我本来对实习僧网站是没什么好感的,因为之前自己在实习僧上投的实习简历几乎全部都石沉大海了(一个文科生偏要去投数据分析岗不碰壁才怪~_~)!
然鹅看到最近知乎爬虫圈儿里的两大趋势:爬美图;爬招聘网站。
后来大致观察了下,几乎各类大型招聘文章都被别人爬过了,自己再去写免不了模仿之嫌,而且大神们都是用Python去爬的(Python我刚学会装包和导数据),自己也学不来。
现在只能选一个还没怎么被盯上的招聘网站,没错就它了——实习僧。
http://www.shixiseng.com/
说老实话,实习僧的网站做的还是不错的,看着结构挺简单,可是我用比较常用的Rvest和RCurl都失败了(主要自己技术太渣了,抓包又抓不好)。最后只能勉强用RSelenium爬完了全部所需内容。(用代码驱动浏览器的好处就是不用怎么考虑时延和伪装包头了,但是要遍历成百上千页网址真的很耗时,爬完这个数据用了大约40多分钟)。
以下是爬虫部分:
library(rvest)
library(stringr)
library(plyr)
library(dplyr)
library(Rwebdriver)
library(dplyr)
library(Rwordseg)
library(wordcloud2)
library(treemap)
library(showtext)
library(Cairo)
library(ggplot2)
library(scales)
library(grid)
library(RColorBrewer)
library(ggimage)
library(geojsonio)
本文主要用的
Rwebdriver包来驱动Chrome浏览器
,
使用该包需要提前配置好桌面环境:
在cmd或者powershell中启动Selenium服务器:
cd "D:/Rwebdriver-master"
java -jar selenium-server-standalone-3.3.1.jar
在Rsudio中新建进程:
start_session(root="http://localhost:4444/wd/hub/",browser ="chrome")
遍历实习僧的招聘信息网页
