0x00 背景
最近,偶然看到一篇论文讲如何利用机器学习从加密的网络流量中识别出恶意软件的网络流量。一开始认为这个价值很高,毕竟现在越来越多的恶意软件都开始使用TLS来躲避安全产品的检测和过滤。但是看完论文之后又有些失望,虽然文章的实验结果非常漂亮,但是有一点治标不治本的感觉,机器学习又被拿来作为一个噱头。
回顾过去的几年,机器学习在安全领域有不少应用,但其处境却一直比较尴尬:一方面,机器学习技术在业内已有不少成功的应用,大量简单的重复性劳动工作可以很好的由机器学习算法解决。但另一方面,面对一些“技术性”较高的工作,机器学习技术却又远远达不到标准。
和其他行业不同,安全行业是一个比较敏感的行业。比如做一个推荐系统,效果不好的最多也就是给用户推荐了一些他不感兴趣的内容,并不会造成太大损失;而在安全行业,假如用机器学习技术做病毒查杀,效果不好的话后果就严重了,无论是误报或漏报,对客户来说都会造成实际的或潜在的损失。
与此同时,安全行业也是一个与人博弈的行业。我们在其他领域采用机器学习算法时,大部分情况下得到数据都是“正常人”在“正常的行为”中产生的数据,因此得到的模型能够很好的投入实际应用中。而在安全领域,我们的实际对手都是一帮技术高超、思路猥琐的黑客,费尽心思构建的机器学习模型在他们眼中往往是漏洞百出、不堪一击。
如何让机器学习从学术殿堂真正走进实际应用,是每个安全研究人员值得思考的问题。本文从我所了解的一些案例和研究成果谈谈个人的看法和思考。
0x01 从加密的网络流量中识别恶意软件?
既然文章的开头提到了从加密的网络流量中识别恶意软件,我们先来看看这个论文的作者是如何考虑这个问题的,他们发现,在TLS握手阶段(该过程是不加密的),恶意软件所表现出的特征与正常的应用有较大区别。典型的TLS握手过程如下图所示:
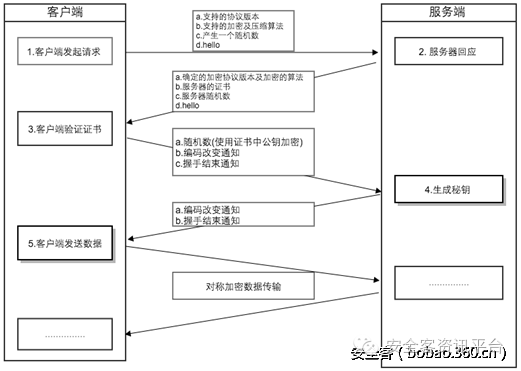
在握手的第一阶段,客户端需要告诉服务端自身所支持的协议版本、加密和压缩算法等信息,在这个过程中,正常的应用(用户能够按时更新)使用高强度加密算法和最新的TLS库,而恶意软件所使用的往往是一些较老版本协议或强度较低的加密算法。
以此作为主要特征,加上网络流量本身的信息如总字节数大小、源端口与目的端口、持续时间以及网络流中包的长度和到达次序等作为辅助特征,利用机器学习算法即可训练得到一个分类模型。
看完这段描述,我的内心是崩溃的,因为该方法是把TLS握手阶段的信息作为主要特征来考虑的。道高一尺,魔高一丈。以其人之道,还治其人之身,这句话点中了机器学习的死穴,我相信凡是看到这个篇论文的黑客都会想到:以后写木马的时候一定要采用最新版本的TLS库,和服务器通信时采用加密强度较高的算法,尽量选取和正常应用类似的参数……做到以上几点,论文中提出的方法就可以当成摆设了。
