来源:科学杂志(kexuemag),作者:徐雷,致远讲席教授,认知机器和计算健康研究中心主任,上海交通大学电子信息与电气工程学院,本文获授权转载
从1956年夏在达特茅斯(Dartmouth)学院召开的研讨会算起,人工智能研究已过一甲子,潮起潮落,如今迎来了第三波浪潮。2017年是中国智能研究的重要年份,“人工智能 2.0”和“脑科学计划”两个国家长期计划即将启动,众多高科技企业竞相参与。
长期以来,智能一直用来表示大脑思维的能力。智能究竟是什么?这个问题至今没有公认的答案,不断有人试图从本质上给出一个简短而精确的定义。其实,早在60年前,就有一个接受度较高的提法——智能的本质是大脑的信息处理或计算能力。这比思维能力具体了一些,有信息理论和人造的计算机做参照,但仍太笼统,除了思辨没有多大用途。追求智能的简要精确定义可能是个迷思,因为大脑是一个非常复杂的系统,智能是该系统多种属性、功能和外在表现的综合。
对大脑智能的了解,可以通过对大脑智能外在描述的观察,及对其内在的进一步探索。
大脑智能的外在描述可以从广义和狭义两个角度来讨论。广义上,所有需要经过大脑的信息处理或计算都可以视作智能活动,主要包括心智方面的感知、注意、识别、反应、情绪、推理、理解、觉悟、发现、动机、意图、规划、搜索、评估、决策,以及更为一般的控制和通信活动等。狭义上,常用“智、慧、聪、能”等字描述大脑智能,多指人类大脑独有的、而非人类大脑所不具有的能力。随着时代发展,人们开始发现,过去被认为是 “智、慧、聪、能”的能力,人造计算机以及某些动物的大脑也具备。换言之,这种狭义的智能概念是随着人们认识的扩展而不断发展的。
大脑智能的内在探索至少应该包含信息处理和神经科学两个方面。
信息处理方面,率先探索的是大脑的最基本元件。回顾历史,对这方面存在一系列疑问,比如大脑系统究竟存在几个基本单元?每个单元担任什么样角色?这些基本元件将形成几种不同的基本通路并发挥什么作用?这些通路以怎样的结构形成不同功能的模块,并如何构成系统?更进一步,还想了解在这个系统里信息是如何流动的,有几种机制协调管理这些流动实现各种智能活动等。与由电阻、电容、电感、互补金属氧化物半导体(complementary metal oxide semiconductor,CMOS)等基本元件构成的电路系统相类似,脑信息系统也应该不止有一种元件。从1943年麦卡洛克(W. S. McCulloch)和皮茨(W. Pitts)提出的神经元模型,1959年罗森布拉特(F. Rosenblatt)的感知机,1985年美国加州大学圣迭戈分校的并行分布处理(parallel distributel processing, PDP)团队的多层神经网络,到2006年多伦多大学欣顿(G. Hinton)团队展示深度学习用的受限玻尔兹曼机,他们考虑的都是一种元件,数学上用逻辑斯谛(Logistic)线性模型来近似其多输入单输出的关系。另外,从1960年代初维塞尔(T. Wiesel)和休伯尔(D. H. Hubel) 的特征检测理论,到现今深度学习中广为使用的卷积神经网络,采用的是称为S元(simple cell,简单细胞)和C元(complex cell,复杂细胞)的两种基本单元。
神经科学方面,也有许多问题引起众人关注。例如神经元主要由哪些关键性物质构成?哪些物质调制神经元功能(神经科学称其为调质)?哪些物质作为信息流载体(神经科学称其为递质)?近年来,已被发现的递质和调质有近百种,有待鉴定的可能性更多,可分为胆碱类、单胺类、氨基酸和神经肽。随着时间的推移,还会发现更多种这样的物质。
