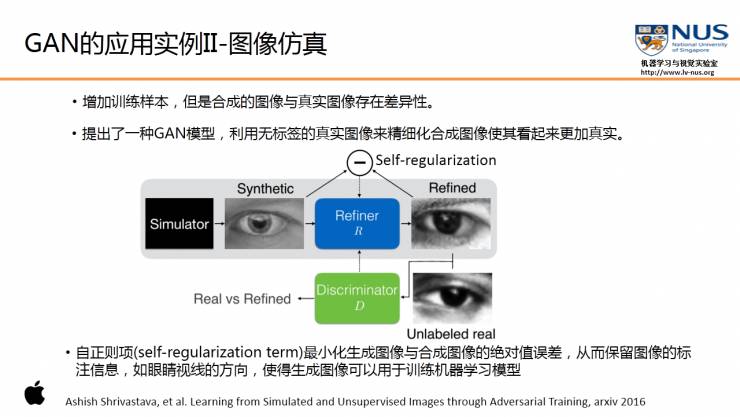
另外一个改进,是
引入了一个局部对抗损失函数(Local adversarial loss)
,而不是像之前的判别器,使用的是一个全局的损失函数。这里不同于朴素GAN将整张图作为一个输入进行真与假的判别,而是将输入的图像分成若干个图像块,对每个图像块进行判别。这样的话可以避免过于强调某些特定的图像特征而导致的尾插。同时实验结果也表明,使用这种局部的对抗损失,确实可以提供一些更锐利的细节,使得生成结果具有更丰富的信息。

那么除了刚才介绍的两个例子,GAN还有其他一些非常有意思的应用。
首先,
图像到图像的翻译
。比如说将语义标注图、灰度图或边缘图作为GAN的输入,那么我们希望它输出能够和输入图一致的真实图像,例如这里的街景图和彩色图。
其次,
文本到图像的翻译
。GAN的输入是一个描述图像内容的一句话,比如“一只有着粉色的胸和冠的小鸟”,那么所生成的图像内容要和这句话所描述的内容相匹配。

GAN可以用在
特定的人脸图像
生成
上,例如戴着墨镜的人脸。还可用在
图像语音分割
上,通过引入对抗训练,得到更锐利的风格结果。GAN可以用于
视频生成
,通过过去的一些帧来预测未来的一些帧,从而捕捉到一些运动的信息。

最近,我们自己的实验室团队在GAN上也有一些应用和发展,其中一个是
将GAN应用在“人脸去遮挡”
。我们引入了一种保持人的身份信息的GAN模型,实验结果证明,这个模型不仅能够检测和去掉在人脸上的遮挡,同时还能保持人的身份信息,从而提高人脸的识别准确率。

我们实验室的另一个GAN应用,是在小物体的检测上,例如在自动驾驶领域对交通标志进行检测。

我们发现,小的交通标志和大的交通标志实际上在特征表示上有着显着的差异。因此,如果我们直接将所学习到的特征表示作为输入,进行检测的话,那么小物体上的检测结果往往都不是特别好。所以,我们
提出了一个“感知GAN模型”(Perceptual GAN)
,应用在小物体特征表示的超分辨率上,而不是对原始图像进行超分辨率,使得小物体的特征表示和大物体的特征角表示尽量接近,这样我们就能够成功检测到小物体。我们将这个感知GAN模型应用在了交通标志检测上,取得了比较好的实验结果。

|
GAN的未来发展方向
-
针对GAN可解释性差进行改进
。包括最近刚提出的InfoGANs。InfoGANs通过最大化隐变量与观测数据的互信息,来改进GAN的解释性。
-
进一步提高GAN的学习能力
。包括引入“多主体的GAN”。在多主体的GAN中,有多个生成器和判别器,它们之间可以进行交流,进行知识的共享,从而提高整体的学习能力。
-
针对GAN优化不稳定性进行改进
。例如使用 F 散度来作为一个优化目标和手段,对GAN进行训练。
-
应用在一些更广泛的领域
。包括迁移学习以及领域自适应学习。还有一个最近比较有意思的应用,是建立了GAN和强化学习之间的联系,将GAN用在了逆强化学习和模拟学习上,从而能够大幅度提高强化学习的学习效率。另外还可以用在数据的压缩上以及应用在除了图像以外其他的数据模式上,比如用于自然语句的生成,还有音乐的生成。
|
总结
-
GAN的优势
。作为一个生成模型,GAN模型避免了一些传统生成模型在实际应用中的一些困难,巧妙地通过对抗学习来近似一些不可解的损失函数。
-
应用方
面
。GAN现在广泛应用图像和视频等数据的生成,还可以用在自然语言和音乐生成上。
-
存在的问题
。一个是GAN的优化过程中存在不稳定性,很容易坍缩到一个鞍点上;其次是GAN的可解释性比较差;再次,需要提高训练过程中的稳定性和GAN模型的延展性,尤其在处理大规模数据的时候。
-
应用前景
。在未来,我们希望看到GAN应用在无监督学习或自监督学习上,提供有效的解决方案。同时GAN还可以建立与强化学习之间的联系,应用在强化学习上。
最后,回到Yann LeCun提出的那个比喻,我们对它进行一点修改。就是如果人工智能是一个蛋糕的话,那么
“蛋糕胚”不仅是指无监督的数据表示学习,还应该包括“无监督推断学习”,而GAN确实很好地连接了这两个重要的人工智能主体
。

另外,除了强化学习这颗“樱桃”之外,实际上还有很多其他的“樱桃”。比如说鲁棒学习、自监督学习和在线学习等。所以实际上还有许多问题需要大家一起来解决。
最后我要感谢一下实验室的博士后和访问学生对我们GAN工作的贡献,他们在新年的时候还要熬夜帮我准备这次PPT的一些素材。另外,谢谢大家来听这次分享课。






