1912年泰坦尼克号(RMS Titanic)的沉没恐怕是历史上最著名的船灾了,但对于机器学习和数据挖掘领域的学生来说,泰坦尼克号的船灾却有另一种熟悉——它是数据竞赛平台Kaggle上的公益入门竞赛题,参赛者需要通过892位带有姓名、性别、年龄、票号、船费、仓位、上船港口、父母子女以及兄弟姐们配偶数量的乘客数据,使用机器学习的工具,分析出乘客生还的几率。

自2012年这些数据上线已来,4年多的时间已经有6080个团队尝试过这道试题,在机器学习和数据挖掘领域,这无疑是一个相当大的数字了。
Kaggle是国际著名的数据建模和数据分析竞赛平台,成立于2010年。与之相似的,还有已近20年历史的顶级数据挖掘赛事KDD-CUP。在数据挖掘和机器学习领域,由于学校缺少大规模的应用数据,国内外不少学校都把类似Kaggle、KDD-CUP这样的数据竞赛当做训练学生的重要途径。著名的清华大学的姚班,就把Kaggle的组队比赛成绩作为重要的考核标准。
少有人注意到的是,国内互联网公司,尤其是新兴公司,也开始日益重视数据竞赛。2014年阿里做了第一届“天池”,2015年滴滴做了第一届Di-Tech,今年今日头条也加入,做了基于问答数据的BYTE CUP。移动互联网时代,在人工智能产品应用层面已经和美国同时起跑的中国,已经到了可以出现世界级数据大赛的时候了吗?
和大多数学术向竞赛不同,数据挖掘以及机器学习领域的竞赛,从诞生之日起就有明显的工业应用色彩,并和企业、政府高度相关。
ACM (美国计算机协会)下属数据挖掘及知识发现专委会(SIGKDD)从1995年开始固定举办的ACM-SIGKDD 国际大会,是知识发现及数据挖掘领域(Knowledge Discovery and Data Mining)的顶级技术大会。1997年,KDD推出了KDD-CUP,这是该领域迄今为止最重要的国际赛事。
KDD-CUP的应用色彩非常显著。1997年首届KDD-CUP,是由美国瘫痪退伍军人协会(Paralyzed Veterans of America)提供的350万捐赠者的捐赠记录,目标是希望通过数据分析,得出哪些人更有可能成为捐赠者,以帮助协会更准确的发送求助邮件。
1999年的数据集则更为经典,是来自于美国国防部高级规划署(DARPA)在MIT林肯实验室做的入侵检测评估项目数据,希望参赛者能够分别那些操作是外部入侵。这一年的获胜者,是著名的SAS公司。
KDD CUP的协办单位一般是微软、雅虎、Facebook、卡耐基梅隆大学、法国电信、西门子医疗,这些久负盛名的机构/公司。
而2010年成立的Kaggle则是一个数据竞赛平台,上面的比赛有获得面试类的,提供奖金类的,还有纯粹练习用的。泰坦尼克的数据就是一个练习比赛。实际上,不少公司都会在上面开放自己的数据,举办数据竞赛,发现人才。
对于政府、企业来说,通过开放特定数据举办比赛,一方面可以通过众包的方式,寻找更好的解决问题的方式,同时,能够提供数据本身,也是对企业数据能力的一种证明。