然而智能的内在探索在上述两个方面的发展存在很大的不平衡,投入的力量相差悬殊。尽管在关于神经元的结构和物质组成上,已有不少研究发现,但这些成果对弄清智能行为少有帮助。笔者认为应该将两方面的进展联系起来,并思考哪些生化物质对应哪种基本单元,哪些物质支撑信息流动,哪些物质可能影响神经元的生存和能耗,但并不直接起信息处理作用,找到这些问题的答案或许能加深对智能的理解。
近二三十年脑科学的研究进展与人工智能第三次浪潮关系不大,不过,1960年代的特征检测理论和1980年代的多层神经网络对第三次浪潮颇有影响。
冯·诺依曼结构的计算机诞生后,人们产生了种种期待,觉得计算机像人一样有智能,机器替代人完成各种工作的时代来临了。著名的图灵测试让机器模拟人类智能行为,以此来判别机器是否拥有人工智能。当时的研究兵分两路,一路是人按照特别设计的语言编程,机器通过乔姆斯基(N. Chomsky)形式语法系统和相应的树搜索技术读懂并完成可编程求解的问题或活动;另一路针对那些难以编程的问题,主要是语言理解、机器视觉、知识表示、推理规划等。智能研究的多个分支纷纷出现,并在1950年代掀起第一次研究浪潮。
巴洛(H. B. Barlow)、莱特温(J. Y. Lettvin)、维塞尔和休伯尔关于特征检测器及其理论的研究,开创了计算神经科学。基于麦卡洛克和皮茨神经元模型的罗森布拉特的感知机,既是人工神经网络研究的起始标志,也与统计决策理论、霍夫变换(Hough transform)一起成为模式识别和机器视觉的源头。乔姆斯基形式语法系统影响巨大,不仅是计算机程序编译和符号人工智能的源头,而且还推动心理学派生出计算心理学,令物理符号主义取代了起源于20世纪初的行为主义。
在其后一二十年里,这些分支分别自立门户。符号人工智能的发展规模最大,形成了知识表示、规则推理、启发搜索的基本体系。但是符号人工智能的知识和规则的获取需要通过人工,然后才是机器进行演绎,整个流程其实是编程求解的“同宗兄弟”,因而有类似的局限。这一期间,人工神经网络的研究则受到符号人工智能中某些大师的错误排挤,发展停滞。
经历了那一段艰苦时期,曙光终于出现。1980年代中期,计算心理学逐步发展为认知科学,在加州大学圣迭戈分校PDP团队的倡导下,建立在人工神经网络模拟大脑神经元及其联结基础上的联结主义活跃起来,其部分主要旗手转而扛起人工神经网络的旗帜,推动神经网络学习在其后十余年间掀起高潮。同时,停滞了20余年的行为主义在萨顿(R. Sutton)等人的推动下,以强化学习(reinforcement learning)为主题,再现活力。另外,模式识别和机器视觉研究也开始沿着多条线发展。一时间,人工智能研究蓬勃发展,春色满园。这一时期可以认为是智能研究的第二次浪潮。我国相应地进行了各种跟踪研究,迎来了第一次浪潮 [1]。
1990年代中末期开始,人工神经网络的一些主要研究力量转向推动人工智能发展。先以贝叶斯网络推理为主流,后又将神经网络学习研究进一步推广为研究各种机器学习方法,智能研究的第三波浪潮掀起。此次浪潮带动模式识别与机器视觉方向的研究再度趋热。而集成电路、无线通信、互联网、信息采集、传感控制、物联网等多种技术的积累,尤其海量数据和超级计算能力的提升,为辛顿团队在2006年重新审视深度神经网络创造了条件,他们很快在认识上有了新突破,由此推动人工神经网络急速升温,促进了神经科学、认知科学的繁荣和相互融入。经过60年,智能研究相关各分支再度大整合。AlphaGo系统进一步成功整合深度学习和强化学习,并让人们再次关注到一甲子以前曾风靡了一甲子的行为主义。
