读过我们专栏的上一集《
天啦噜!没考虑到混杂因素,后果会这么严重?
》的读者,一定已经知道,
多重线性回归
能帮我们控制
混杂变量
的影响,从而我们可以排除一些
虚假关联
,得到更严谨可靠的结论。
现在先让我们来简单地回顾一下我们是怎么做的。
在上一集的例子里,我们想研究的问题是:有两个孩子的家庭中,小孩子的身高与大孩子的身高是不是相关的。于是,我们首先拿小孩子身高做
因变量
,大孩子身高做
自变量
,做了个单因素的线性回归,结果大孩子身高的回归系数显著大于 0。也就是说,大孩子、小孩子身高是显著相关的。
但是,如果我们把父母平均身高也放到线性回归模型里,来自大孩子身高的效应就没了,显著的相关性出现在了父母平均身高和小孩子的身高之间。在这种情况下,对于我们要研究的大、小孩子身高间的关系,父母平均身高就是个
混杂变量
。如果在统计建模时没有考虑到它,我们就会高估了大孩子身高的效应。
在这里,我们要注意一个概念问题——在前后两个模型里,大孩子身高这个自变量的回归系数的意义是不一样的。
在《
自变量不止一个,线性回归该怎么做?
》里,我们强调过,回归系数代表了当模型中其他自变量(如果有)保持不变时,在总体中该自变量每增加一个单位,会对应着因变量的变化大小。前一个模型中只有大孩子身高这一个自变量,它的回归系数表示大孩子身高增加一个单位时对应小孩子身高平均变化多少。
然而,在第二个模型中,大孩子身高的回归系数则是在父母平均身高保持不变的情况下,小孩子身高对应大孩子身高增加的变化率。
因为两者意义本身就不同,所以它们之间有差异,本身并不是一种矛盾。但是,从解读的角度来看,两者都是我们关心的同一个变量的效应大小,我们应该弄清楚,加入其他变量后,这种变化是怎么产生的。
让我们来把上面这个问题抽象化一下,以帮助我们理解更具有普遍性的问题。如果因变量是,我们感兴趣的自变量是,另外还有一个潜在的混杂变量,那么
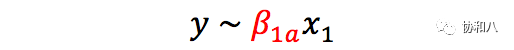
是
不包含混杂变量 x
2
的模型;
而
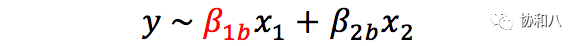
是
包含混杂变量 x
2
的模型。
在上面的例子里,模型中只有 x
1
(大孩子身高)时,它的回归系数 β
1a
显著大于 0。而模型中加入 x
2
(父母平均身高)后,新模型中 x
1
的回归系数 β
1b
则与 0 没有显著差别了,而 x
2
的回归系数 β
2b
则是显著为正的。
☻
这时我们仿佛听见了你的内心戏:
既然 x1 是我比较在乎的那个自变量,那我当然希望得到与 x1 有关的显著结果啦!如果把 x2 加进去以后,我的显著结果就没了,那我干脆就别加了吧?反正人家也不一定知道还有 x2 这回事……
这样行不行呢?
当然不行
。
首先,统计学可不是个任人打扮的小姑娘,我们因为担心结果不一定符合自己的预期,就不去做本来该做的分析了。如果从已有知识来看,x
2
(例如上面例子中的父母身高)的确有可能是混杂变量时,我们更不能忽略它——躲得了初一,躲不了十五,还有审稿人(以及「说人话的统计学」栏目的忠实读者们)盯着呢!