0x02 域名生成算法中的博弈
早期的一些DGA算法所产生的域名有着比较高的辨识度,例如下面这些域名
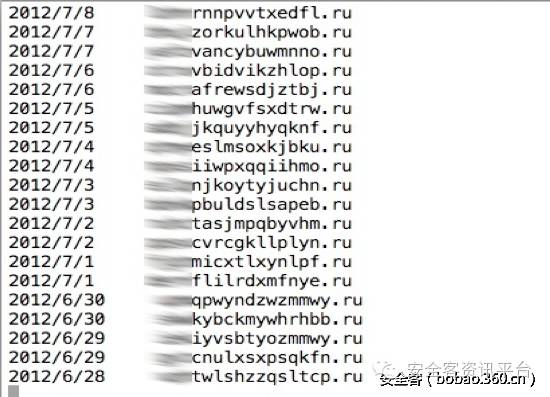
给我们的直观感受就是英文字母随机出现,而且不是常见的单词或拼音的组合,而且很难“念”出来。事实上这些特征可以用马尔可夫模型和n-gram分布很好的描述出来,早就有相应的算法实现,识别的效果也非常不错。然而,很快就出现了一些升级版的DGA算法,如下面的这个域名

这无非就是随机找几个单词,然后拼凑在一起构成的域名,但是却完美的骗过了我们刚才提到的机器学习方法,因为这个域名无论从马尔可夫模型或是n-gram分布的角度来看,都和正常的域名没有太大的区别。唯一可疑的地方就是这个域名的长度以及几个毫无关联拼凑在一起的单词,所以额外从这两个角度考虑仍然可以亡羊补牢。
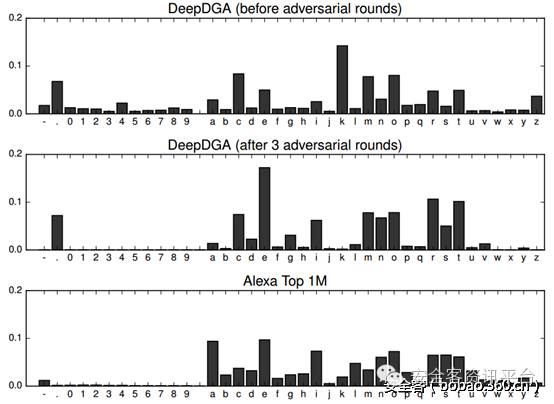
更有甚者,在今年的BSidesLV 2016上,有人提出了一种基于深度学习的DGA算法——[DeepDGA],将Alexa上收录的知名网站域名作为训练数据,送入LSTM模型和生成对抗网络(GAN, Generative Adversarial Networks)训练,最终生成的随机域名效果拔群。如下图所示(左侧是给定的输入)

从字符的分布情况上来看,也与正常网站的域名基本一致
随着深度学习技术的普及,或许在不久的将来安全研究人员就可以“惊喜的”发现某个勒索软件家族开始采用这种高端的域名生成算法了……
0x03 来自恐怖分子的垃圾邮件
事实上类似域名生成算法的博弈早就出现了,2003年美国打击塔利班武装时,从一名恐怖分子手中缴获了一台笔记本电脑,发现里面用于通信的电子邮件的风格都是典型的垃圾邮件,而真正传递的消息暗藏于这样的垃圾邮件中。因为面对NSA这样无孔不入的情报机构,越是遮遮掩掩,越是采用高强度的加密,反而越容易被盯上。
同样因为NSA的无孔不入,他们每天需要处理的数据量也是天文数字,仔细检查所有数据是不可能的,必须有所取舍,而这其中有一类数据恰恰是被NSA所忽视的,那就是每天成千上万的垃圾邮件。
在机器学习算法大行其道的今天,各大邮件服务提供商早就配备了一套成熟的垃圾邮件检测系统,无论是采用逻辑回归算法或是SVM算法,只要加上几句诸如优惠代开各类发票或是想免费拥有自已的xxx这样的垃圾邮件标配,妥妥的直接过滤掉。如果一封邮件都被邮件服务提供商认定为垃圾邮件,NSA又有什么理由去进一步怀疑呢?
退一步讲,如果NSA想找出混在垃圾邮件中的有价值情报该怎么做呢?设关键词吗,上更复杂的机器学习算法吗?要是恐怖分子采用类似“藏头诗”这样的信息隐藏手法怎么办?