第三次浪潮与前两次浪潮最为不同的是IBM、谷歌等科技巨头的加入,它们以雄厚资源和大兵团作战能力,雄踞龙头,通过推出沃森(Watson)系统、AlphaGo系统等智能产品,持续推高第三次浪潮。这意味着针对超级复杂大系统的智能研究已从学者们个人的沙盘推演转变为大规模团体作战,这个转变是必然的。
对于我国人工智能的发展境遇,笔者有三点管见 [2]:首先,研究的龙头应是大科技公司或综合体系,而非高校或事业单位的研究院所。龙头企业的兴起才是评判国家人工智能发展水平的重要因素。第二,国家规划有助于扶持这类综合体系的产生,但关键是领导整合能力。第三,事业型研究单位和小的高科技公司应专注薄弱及重要环节的新方法、新技术,这样会有效加快我国人工智能前进的步伐。
智能研究各分支的这番大整合,产生了不少新术语,并出现了若干可能会引起误解的新提法。为避免混淆,需要对它们进行系统梳理。
类脑计算(brain-inspired computing)最早在美国流行,是指受大脑神经元结构和机制启发而研制的计算芯片,以及由这种计算芯片组建的计算系统。类脑计算主要包括神经形态芯片和脉冲神经元芯片,它的功耗远低于CMOS芯片。2017年年初,《自然材料》(Nature Materials)报道了一种更接近大脑神经元机制的新型忆阻器芯片,或许由它组建的计算系统会更接近人类大脑智能。
类脑智能 (brain-like intelligence)在20多年前就经常出现在亚太神经网络学会的会议上。日本理化学研究所(RIKEN)前脑科学研究院院长甘利俊一(S. Amari)教授在建议用信息几何理论对脑的学习建模时,也常使用这个词。其实,它与大脑内在没有直接关系,只是人工智能的同义词。它还有另外一层意思,指模拟智能的系统至少有一些与大脑内在类似的东西(brain-like system)[3]。现今该词的用法多为后者,卷积神经网络和深度学习嵌入了维塞尔和休伯尔特征检测结构,也算一例。由此可见,可以认为类脑计算是类脑智能研究的一部分。但是,从神经科学得到的关于大脑内在的已有知识甚少,制约了类脑智能研究的发展,算得上是类脑智能的事例至今不多。
增强智能(augmented intelligence)又称脑机智能或脑机合一,源于拓展大脑对外信息输出的通道(语言、动作、表情、文字等)。先由机器如可穿戴设备直接获取大脑的信息(目前主要是脑电信号),接着对其进行不同程度的处理。增强智能可以用于控制各种伺服机构,如假肢、轮椅、各种装置、人造器官等,也可以实现机器的高水平智能活动,形成人脑—机器接续合一,甚至完成机器的信息输出,通过人的自然感官或人工通道(如附加电极)反馈,从而影响大脑的智能。增强智能不同于模拟大脑能力的人工智能,也非耸动视听的“对抗人工智能”,而是指“大脑智能+新的信息通道+人工智能”以增强或延拓大脑的智能。