其次,从普遍意义上说,把一个新的自变量 x
2
放到模型里,模型中原有的自变量 x
1
的回归系数是不是一定会像上一个例子那样变小?会不会原来不显著的回归系数反而变大、变显著了?是否也有可能没有变化?我们现在就一起来探讨一下这个问题。
让我们来看一个新的例子。为了强调接下来讨论的一般性,我们这里不引入具体的情景,只把这个新的数据集中我们考虑的因变量称为 y,两个自变量称为 x
1
,x
2
(这组数据具体长什么样我们稍后再讲),而仍旧是我们的重点考察对象。
和之前一样,我们先来一个
只包含 x
1
的线性回归模型:
我们得到了如下结果:
|
估计值
|
t
值
|
p
值
|
95%
置信区间
|
|
(截距)
|
-0.269
|
-2.103
|
0.038
|
[-0.523,
0.015]
|
|
β
1a
|
0.185
|
0.143
|
0.157
|
[-0.072,
0.442]
|
自变量 x
1
的回归系数
β
1a
的估计值为 0.185,然而它与 0 之间的差别并不显著( p = 0.157,大于 0.05),因此从统计学意义上说,我们可以认为和之间并不相关。既然是主要研究的变量,看到这个结果难免让人有点失望。
如果我们把 x
2
加进来会如何?根据模型
这个模型的结果如下:
|
估计值
|
t
值
|
p
值
|
95%
置信区间
|
|
(截距)
|
-0.100
|
-1.052
|
0.295
|
[ -0.288,
0.088 ]
|
|
β
1b
|
0.860
|
6.016
|
3.16
×
10
-8
|
[ 0.577,
1.144 ]
|
|
β
2b
|
-0.876
|
5.724
|
1.16
×
10
-7
|
[ -1.179,
-0.572 ]
|
如果这个结果没有让你感到惊讶的话,也许你就有点儿走神啦——和前面只含x