options(stringsAsFactors=FALSE,warn=FALSE)
baseurl
pageurl
本文所用到的爬虫代码部分:
homepage=internship=companyweb=company=Position=address=salary=period=duration=NULL
fun
post.url(url=url)
baseinfo
homepage %html_nodes("div.po-name>div.names>a")%>% html_attr("href")
internship%html_nodes("div.po-name>div.names>a")%>%html_text()
companyweb%html_nodes("div.po-name>div.part>a")%>%html_attr("href")
company %html_nodes("div.po-name>div.part>a")%>%
html_text()
Position %html_nodes("div.po-name>div.part")%>%
html_text()
address %html_nodes("div.po-detail>div.addr>span")%>%
html_text()
salary %html_nodes("div.po-detail>div.xz>span:nth-child(2)")%>%
html_text()
period %html_nodes("div.po-detail>div.xz>span:nth-child(5)")%>%
html_text()
duration %html_nodes("div.po-detail>div.xz>span:nth-child(8)")%>%
html_text()
interninfo
}
用一个循环执行上述程序:
final
for (i in pageurl){
final
}
quit_session()
DT::datatable(final)
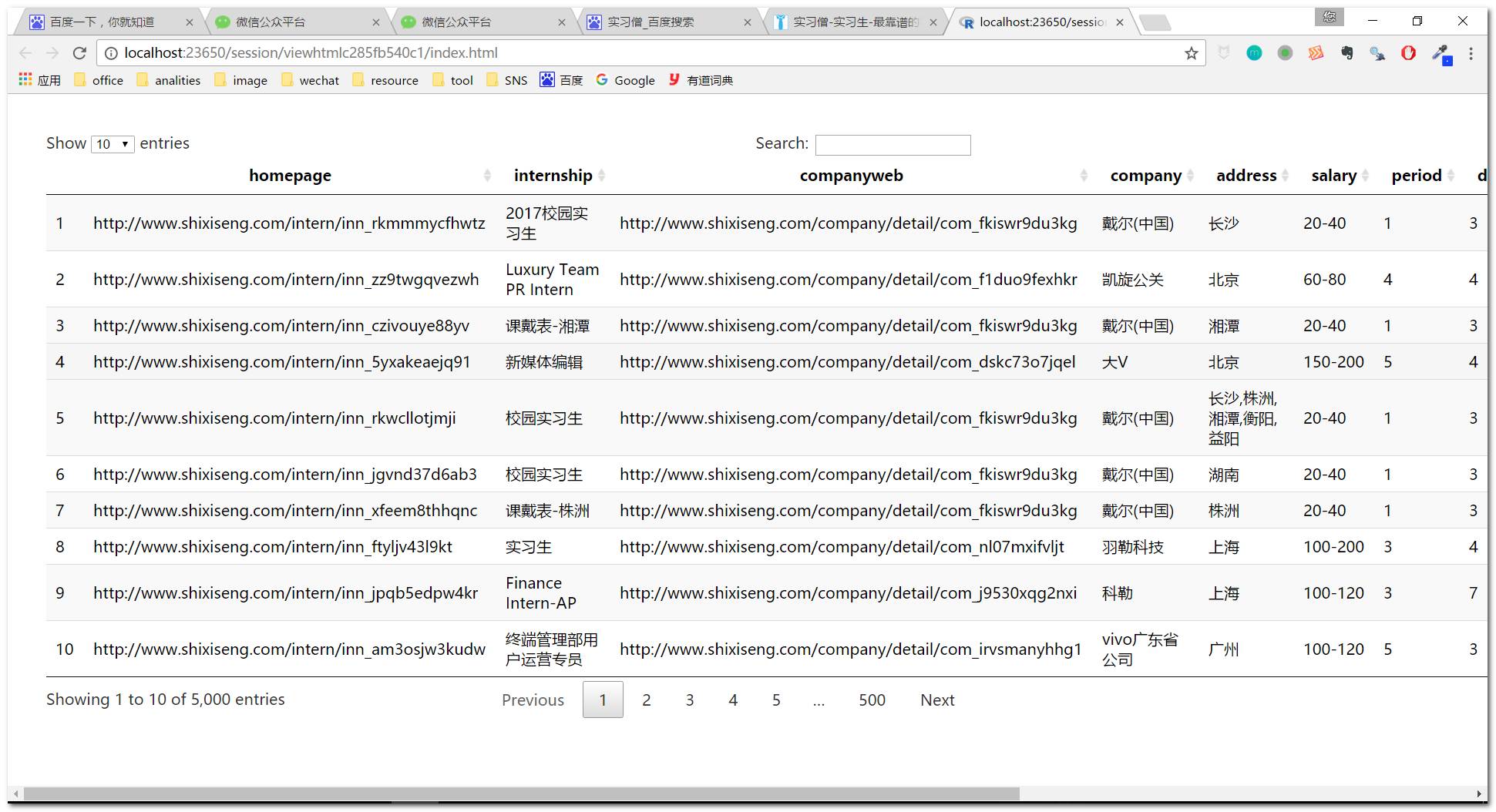
保存本地:
write.table (final,"D:/R/File/shixiseng.csv",sep=",",row.names=FALSE)
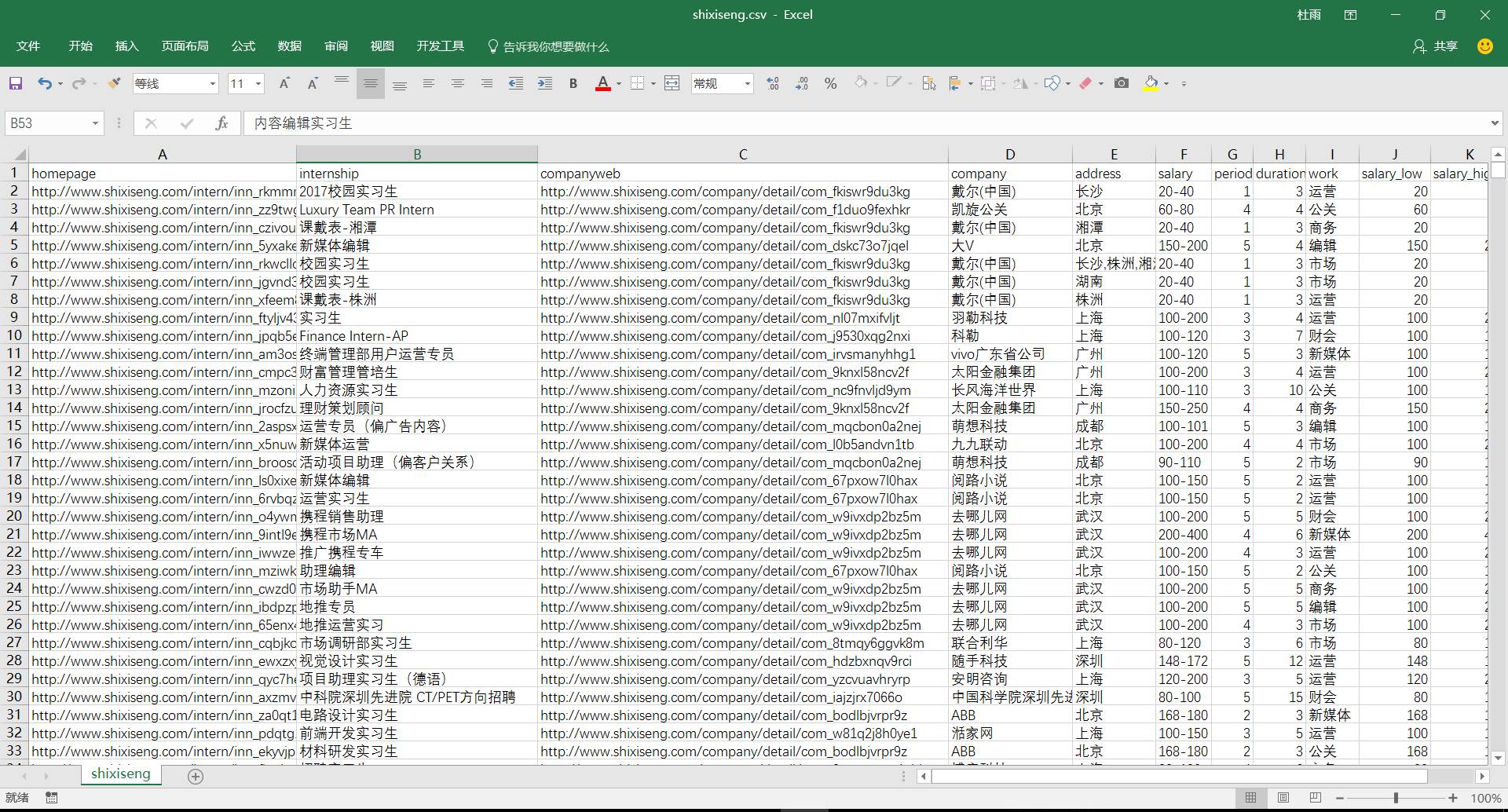
接下来做数据清洗
:
mydata
mydata
#补全实习发布单位的招聘信息主页:
mydata$homepage
#补全实习发布单位的公司信息主页:
mydata$companyweb
mydata$work
#清除salary中的空格和斜杠
mydata$salary
mydata$salary
#拆分实习工资的高低区间
mydata$salary_low
mydata$salary_high
#清除period中的汉字和特殊字符
mydata$period
#清除duration中的汉字和特殊字符
mydata$duration
mydata
mydata
#因为address中所含的地址可能有存在多个,影响我们后续的可视化分析,这里为了方便起见,一律使用第一个地址。
mydata$address_unique
至此,数据清洗工作告一段落,接下来我们要进入分析与可视化阶段
names(mydata)
"homepage"-------公司实习职位简介
"internship"-----公司招聘性质
"companyweb"-----公司主页
"company"--------公司名称
"address"--------所在地
"address_unique"-所在地(唯一值,只取默认第一个地址)
"salary"---------实习工资区间
"salary_low"-----实习工资(最低值)
"salary_high"----实习工资(最高值)
"period"---------到岗天数(每周)
"duration"-------实习周期(按月算)
"work"-----------具体职位
我们最终获取的清洗后数据如上所示。
假如本次项目需求(虚拟)要求我们获取以下几个问题:
1、实习僧的实习招聘主页岗位主要是什么性质的?
2、哪些公司对实习生需求最旺盛?
3、实习岗位具体分布的地域和城市?
4、哪些城市对实习
生
的需要最为强烈?
5、实习工资大致什么水平,与城市和地域是否有关系?