通常被国际顶级学术会议选中的合作伙伴,都是能提供极有前沿应用价值的大规模数据的机构,而且一旦被选中,他们开放的数据往往成为数据挖掘从业者研究和开发的范本训练数据。

另一方面,对于互联网企业来说,数据竞赛也可以发现、储备优秀的人才。
实际上,IBM Watson以及Google Deep Mind 的不少成员都活跃于Kaggle,Kaggle甚至推出了求职版面。至于KDD-CUP,获胜者更是各大公司的目标候选人,就中国选手来看,05年HKUST的沈抖就被微软总部挖走,11年中科院的项亮也加入了美国视频推荐网站hulu。
虽然KDD-CUP至今已经接近20年,但数据竞赛这种“亚文化”真正受到关注,还是随着大数据时代,甚至移动互联网时代的到来才为人所知的。
移动互联网时代,由于手机贴身携带,许多公司,尤其是移动互联网公司拥有了海量的个性化数据,这使得更精细、更深入的数据挖掘和机器学习成为可能。
在数据领域存在两种壁垒,一种是技术上的,比谁的算法更优;一种是资源上的,比谁的数据更多更全。这两种壁垒并不一定同时存在,有数据壁垒的未必有技术壁垒,反之亦然。
拥有资本和海量数据的业界,正不断寻找优秀人才打破技术壁垒。就在今年,斯坦福教授、ImageNet缔造者李飞飞加盟Google,卡耐基梅隆大学机器学习副教授Russ Salakhutdinov去了苹果,深度学习“三巨头”之一Yoshua Bengio创办的MILA实验室接受了来自Google的一笔捐助(用于加速算法的实际应用),中科院智能信息处理重点实验室常务副主任山世光下海创业,ACL Fellow林德康创办奇点机智。
而今年的SIGKDD上,微软亚洲研究院的研究员郑宇分享了一组数据,2015到2016年中国两岸三地被KDD录用的文章中偏理论研究的文章数量大幅下降,但偏应用的文章大幅上升。这也显示出,新时代对业界对学界的影响。
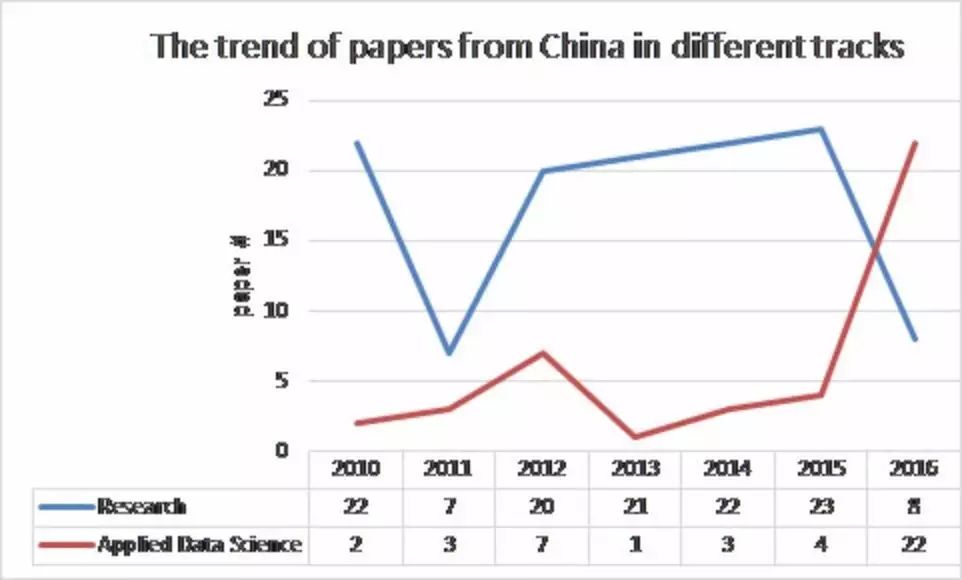
对于学界来说,数据壁垒更为严重。很多机器学习和数据挖掘的课程,都是演示性的少量数据。真实世界里,数据是海量的,充满缺失和不足的。实际工作中,很多数据分析工作都是和真实世界里的缺陷做斗争。
一个征信从业者招聘的时候发现了一个现象:他们面试了好几个美国最好的学校出来的博士生,给他们一组数据,让他们自己定义可以返回什么结果,为什么定义这样的指标,结果十个里面有八九个都会用“准确率”来作为衡量算法是否准确的唯一标识,但实际上这样的判断标准在征信领域并不适用。
于是拥有企业、政府真实数据的数据竞赛就开始日益受到学界的关注。2005年的KDD-CUP的参赛队伍提交还只有三十多次,但到2011年,就已超过1000次提交,这意味着参赛队伍大幅增加。

反观国内,人才、学界还是业界,目前都已经做好了出现顶级国际赛事的准备。