1
的模型比较,x
1
的回归系数 β
1
从
并不显著
( p 值为 0.157 )的 0.185 猛增到了
高度显著
( p 值在 10
-8
数量级)的 0.860!
换言之,变量x
1
对y 的效应在加入一个新的变量 x
2
以后反而大大增加了!(怎么样?要是你刚才还在打着小算盘,想把 x
2
排除在外,现在得后悔了吧?)
这个例子能教给我们很多东西,但在进一步深入讨论之前,我们至少可以从这个例子中得到一个最明显的结论,线性回归模型里加入新的自变量,模型中已有的自变量的回归系数并不一定会变小,也是
可能会变大
的。
到现在,我们已经见过了两个例子,分别体现了加入新的自变量 x
2
后,原有的自变量 x
1
的回归系数
变小或者变大
这两种情形。
其实呢,我们还在《
自变量不止一个,线性回归该怎么做?
》里介绍过另一个例子,其中孩子身高是因变量,而父母平均身高是自变量,此时我们得到了
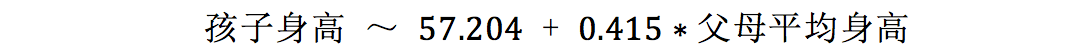
但在加入另一个自变量——孩子性别——之后,新的模型是
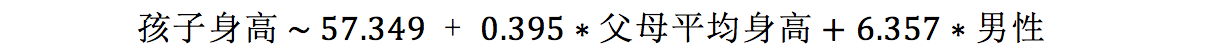
容易发现,父母平均身高的回归系数在前后两个模型中基本没有改变。
各种情形都见过了,现在我们就来一探究竟。
要弄清楚为什么会有这些不同的效果,我们得考虑 y,x
1
,x
2
三者之间存在的
电视剧中屡见不鲜
的三角
恋
关系。
在第一个例子中,x
2
加入模型后,x
1
的效应大大缩小,是因为 y 与 x
2
存在正相关关系,而 x
1
,x
2
之间又是正相关的(见图 1 中相应的小图),因此当我们只看 y 和 x
1
之间是否相关时,实际上看到了 y 与 x
2
、x
2
与 x
1
两层关系的总效果:由于相关性是相互的,通过 x