群体智能 (crowd intelligence)又称群智计算,是指大量个体通过交流合作实现超越个体的智能。这个名词源于30多年前对蚁群、蜂群等行为的研究,该研究主要是观察没有中心控制的分布式初级个体如何发生自组织。如今,群体智能关注的是高级智能个体,严格地说,大脑智能就是人类群体智能在每一个体大脑上的不同体现,现实中很难看到一个孤立大脑的智能。人类智能实质就是以大量个体大脑通过通信交流和储存积累两个基本要素,再由第三个要素——某些核心人物或团体进一步归纳提炼,逐步形成的;反之,它又会影响、教育、提升每一个体的大脑智能。当今超级互联网和强大的服务器大大提升了前两个要素,而第三个要素也有人工智能、类脑智能和增强智能为帮手,人类智能的后续发展非常令人期待。
认知计算(cognitive computing)这是IBM倡导的名词,即其推出的超级计算机沃森的主题词。它是近几年IBM力推的发展方向。从概念上看,认知活动涵盖感知、识别、推理、评估、决策、理解等,构成了大脑智能的主要部分。用机器实现这一部分的计算,当然属于图灵测试认可的人工智能。IBM强调,与通常计算机的数据分析所面对的人工编程和人工制表的结构化数据不同,认知计算可以处理非结构化的大数据。其实,非结构化的数据处理也是人工智能的原有目标之一,只不过之前符号人工智能实现不了,而今可以用大数据驱动的深度学习来实现。从认知科学角度来看,认知计算是联结主义和符号主义联姻的成功案例,可大致视其为人工智能1.5。
AlphaGo是谷歌 DeepMind研制的人工智能围棋系统。2016年3月,它4∶1战胜李世石;2016年末和2017年初,它又在中国棋类网站与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩。该系统也是以代表联结主义的深度学习作为驱动引擎。它利用大数据通过深度网络学习得出对当前棋局好坏的经验评估和下一步各种落子的经验概率分布;还利用大数据通过浅层网络学习得出快速走子策略,驱动蒙特卡洛树搜索进行前瞻性侦察,获得关于获胜机会的前瞻评估。此外,代表行为主义的Q学习进一步综合落子概率、经验评估和前瞻评估后,系统才真正落子。不仅如此,它还要与过去的自己对弈,反复内省之前所学,巩固赢面。从认知科学角度来看,AlphaGo是成功整合联结主义、行为主义、符号主义,甚至还有内省主义的经典案例,可以将其看作人工智能1.8。
“人工智能2.0”是中国“科技创新2030重大项目”的几个专项之一,由潘云鹤院士牵头提出,旨在发展新一代人工智能,最近已获国务院批准,将在2017年下半年进入实施。该计划提及的新方法和新技术,囊括了大数据智能、人机混合增强智能和群体智能等,敦促分类型处理多媒体数据(如视觉、听觉、文字等)迈向认知、学习和推理的跨媒体智能,将研究的理念从机器人转向更加广阔的智能自主系统。“人工智能2.0”在应用落地方面,致力于满足智能城市、智能经济、智能制造、智能医疗、智能家居、智能驾驶等从宏观到微观的智能化新需求。它的实施有望使我国的科研与产业从“跟跑”,转变成“并跑”甚至“领跑”。
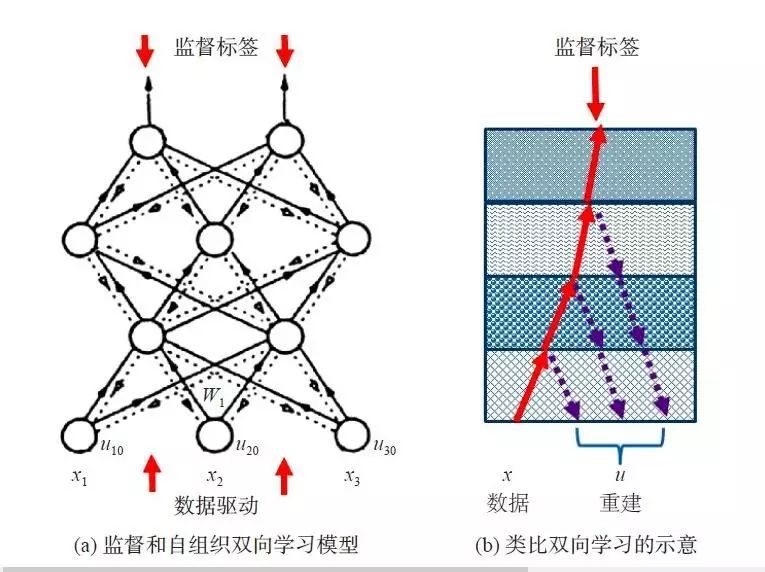
多层最小平方自组织学习 图(a)是一个监督和自组织双向学习的模型,类似现今深度神经网络学习的典型方法[4,5]。为了便于理解,将图(a)类比为图(b)。图(b)中,数据x类似光线,从输入层传入,在到达第一个层间界面时,一部分穿过进入下一层,另一部分反射回来,视为x的一个重建。可以通过改变媒介性质,使得重建误差最小。对于穿入第二层的信息,情况相似,不过要注意的是,第二层的反射也可以穿过第一层并与第一层的反射叠加。逐层类似,最后直到监督层。需要指出的是,这个类比是粗糙的,实际情况更为复杂。