有的同学说还可以通过邮件的通连关系啊,如果你听说过“死邮件”就不会这么想了。两人共用一个账号,利用邮箱的草稿箱传递消息,完全没有邮件的发送与接收等通连关系,这又是不按套路出牌。
0x04 容易被骗的图像识别
近几年来,如果你稍有关注图像识别领域,就知道基于深度学习技术的图像识别技术在各大图像识别比赛中大放异彩,甚至在某些任务上超过了人类。虽然目前人们仍然不能很好的解释为什么深度学习技术如此有效,但这依然阻挡不住众多数据科学家们孜孜不倦的搭建模型、调优参数。
但正当一票又一票研究小组努力“刷榜”的时候,另一些人总是能看的更远一些。谷歌的Szegedy研究员就发现,基于深度学习的图像识别技术可能并不如我们相像的那么靠谱,利用一些简单的trick即可将其轻松欺骗。如下图所示:

这两幅图在我们正常人眼中并没有太大区别,但是对图像识别系统,左图能够正确的识别为熊猫,右图却识别成了长臂猿,而且是99.3%的置信度
而更为诡异的是一些在我们人类看起来毫无意义的图片,却被图像识别系统“正确”的识别了出来。比如下面这些例子

0x05 一起躺枪的自动驾驶
关于自动驾驶汽车的安全问题,国内外众多安全公司和研究人员已经做了很多次详细的分析和现场演示。例如在今年的ISC 2016上,来自浙大的徐文渊教授团队和360汽车信息安全实验室共同演示的针对特斯拉Model S汽车自动驾驶技术的攻击,通过干扰特斯拉汽车的三种传感器(超声波传感器、毫米波雷达和前置高清摄像头),可以实现强制停车、误判距离、致盲等多种不安全的情况。
以上都是黑客主动发起的攻击,自动驾驶自身也存在着缺陷。今年5月发生在美国发生的自动驾驶系统致人死亡的案例也引发了社会的大量关注:
按照特斯拉的解释,这起事故发生时,车主布朗正驾驶Model S行驶在一条双向、有中央隔离带的公路上,自动驾驶处于开启模式,此时一辆牵引式挂车与Model S垂直的方向穿越公路。
特斯拉表示,在强烈的日照条件下,驾驶员和自动驾驶系统都未能注意到牵引式挂车的白色车身,因此未能及时启动刹车系统。而由于牵引式挂车正在横穿公路,且车身较高,这一特殊情况导致Model S从挂车底部通过时,其前挡风玻璃与挂车底部发生撞击,导致驾驶员不幸遇难。
正如这起事件暴露出来的问题,当车身周围传感器和车前的毫米波雷达都失灵时(当然该案例中这传感器和毫米波雷达并未失灵,而是由于毫米波雷达安装过低,未能感知到底盘较高的卡车),唯一能依靠的输入就是车窗前方的高清摄像头。我们来看看事发当时的街景现场

以及被撞的卡车样式(注意白色车身上什么标致都没有)

由于车前的高清摄像头为长焦镜头,当白色拖挂卡车进入视觉区域内的时候,摄像头只能看到悬浮在地面上的卡车中部,而无法看见整个车辆,加上当时阳光强烈(蓝天白云),使得自动驾驶统无法识别出障碍物是一辆卡车,而更像是飘在天上的云。再加上当时特斯拉车主正在玩游戏,完全没有注意到前方的这个卡车,最终导致悲剧发生。
结合刚才的图像识别对抗样本和浙大徐文渊教授团队的研究成果,我们完全有可能设计一个让自动驾驶系统发生车祸的陷阱,例如在某个车辆上喷涂吸收雷达波的涂料以及带有迷惑性的图案,让自动驾驶系统无法识别出前方的物体;再比如,找个夜深人静的夜晚在道路标识上加一些“噪音”,人类可以正常识别,而自动驾驶系统却会误判等等。
0x06 邪恶的噪音与隐藏的指令