2
的传递,y 和 x
1
之间也有了相关性(图 1)。但是,如果 x
2
也被包含到了模型里,原本属于它的相关性物归原主,x
1
的回归系数也就小多了。
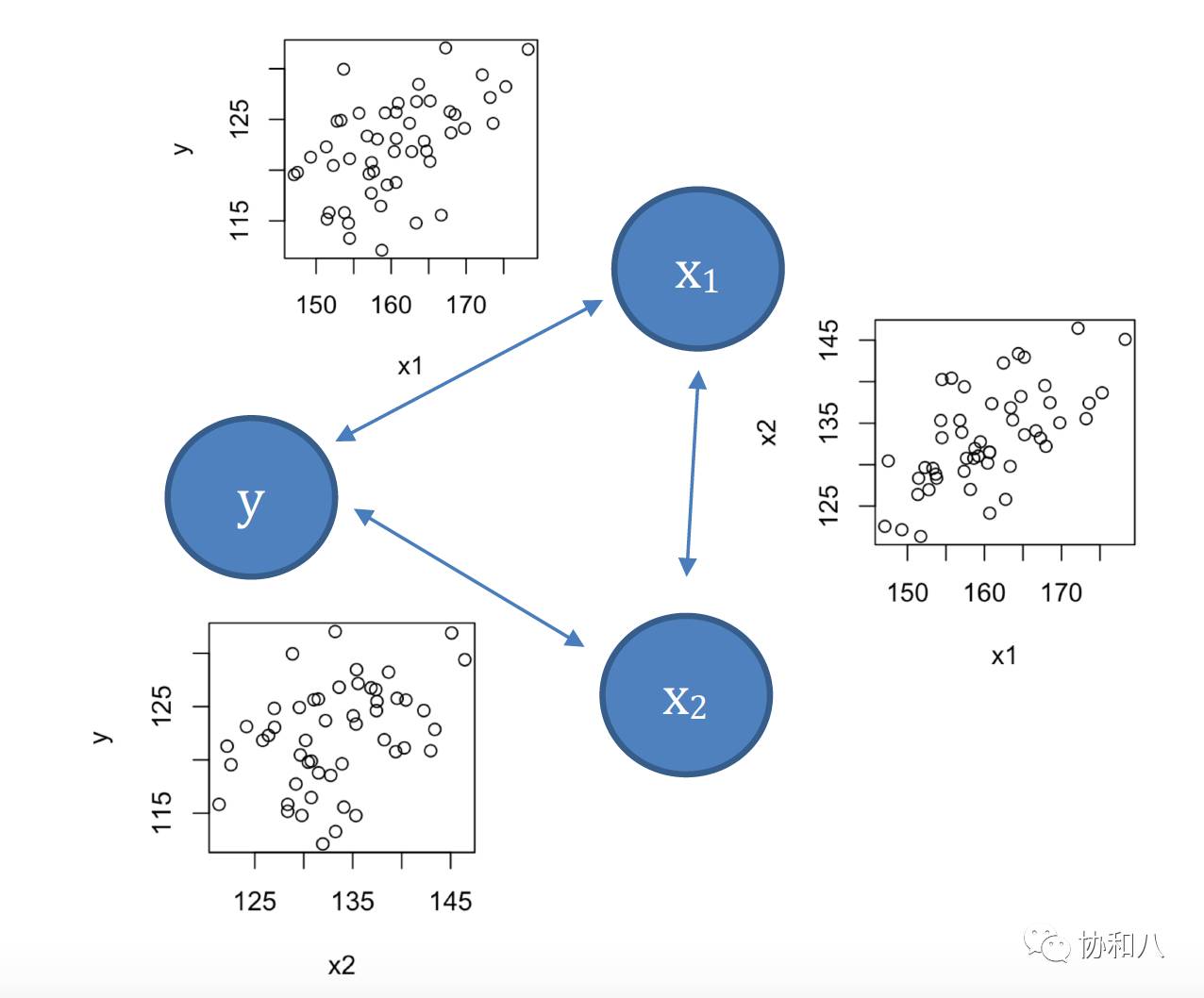
图 1 本文第一个例子中三个变量的相互关系(小图为两两散点图)。例子的具体内容可回顾《
天啦噜!没考虑到混杂因素,后果会这么严重?
》
而第二个例子更绕(但也更有趣)一些,大家在读下面这段文字之前
务必保持头脑清醒
。
在这个例子中,x
1
,x
2
两者在对方保持不变的情况下,分别与 y 有正相关、负相关的关系(可回顾前面的回归模型结果,x
1
,x
2
同时在模型中时,回归系数分别为0.86和-0.87)。但是,x
1
,x
2
之间偏偏又是正相关的(见图 2 右侧小图)——这样一来,每当 x
1
增长时,x
2
由于这个正相关关系,也倾向于有所增长。这时 y 会怎么样呢?x
1
和 x
2
都在增长,而它们一个对 y 有正效应,一个有负效应,这就打起架来了。
最终的结果,就是相互把对方的效应抵消了不少。因此,如果我们不在同一个模型中一起考虑 x
1
,x
2
两者,只分别看 y 与 x
1
或者 y 与 x
2
的关系时,相关性就变得很弱(见图 2 左侧的两个小图)。此时模型 y ~ β
1a
x
1
中的回归系数没有显著性也就毫不奇怪了。
换个角度说,由于 x
1
和 x
2
对 y 的相互抵消的作用,如果我们在分析时只考虑了其中一个,被忽略的另一个变量对 y 的反作用就会「遮盖」住这个自变量的真实效应,因此在统计学中,这种现象被称为
「掩蔽效应」
(masking effect)。