深度学习是人工智能第三次浪潮的引擎,它成功的原因通常被归结于三点:大数据、超级计算能力和新的数学方法。前两个原因毋庸置疑,而对第三点原因的认识却时有争议。下面就两个常见的观点作一些探讨。
一种观点是,以前的神经网络学习只考虑三层(即只有一个隐单元层),而现在的深度学习考虑很多层。这种看法有悖于历史事实。鲁梅尔哈特(D. Rumelhart)和欣顿等人在1980年代中期提出的误差反向传播学习针对的就是多层网络,当时还有许多研究考虑的也是多层网络。西本科(G. Cybenko)、霍尼克(K. Hornik)等人从1980年代末应用函数逼近表示理论,指出三层网络有所谓数学上的通用近似能力,即只要隐单元数目足够大,用它近似任何函数,都可把误差控制得足够小这类研究或许影响了一部分人只关注三层网络,但仍有很多人在研究多层网络。
另一种观点是,以前的神经网络学习依靠的是误差反向传播,其缺陷是局部极值和误差积累等因素导致反传的深度有限。而深度学习反向行之,用无监督学习方法,从数据输入层开始,先学第一层参数,并将数据传到第二层,这样第二层的情形就等同于第一层,如法炮制……最后直至监督层。然后根据监督标签得到的误差进行反向传播学习,精调每一层的参数。他们认为这是突破过去的一个新数学方法。
其实这种观点也与历史不符。笔者在1990年代初提出的多层自组织学习 [4,5],就包含数据从输入层传入的逐层自组织学习与从监督层进入的逐层反向传播学习。在逐层反向传播学习中,监督标签由上而下从监督层进入,通过改变各层使得误差不断减小。这个反向的监督学习,可以与由下而上的自组织学习先后进行,也可同时实施线性叠加。这个双向学习,还可用来解释注意和想象机制 [4,5]。遗憾的是,当时由于没有如今出色的计算能力和大数据支撑,计算实验只在单层上进行,无法继续深入。
深度卷积神经网络是另一个主要的深度学习模型,也诞生于人工智能第二次浪潮中,福岛邦彦(K. Fukushima)和杨立昆(Y. LeCun)早期都做出了杰出贡献。
笔者认为,尽管深度学习过去已有“深度”,也考虑过监督和非监督的协同双向学习,但没有大数据和超级计算支撑实际的计算,进展非常不尽如人意。2006年,欣顿团队采用“大+超+深”(大数据+超级计算+深度)并辅以自组织的双向学习(即监督学习+非监督预训练),产生了认识上的突破,让人们看清原来“路在脚下”。经过十余年的发展,深度网络学习终于攀上了前所未有的高峰。
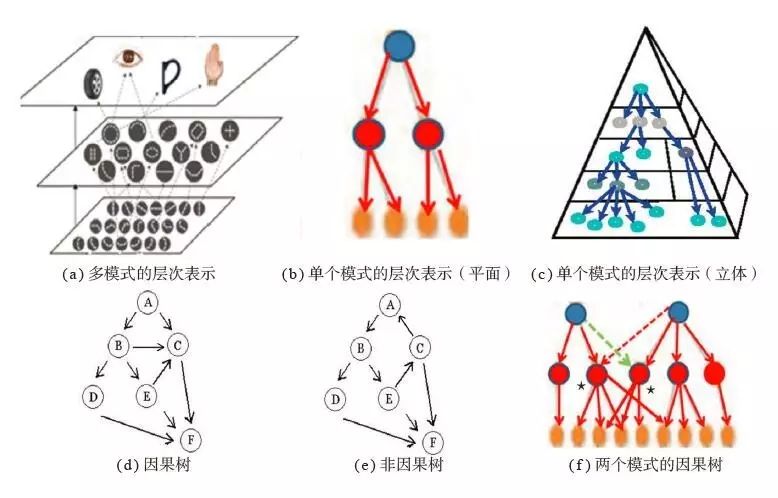
从模式层次表示理解深度学习中深度与监督+自组织双向学习 现实中已被人类所认知的事物一般都具有如图(a)所示的层次表示,对应一个如图(b)所示的树,也可以如图(c)所示的立体树。同一层的节点间,如图(d)所示,可以有横向的有向连接(B→C),甚至有逆向连接(E→C),但不允许有如图(e)所示的任何闭环(A→B→E→C→A)存在。同一层节点间有横向连接时,可通过将有横向连接的层分成多层,令该树变为图(b)或图(c)所示的形式。对应两个模式概念的树,可能会共享一些子树结构。这时,任一个模式的根节点为真,都会驱动那些标注*号的节点及其后代为真。
在了解了深度学习成功的主要原因后,再进一步追问两个问题,深度学习为什么要深?监督学习+自组织双向学习真的可以提升学习效果吗?