2012年KDD CUP Track1冠军是上海交通大学ACM班(亚军来自盛大创新院团队),2013年两个赛题的双料冠军是本科就读于浙大、研究生就读于台湾大学的庄勇,2014年的冠军团队成员之一Peng Liu,2015年冠军团队“Intercontinental Ensemble”由有道计算广告团队成员燕鹏带队,2016年桂冠旁落他人,但清华大学的钱雨杰团队也摘得了亚军。
实际上,中国团队差点儿包揽了KDD CUP过去5年的所有冠军。这意味着即便和人工智能的早期推动者美国日本相比,中国的AI的人才也已不落下风。
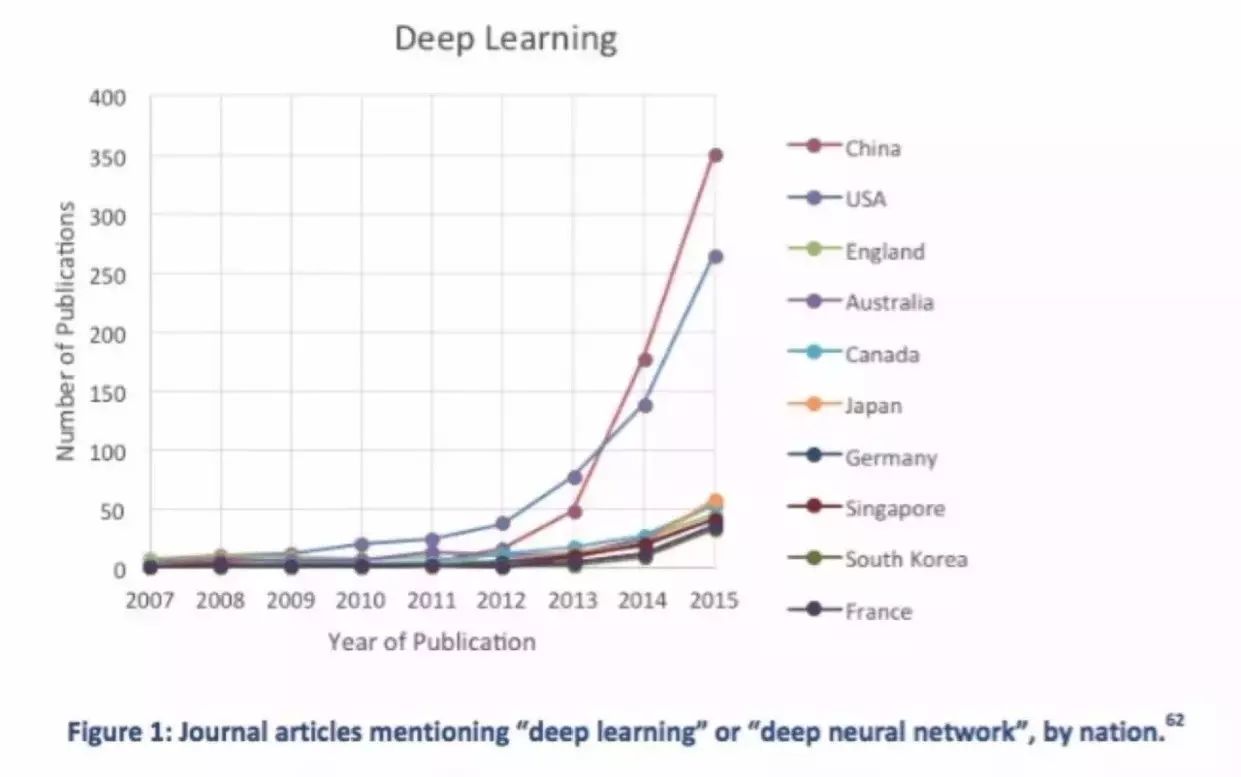
另一个数据是美国科学技术政策办公室发布的白皮书,在这个图表里我们可以看到,就深度学习这一母题的论文数量,中国已经超过美国,居第一位。
此外,中国人工智能和大数据的发展速度也令人刮目。2014年国内新增150多家人工智能企业,2015 年新增 160 家左右,这两年新增的人工智能企业数超过了之前 10 年的总和。

实际上,近几年KDD CUP协办单位列表中已经出现了一些熟悉的名字,2012年KDD CUP的协办单位是腾讯,2014年是学堂在线。
当人才、学界都已经有相当的储备,中国企业,尤其是新兴企业自然开始尝试牵头组织大规模的数据竞赛,而这些比赛的数据中,一些甚至已经有了政府的身影。
阿里的天池是先行者,2015年他们竞赛中的一场,就是与广东省人民政府合作,要求选手挖掘市民在公共交通中的行为模式,以解决城市公交线路客流不均衡及出行拥堵等问题。
8月份,成立刚刚4年的今日头条也和IEEE中国和中国人工智能学会联合举办了ByteCup。今日头条上线了“头条问答”,其中网友提的一些诸如网络约车普及后出租车司机的现状如何、退伍军人在什么情况下会被召回、为什么政府今年要大力推动银行投贷联动等非结构化的问题——机器无法回答,必须匹配到特定的人,而 ByteCup这次比赛的任务是建立预测专家可能回答某一问题的概率的模型,从而找到那个“特定的人”。这个题目之所以能成为竞赛的赛题,是因为今日头条数以亿计的日活产生了足够多的有效数据。
与之前中国选手参加国外比赛不同,这次比赛有相当选手来自海外,一等奖队伍BrickMover中的两位博士就来自Georgia Institute of Technology。
除去头条,滴滴也在做Di-Tech数据竞赛。相比上一代科技公司,诞生于移动时代的今日头条和滴滴显得更年轻,也更为重视产品背后的技术竞争和应用。今日头条算法架构师曹欢欢在接受采访时明确的表述,这次比赛的目的,就是为了和学界有更多交流,“顺便也挖掘一下相关的技术人才”。
相比美国,中国在移动数据时代,用户数据、政府政策、资本投入和人才储备上,已经拥有了相当的优势。普遍的观点是,中国在移动互联网时代的产品创新已经不弱于美国。
今日头条这些拥有海量数据的新兴企业在数据竞赛上的发力,很可能意味着一个新时代的到来——或许不久之后,到今日头条或者阿里、滴滴的平台上参加竞赛,会代替Kaggle,成为国内外顶级高校机器学习学生们的必修课。