比方说,影响短跑速度的因素中,身高越高,一般短跑速度越快(因为腿长),而体重越大,短跑速度则越慢(因为腿拖不动沉重的身体)。但是,身高和体重互相之间又有正相关关系(平均来说身高越高,体重越大)。这样一来,身高和体重这两个变量之间就会互相产生掩蔽效应,遗漏其中一个,线性回归就容易低估另一个对短跑速度的效应大小。
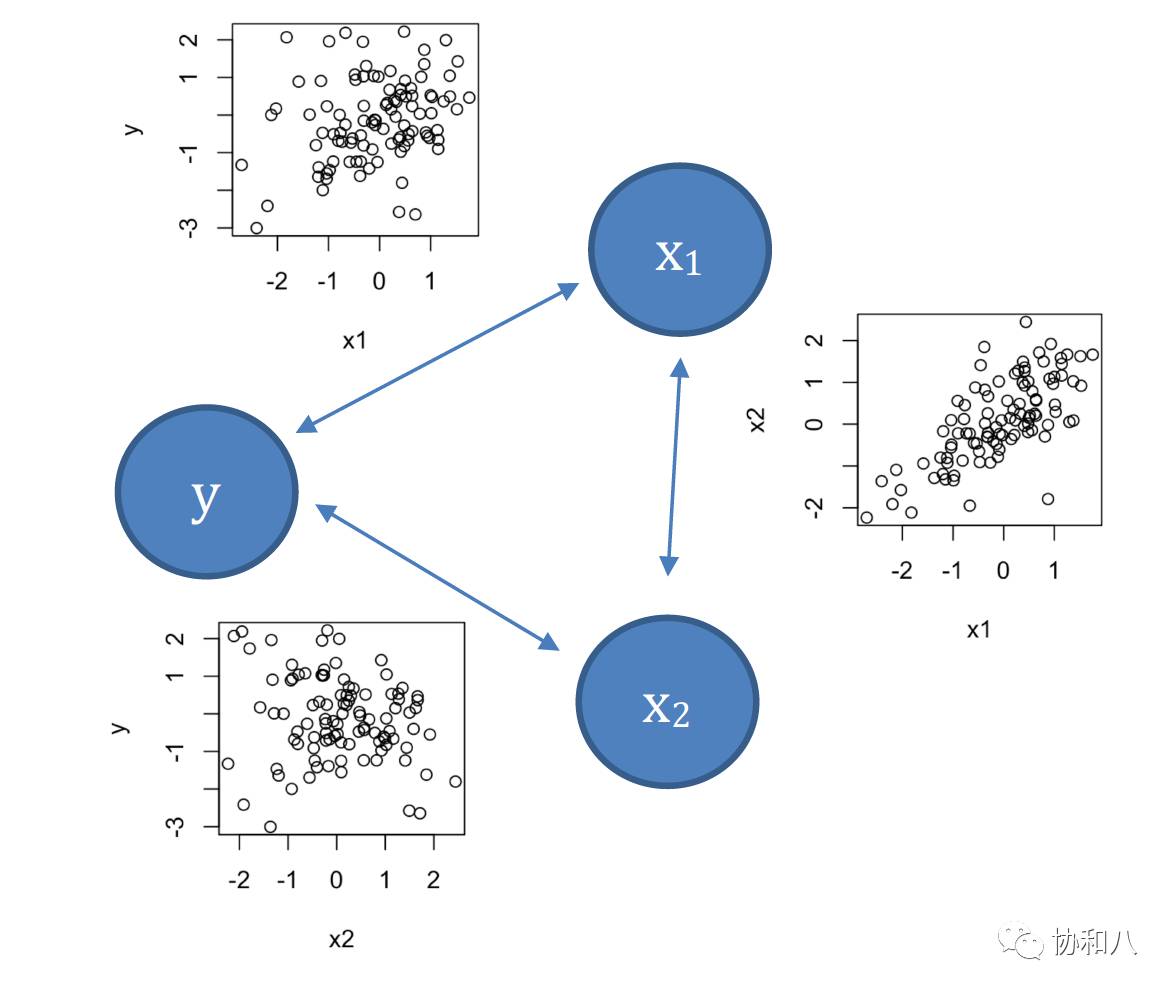
图 2 本文第二个例子中三个变量的相互关系(小图为两两散点图)
那么第三个例子呢?这个例子有些特别,因为后来加进去的新变量 x
2
(性别=男性)是个分类变量,但我们还是可以用一样的方法来讨论。在这里,父母平均身高 x
1
和「男性」x
2
与孩子身高 y 都有正相关关系(见图 3 左侧的两个小图,「男性」与孩子身高的正相关关系体现为男孩身高大于女孩),而父母平均身高 x
1
和「男性」x
2
之间并不相关(图3右侧小图:男孩和女孩的父母平均身高没有差别)。因此,当只考虑一个自变量时,由于该自变量和另一个自变量之间缺乏相关性,所以本来属于另一个自变量的与 y 的相关性它也抢不走。这样一来,单独考虑一个自变量和同时考虑两个自变量时得到的回归系数就会基本一样了。
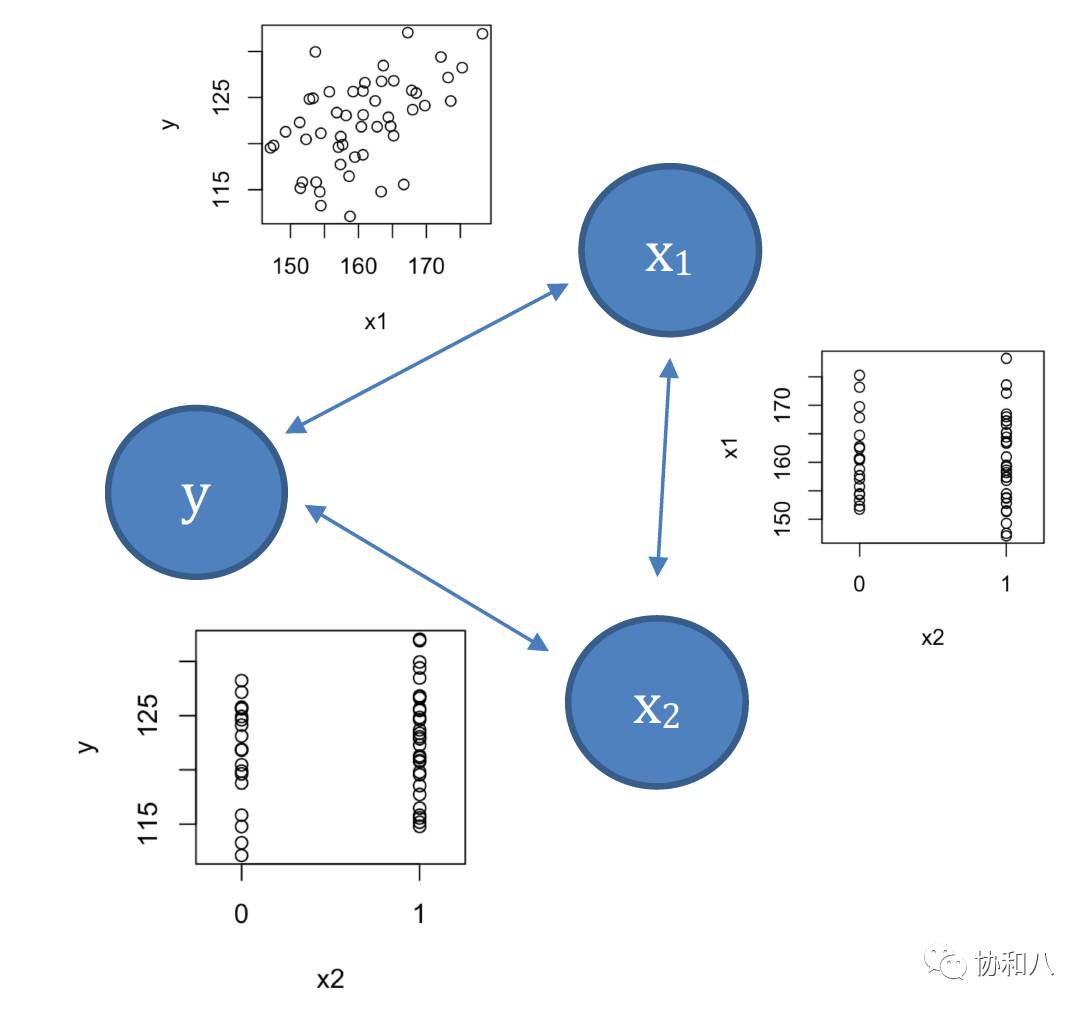
图 3 本文第一个例子中三个变量的相互关系(小图为两两散点图)。例子的具体内容可回顾《
自变量不止一个,线性回归该怎么做?
》
这三个例子的来龙去脉弄清楚了,相信你已经能够归纳出,加入模型的新变量如果导致了原有变量回归系数的改变,那么一定是因为新的自变量与原有自变量之间存在相关性,而且新的自变量同时与因变量之间也有相关性。至于回归系数会怎么变,那就取决于自变量之间相关性的方向,以及几个自变量与因变量 y 之间相关性的异同了。上面的三个例子覆盖了三种典型的情况,其它的情形欢迎大家茶余饭后脑有余力之时,自行推演一下。