6、实习岗位一般都要求每周到岗多少天?
7、实习周期一般需要多长时间?
8、哪些职位需求最为频繁,职位需要量与城市之间的大致是如何分布的?
带着这些个问题,让我们尽情的畅游在可视化的世界里吧……
1、实习僧的实习招聘主页主要是什么性质的?
length(unique(mydata$internship))
3357
绝望了,一共爬了5000条实习职位信息,做了去重处理,显示仍有3357条,建议实习僧的产品运营团队考虑下要不要标准化一下这个职位性质,内门怎么可以创造这么多独特的职位~_~
对于这个问题,真的难倒我了,因为所爬数据中的职位性质没有统一的预设标准,所以我只能用文本分词的形式来进行提取了,先分词,然后统计高频词,最后按照词频来进行模糊分析啦(可我我对文本挖掘一窍不通啊~_~)
top100%as.data.frame(stringsAsFactors=FALSE)%>% arrange(desc(Freq))%>%.[1:100,]
treemap(top100, index=c("Var1"), vSize="Freq",title='实习僧职位性质分布图',palette='RdBu',
fontsize.title=18,fontsize.labels=12,fontface.labels="plain",fontfamily.title="mono",fontfamily.labels="mono")
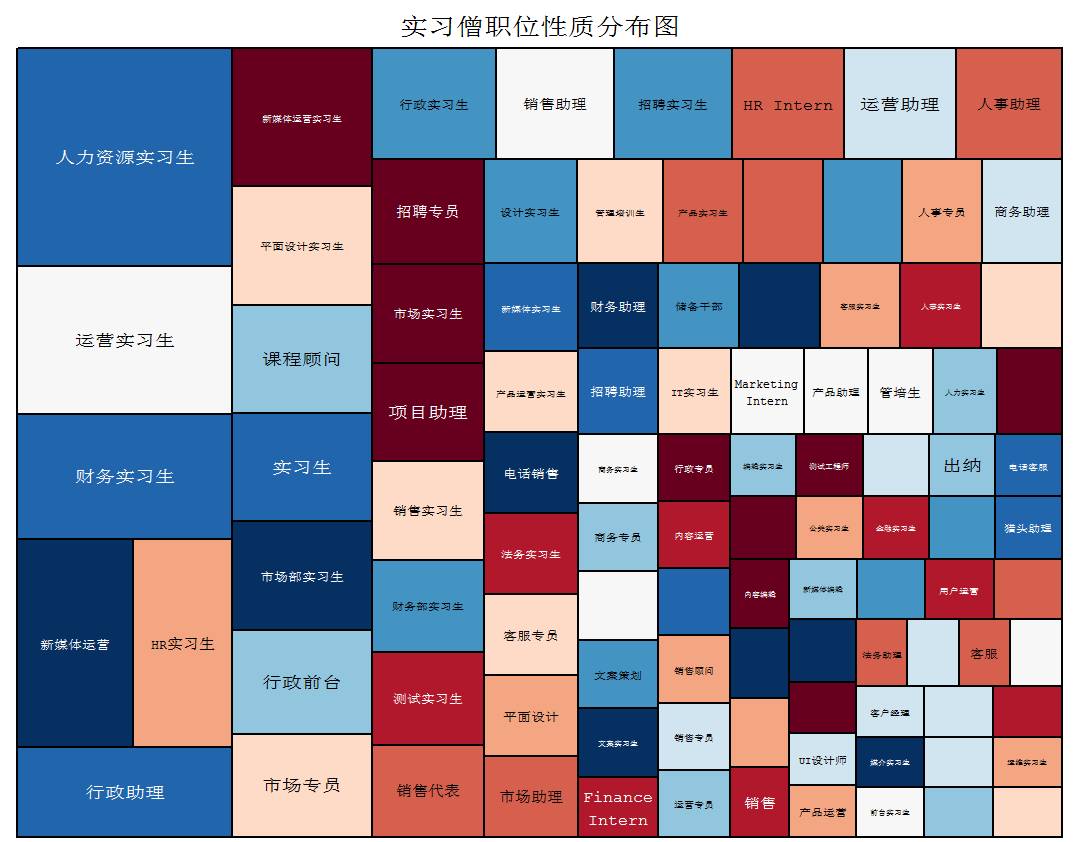
从实习职位分布图上来看,人力资源实习生职位需求最为强烈,其次是运营、财务、新媒体,这些类型的职位多为现代新兴服务业,更为符合大学生这一群体的口味和兴趣。
myrevieww
thewords %unlist()
thewords
thewords1]
reviewdata%as.data.frame(stringsAsFactors = FALSE)%>% arrange(desc(Freq))%>%filter(thewords!="实习生")
wordcloud
但是将职位性质分词整理成关键词后,似乎结果有所不同。

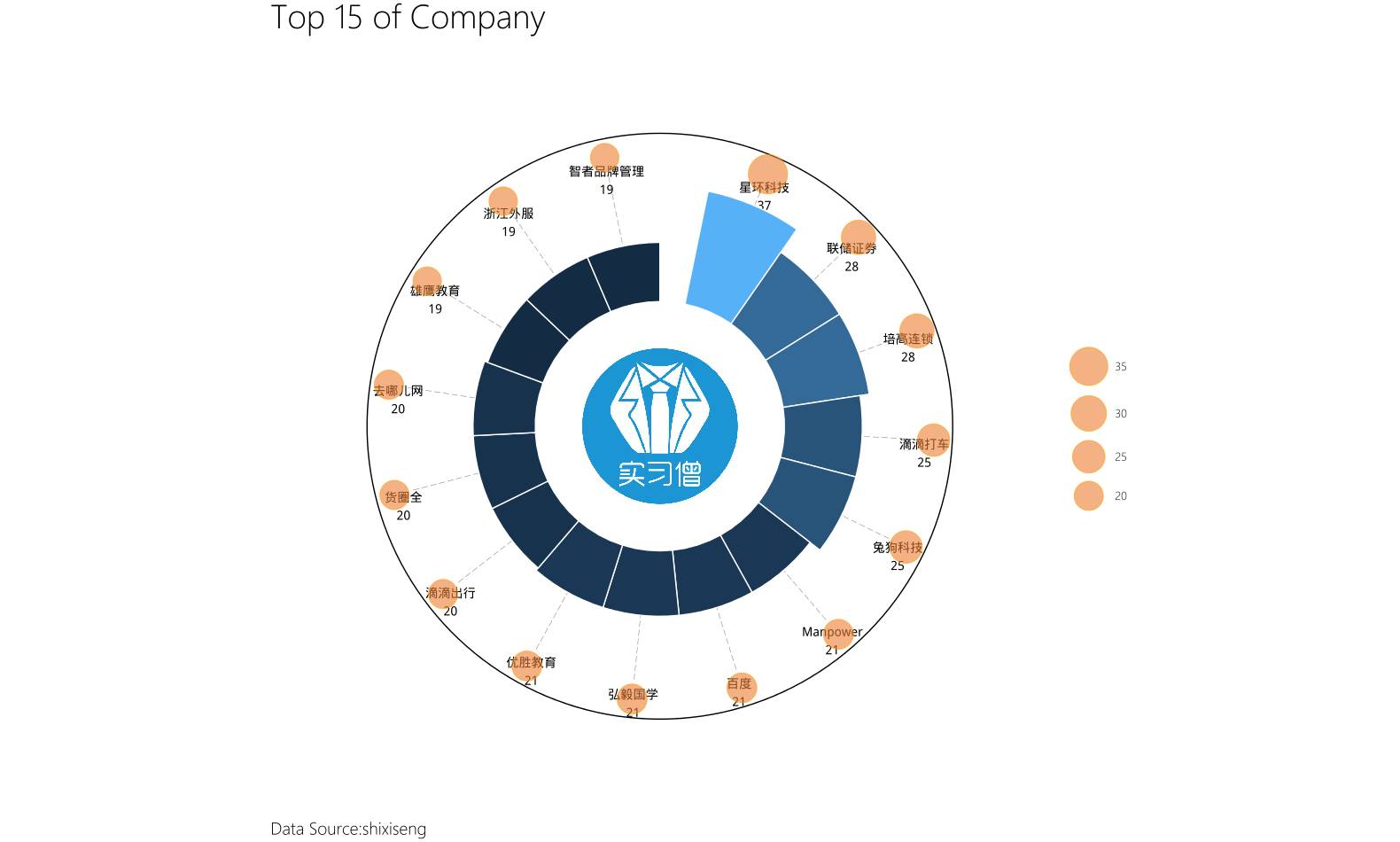
2、哪些公司最缺实习僧?