简单来说,监督误差会随着学习逐渐减小,这个过程常遇到一片局部极小值众多的区域,一旦进入,就会很长时间走不出来。倘若深度加大到一定程度,就算进入此区域也不要紧,因为其中任一个局部极小点的误差已与全局最小误差相差不大。而辅以非监督预学习,可减少进入该区域的概率。如果采用随机梯度下降算法,效果会更好些。这个说法似乎解释了为什么要深,但又带来一个新问题——太深是否会引起过拟合问题?
对此,一种解释是,现在的深度学习采用海量的数据,不存在过拟合问题,关键是尽量增加层数以减少欠拟合误差。而以前的机器学习是小样本集学习,关键是控制模型复杂度以避免过拟合。但是,这个解释需要证据来说明就算没有其他辅助措施避免过拟合,“大+超+深”依然行得通。理论上,还需要分析估计深度神经网络的等效复杂度,由它来判断数据的规模是否大到了使欠拟合转变为主要矛盾。
笔者认为,还可以从模式层次表示的角度来回答本节开头的两个问题。维塞尔和休伯尔的特征检测理论认为,每个图像模式都由不同层次的子结构和特征构成。不仅是图像,现实中那些已被人类所认知的事物一般都具有这样有效的层次表示。基于这种层次表示,笔者对深度学习也曾给出过两个解释。
其一, 这类可层次化的模式或概念可对应一个因果树(causal tree) [6,7]。只要知道因果树的根节点为真(即已知某种模式),便可推断必有子节点为真(即必有对应的子结构出现)。按此规则可以类推出所有节点。例如,根节点确定是眼睛,往下一层,应该有一个圆形和一个椭圆形子结构;更下一层,就应有若干弧形特征片段。这种性质对应于马尔科夫(Markov)条件独立性,即若一个节点的值已知,其下各支子树之间就会变成独立。设想一个真实反映某个模式的树,已知标签告知根节点为真,那么真值就可以一路下传,到达位于不同层次的那些子结构或特征片段。下传得越深,底层上那些节点就越接近独立或分组独立。仅靠用监督误差的反向传播学习,难以满足这种约束性很强的结构。
当年笔者在研究多层自组织学习时发现,每个神经元引入一个S型的非线性函数后,这种从数据层开始的逐层向上的自组织学习会使得同层的神经元变得尽量独立或分组独
立 [4,5,8]。这个特征与监督误差的反向传播学习结合,有利于发现和学习树状层次结构。换言之,监督学习+自组织双向学习可以显著提高学习效果,而且层次越多,监督学习+自组织双向学习越有必要。分析发现,欣顿团队所用的受限玻尔兹曼机的学习,情况类似。
不难发现,树状层次越近底层的特征片段越小,这有利于自组织学习逐层向上变成独立或分组独立。不仅如此,对应两个或多个模式概念的因果树可能会在不同层次上共享一些子结构或特征片段。这不仅将显著裁剪掉多余的结构复杂度,而且两树的共同节点被驱动为真的机会增加了,有利于它们下方底层上那些节点变成独立或分组独立。而神经网络的层次越多就越有利于多个模式的因果树在不同层次上实现共享。
其二,基于上述模式层次表示,也可从分治—整合的角度来理解深度学习。即从监督层向下的过程,将模式的复杂结构分而治之地逐层分解为更简单的子结构,直到底层的基本单元;而从数据层向上的过程,驱动与其相匹配的特征逐层向上整合,实现对复杂模式的认知。按照丘奇—图灵学说(Church-Turing Thesis),深度神经网络的计算能力应该与图灵可计算等价 [9]。
