阅读本文前,建议先去阅读从动态规划到配对序列联配(一)
编辑距离
上一个例子的斐波那契数列过于简单,以至于难以体现出使用DP编程的具体步骤。这次我们以一个具体的例子来讲解DP算法解决问题三个步骤,即
-
定义子问题:通过数学符号描述子问题的状态
-
定义状态数组:记录计算过程中得到中间结果,方便后续调用
-
定义动态转移方程:如何从前一个问题推导出当前问题
大部分搜索引擎都有一个功能,能够对你的输入尝试进行纠错,例如我故意把ggplot2输入成ggpolt2,搜索很智能的将这个错误输入替换成了“它认为正确”的输入。
评估两个字符串的相似度有两个常用方法,最长公共子串(Longest common substring length)和莱温斯坦距离(Levenshtein distance). 最长公共子串允许插入和删除,描述的是两个字符串相同的子串长度,也就是相似程度。莱温斯坦距离允许插入,删除和替换,描述一个字符串转变另一个字符串所需要的操作次数,也就是相异程度。
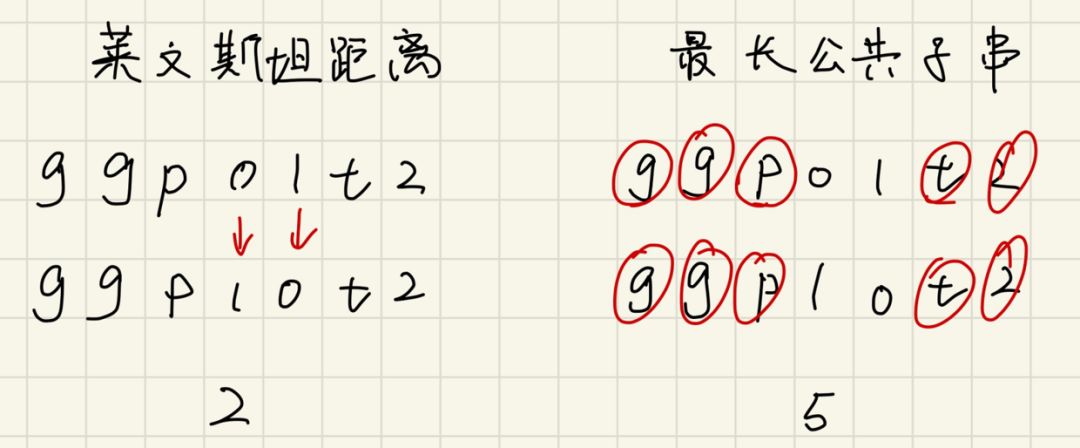
后续只演示如何使用DP计算两个字符串的莱温斯坦距离。
我们需要先定义子问题,也就是把复杂的问题拆解成容易解决的简单问题,并能用数学符号进行描述其状态。这里就有一个问题,我们需要使用几个数学符号?我们可以通过分析问题中
自变量
和
因变量
来确定数学符号的数量。在本问题中,自变量就是两个字符串的长度,而因变量就是随着长度(自变量)改变而发生改变的编辑次数。于是我们用f(i,j)表示字符串1(后面简称S1) 前i 个字符和字符串2(后面简称S2) 前j个字符的编辑次数。
我们可以发现,在定义子问题的状态过程时,涉及到
两个变量
,因此我们用一个二维数组表示不同组合的状态,定义为DP[i][j]
接着我们来思考当前状态和之前的状态的关联。根据可能的操作(插入,删除和替换),当前的子问题可以由三种情况中的一种转移过来(后续举例基于当前状态S1="gg", S2="gg" )
-
DP[i-1][j] , 也就是"g"和"gg", 我们可以通过在S1的"g"插入一个字符,得到S2的"gg",操作次数加1
-
DP[i][j-1], 也就是"gg"和"g", 我们可以通过在S2的"g"插入一个字符,得到S1的"gg", 操作次数加1
-
DP[i-1][j-1], 也就是"g","g", 两个字符串相同,操作加0。如果是不相同,那就是替换,操作次数加1
当前选择策略,取决于每个子问题状态的取值,我们从中选取最小的编辑次数作为当前的操作。
我们可以手工的方式根据状态转移方程填充我们的状态数组,如下所示。

知道思路之后,就可以写代码了。以
C
++
为例
#include
#include
#include
#include
using namespace std;
int dist(string s1, string s2){
int m = s1.length();
int n = s2.length();
//初始化状态
int dp[m+1][n+1];
dp[0][0] = 0;
for (int i = 0; i < m+1; i++) {
dp[i][0] = i;
}
for (int i = 0;
i < n+1; i++) {
dp[0][i] = i;
}
//递归状态表
for (int i = 1; i < m + 1; i++){
for (int j = 1; j < n + 1; j++){
if (s1[i-1] == s2[j-1]){
dp[i][j] = dp[i-
1][j-1];
} else{
vector state{dp[i-1][j], dp[i][j-1], dp[i-1][j-1]};
dp[i][j] = *min_element(state.begin(), state.end()) + 1;
}
//printf("%d-%d: %d\n",i, j, dp[i][j]);
}
}
//输出结果
return dp
[m][n];
}
int main(int argc, char const *argv[])
{
printf("dist is: %d\n", dist("ggpolt2", "ggplot2"));
return 0;
}
代码都是基本语法,很容易转成其他编程语言(R语言要注意数组从1开始,而不是0)。个人觉得有以下几个注意点
-
数组大小为 (m+1) x (n+1) 也就是原来字符串的长度加上空字符串。
-
对第一行和第一列进行初始化。因为后续会从i=1开始递推
-
对于第i列,第j列,对应的字符是S1[i-1]和S2[j-1]。例如DP[1][1], 记录的是第一个字符串的匹配情况,由于
C
/
C
++
以0作为第一个位置,因此比较的是S1[0]和S2[0]
-
c
++
算法的
min_element
支持求多个元素中的最小值,只不过它的要求输入是容器,因此需要先构建一个容器。此外他返回的是一个指针,因此具体的值需要利用
*
求值
但你学习了编辑距离后,是不是感觉这和我们的序列联配有点相似,都是通过一系列操作的将一个序列转成另一个序列。我可以列举下两者的联系
-
字符串限定为核苷酸或者氨基酸
-
如果两个字符相同,序列联配语境中为匹配(match)
-
如果两个字符串不相同,序列联配中为错配(mismatch)
-
将一个字符串替换成一个字符,序列联配语境中为,替换(substitute)
-
删除一个字符或者加入一个字符,序列联配语境中为插入缺失(InDel)
-
一个字符串变为另一个字符串的编辑次数,序列联配语境中为得分(score)
为了评估两个序列的相似度,我们可以评估两个序列联配后的得分大小,不同的操作有不同的分,也就是得分矩阵(score matrix)。
另外为了输出最终的联配后续列,我们需要从最优状态不断溯源(trace back),从而得到联配结果。
小结一下,本文介绍了使用DP求解编辑距离问题的步骤,是后续生物序列联配的铺垫,