这里我们来统计所爬职位信息中公司发布职位的频率,发布最多的则作为评价公司对实习生需求的标准。
myjob%as.data.frame(stringsAsFactors=FALSE)%>%arrange(desc(Freq))
#看看前十名都是那些公司:
myjob15
CairoPNG(file="E:/微信公众号/公众号——数据小魔方/2017年5月/20170512/circle-rose.png",width=1580,height=950)
showtext.begin()
ggplot(data=myjob15,aes(x=reorder(Var1,-Freq),y=Freq,fill=Freq))+
geom_linerange(aes(ymin=0,ymax=42),linetype=5,size=.2,colour="#858585")+
geom_image(aes(x=0,y=-40),image="D:/R/Image/image1.jpg", size =.2)+
geom_text(aes(y=45,label=paste0(Var1,"\n",Freq)),vjust=1,size=5)+
geom_bar(stat="identity",width=1,col="white")+
geom_hline(yintercept =54,color="black",size=.5)+
geom_point(aes(y=48,size=Freq),shape=21,fill="#ED7D31",,alpha=0.6,col="orange")+
labs(title="Top 15 of Company",caption="Data Source:shixiseng")+
coord_polar(theta="x")+
ylim(-40,60)+
scale_size_area(max_size=20)+
guides(fill=FALSE,size=guide_legend(reverse=TRUE,title=NULL))+
theme_minimal()+
theme(
axis.title=element_blank(),
axis.text=element_blank(),
panel.grid=element_blank(),
legend.text=element_text(family="myfont",size=12),
legend.title=element_text(family="myfont",size=15,hjust=1),
plot.title=element_text(family="myfont",size=35),
plot.caption=element_text(family="myfont",size=18,hjust=0,lineheight=1.2)
)
showtext.end()
dev.off()
write.table (myjob[1:100,],"D:/R/File/shixiseng_job.csv",sep=",",row.names=FALSE)
前一百个实习生需求最旺盛企业:

3、实习岗位具体分布的地域和城市?
先做一个地域分布图:
add%as.data.frame(stringsAsFactors=FALSE)%>%arrange(desc(Freq))%>%filter(nchar(Var1)==2)
#城市经纬度查询:
library(rjson)
library(RCurl)
library(REmap)
library(baidumap)
address
baidu_lng
baidu_lat
ak
for(location in address){
url
url_string
msg.load
json
msg.load
},error=function(e) {
"error"
}
)
if(msg.load=='error'){
Sys.sleep(runif(1,3,10))
msg.load
connect
msg.load
}, error = function(e){
"error"
}
)
}
geo
if(msg.load=='error'){
lng
lat
}else{
lng
lat
if(length(lng) == 0){
lng
lat
}
}
lng
lat
baidu_lng
baidu_lat
}
result
pointdata
#成功获取目标城市经纬度信息:
制作地域分布图:
geojson
Encoding(geojson$name)
china_Mapdata
china_MapdataPloygon
CairoPNG(file="E:/微信公众号/公众号——数据小魔方/2017年5月/20170512/shixiseng_jobcity.png",width=1200,height=640)
showtext.begin()
ggplot()+
geom_polygon(data=china_MapdataPloygon,aes(x=long,y=lat,group=group),col="grey60",fill="white",size=.2,alpha=.4)+
geom_point(data=pointdata,aes(x=long,y=lat,size=Freq),shape=21,fill="#C72E29",col="#014D64",alpha=0.6)+
scale_size_area(max_size=15,guide=guide_legend(reverse=TRUE,title=NULL))+
coord_map("polyconic") +
labs(title="实习僧职位需求城市分布图",caption="数据来源:实习僧官网")+
theme(
title=element_text(family="myfont",size=18),
plot.title=element_text(size=24),
plot.caption=element_text(family="myfont",size=18,hjust=0),
panel.grid = element_blank(),
panel.background = element_blank(),