观察由简单基元递归产生的层次模式,会注意到,递归产生一个特定模式至少需要一定层数。若用少于这个层数的神经网络来表示这个模式,则无法准确描述该模式结构,只能是达到某种程度的近似。只要三层网络的隐单元数目足够大,就可以近似任何函数输入—输出之间的点对关系,把误差控制得足够小。但是,这样做不一定能保持其函数结构,要保持结构,就必须有足够的深度。那么,是否越深越好呢?可以把一层分为几个更细的层,也可以把多叉树变成深度增加的二叉树,这些做法都不会降低准确描述层次结构的可能性,从这点看,似乎越深越好。不过,深度越深,对剪枝能力的要求越高,不然冗余的层间连线将造成许多虚假分支,造成过拟合的表述错误。实际上,稀疏学习和嵌入特殊结构的各种现有努力,针对的就是过拟合问题,这些似乎并不支持关于 “大数据深度学习没有过拟合问题,而只是欠拟合问题” 的说法。
(本文工作获上海交通大学致远讲席教授启动基金资助)

|
一网打尽系列文章,请回复以下关键词查看:
|
|
创新发展
:
习近平 | 创新中国 | 创新创业 | 科技体制改革 | 科技创新政策 | 协同创新 | 成果转化 | 新科技革命 | 基础研究 | 产学研 | 供给侧
|
|
热点专题
:
军民融合 | 民参军 | 工业4.0 | 商业航天 | 智库 | 国家重点研发计划 | 基金 | 装备采办 | 博士 | 摩尔定律 | 诺贝尔奖 | 国家实验室 | 国防工业 | 十三五 | 创新教育 | 军工百强 | 试验鉴定 | 影响因子 | 双一流 | 净评估
|
|
预见未来
:
预见2016 |
预见2020 |
预见2025 |
预见2030 |
预见2035 |
预见2045 |
预见2050 |
|
|
前沿科技
:
颠覆性技术 | 生物 | 仿生 | 脑科学 | 精准医学 | 基因 | 基因编辑 | 虚拟现实 | 增强现实 | 纳米 | 人工智能 | 机器人 | 3D打印 | 4D打印 | 太赫兹 | 云计算 | 物联网 | 互联网+ | 大数据 | 石墨烯 | 能源 | 电池 | 量子 | 超材料 | 超级计算机 | 卫星 | 北斗 | 智能制造 | 不依赖GPS导航 | 通信 | MIT技术评论 | 航空发动机 | 可穿戴 | 氮化镓 | 隐身 | 半导体 | 脑机接口
|
|
先进武器
:
中国武器 | 无人机 | 轰炸机 | 预警机 | 运输机 | 战斗机 | 六代机 | 网络武器 | 激光武器 | 电磁炮 | 高超声速武器 | 反无人机 | 防空反导 | 潜航器 |
|
|
未来战争
:
未来战争 | 抵消战略 | 水下战 | 网络空间战 | 分布式杀伤 | 无人机蜂群
| 太空站 |反卫星
|
|
领先国家
:
俄罗斯 | 英国 | 日本 | 以色列 | 印度
|
|
前沿机构
:
战略能力办公室 | DARPA | Gartner | 硅谷 | 谷歌 | 华为 | 俄先期研究基金会 | 军工百强
|
|
前沿人物
:
钱学森 | 马斯克 | 凯文凯利 | 任正非 | 马云 | 奥巴马 | 特朗普
|
|
专家专
栏
:
黄志澄 | 许得君 | 施一公 | 王喜文 | 贺飞 | 李萍 | 刘锋 | 王煜全 | 易本胜 | 李德毅 | 游光荣 | 刘亚威 | 赵文银 | 廖孟豪 | 谭铁牛 | 于川信 |
邬贺
铨 |
|
|
全文收录
:
2016文章全收录 | 2015文章全收录 | 2014文章全收录
|
|
其他主题系列陆续整理中,敬请期待……
|




“远望智库”聚焦前沿科技领域,着眼科技未来发展,围绕军民融合、科技创新、管理创新、科技安全、知识产权等主题,开展情报挖掘、发展战略研究、规划论证、评估评价、项目筛选,以及成果转化等工作,为管理决策、产业规划、企业发展、机构投资提供情报、咨询、培训等服务,为推动国家创新驱动发展和军民融合深度发展提供智力支撑。