除了容易被骗的图像识别系统,我们每个人手机上的语音助手同样不靠谱,也许未来某天你正在使用语音助手时,旁边突然传来一串奇怪的声音,你的手机就诡异的打开了某个挂马网站或者给一个完全不认识的人转账。
来自加州大学伯克利分校的Carlini等人发现一些语言助手如`Google Now`和`Siri`都有可能理解一些人类无法辨识的“噪音”,并将其解析为指令进行执行。其实原理并不难理解,人工生成这种邪恶的噪音流程如下
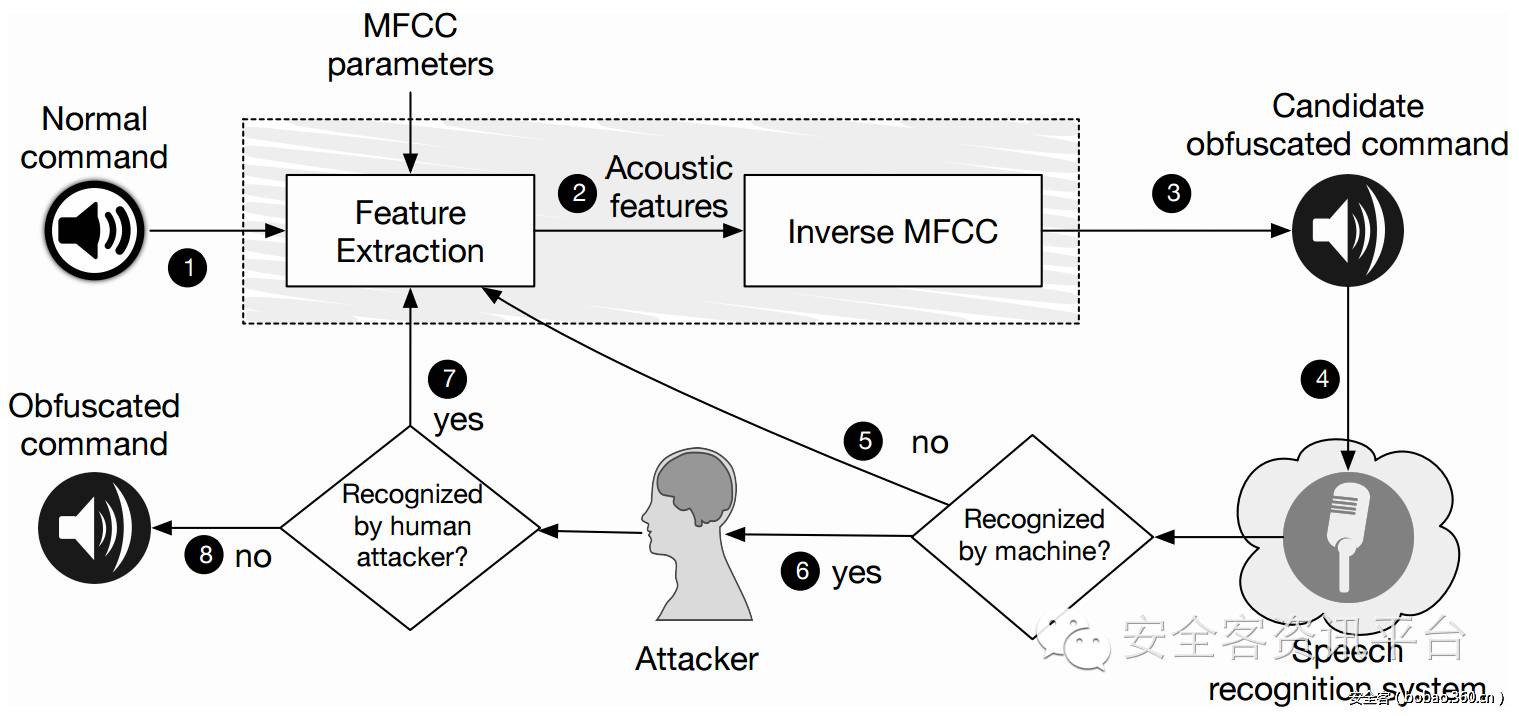
如图所示,这是一个反复迭代的过程。我们首先通过抽取正常语音中关键特征,再做一次“逆向特征”合成语音并加入一些噪音作为候选,并将其分别给语音识别系统和正常人播放试听,直到得到一个语音识别系统可以识别而人类无法辨识的邪恶噪音。
0x07 思考与对策
看完上文中提到的这些案例和分析,相信同学们有自己看法和认识。我也简单谈谈我个人的一些思考。
1. 最基本的一点是不要迷信机器学习,不要觉得机器学习是解决一切问题的银弹。有的同学总觉得自己懂机器学习,那些靠人工上规则的办法就是low,这种就是典型的学术思维,真正在业务系统中纯粹靠机器学习算法硬上的迟早是要栽跟头的。只有抛开这种观念,从实际角度出发才能想出切实可行的方法。
2. 尽量从多个数据来源或者多个特征维度综合分析。以随机域名生成算法为例,单靠域名本身的特征很难判断其是否为C&C域名时,就应该从多个数据渠道入手进一步分析,如恶意软件家族的域名关联关系以及和某个可疑进程的通信行为等。
3. 要有未雨绸缪的思维,在用机器学习算法解决一个问题的同时,应该从黑客猥琐的角度思考如何攻击这个算法,而不是简单的回避,为了解决问题而解决问题。
4. 本文提到了对抗样本现象(图像识别、语音识别都有涉及),目前学术界称之为**生成对抗网络(GAN, Generative Adversarial Networks)**,虽然目前还没有实际的攻击案例,但特斯拉的车祸其实已经敲响了警钟。
就像著名黑客Barnaby Jack在Black Hat USA 2010上演示的针对ATM机的攻击,当时人们觉得非常科幻,现实中不一定存在这样的威胁,而今年发生的几起黑客攻击ATM机事件(`台湾第一银行ATM机遭黑客入侵 吐出7000万台币`、`泰国ATM机被入侵导致1200万泰铢被盗`)才让人们真正意识到原来这些看似只在电影的中发生的情节在真实世界中同样存在。
当黑客都开始研究机器学习技术了,我们又有什么理由落后呢?
参考资料
1. [DeepDGA: Adversarially-Tuned Domain Generation and Detection]
2. [Predicting Domain Generation Algorithms with Long Short-Term Memory Networks]
3. [Intriguing properties of neural networks]
4. [Explaining and Harnessing Adversarial Examples]
5. [Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images]
6. [Hidden Voice Commands]
往期回顾
















