
本文来自作者
沧夜
在
GitChat
上分享「TensorFlow 优化实践」,
「
阅读原文
」查看交流实录
「
文末高能
」
编辑 | 乌索普
写在前面的话
在前面一章中说到了 TensorFlow 的基础用法
(http://gitbook.cn/m/mazi/activity/599d3d2839e4774d0db015cc)
,这一章作为一个进阶来聊聊神经网络的具体的结构和参数问题,包括:
-
前馈神经网络
-
循环神经网络
-
神经网络参数
大概就这三个中心内容。当然每个部分展开又是很多东西,但是好在这里只是聊聊工具的使用。所以大概还是一个章节的内容。
前馈神经网络
前馈神经网络包括全链接网络与卷积神经网络,这两者其实并没有大的区别,一般情况下可以将卷积神经网络看做是一个特例。
全链接网络与卷积网络
霍金说过科普书里加一个公式就会少一半读者,所以这里用公式来直观的说明二者的共同点:
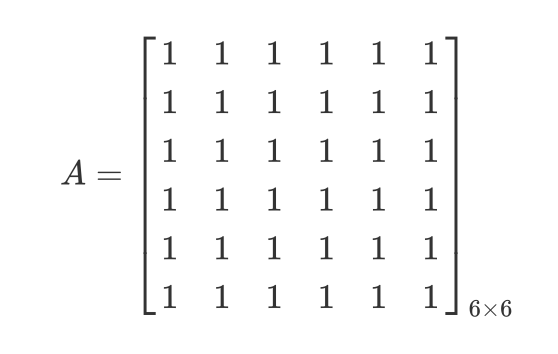
前面说到全链接网络是一个矩阵相乘的过程:
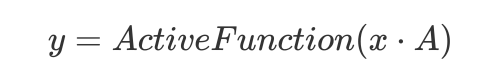
这是一个全链接网络,x是一个一维向量,全链接网络的一个问题就是参数量有点大,设想一下,如果x,y的维度均为1000的话那么显然所需矩阵A的参数数量轻而易举的就到达了个,对于序列数据(比如一维的声音数据、二维的图形数据)而言显然其特征很大程度上可能只与其临近的数据有关,这就使得权值向量在计算的时候可以将用不到的部分省略:
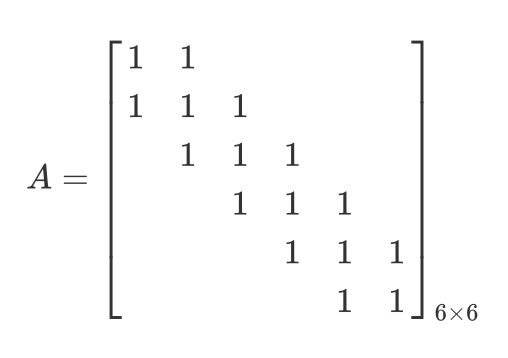
上面的矩阵代表在隐藏层计算过程中只计算与其临近的三个点,其他部分不进行计算,这样使得矩阵A的参数数量得到了有效的减少,另外由于序列数据或图像数据在计算过程中特征的相似性,使得各个部分的特征具有重复性,这样在计算中就可以利用同一套权值:
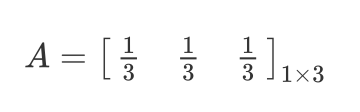
这就是所谓的
权值共享
,通过这个过程,就可以使得全连接层中的参数量极大的减少。
这个就是全连接网络和卷积网络的共同点。
提一下,上面那个卷积核心可以计算的特征是“滑动平均”。
接下来看下函数的傅里叶展开:
这是函数的傅里叶展开,这里隐藏了卷积神经网络的一个思想,如果将序列x看成一个函数的话那么其特征可以用一系列的简单函数去表示。
而相应的权值就是三角函数与原函数的积分,这个积分的过程就可以看做是卷积神经网络的卷积的过程。
前面矩阵的例子中卷积核心只有一个,能拾取的特征为“均值”,而卷积核心可以有多个,每个卷积核心与原有序列x均做一次卷积的话所得到的就是对应每个特征的权值序列。
傅里叶展开的一个特点就是n越大越接近于原函数,那么到卷积神经网络这里就可以将期描述为卷积的特征越多越可以更好的描述数据的特征。
用 tensorflow 来直观的理解一下卷积的过程:
import tensorflow as tfimport numpy as np
kn=np.ones([3,1,2],dtype=np.float32)
kn[:,:,0]=1/3kernel = tf.Variable(kn)
x = tf.Variable(np.ones([1,1000,1],dtype=np.float32))
y = tf.nn.conv1d(x,kernel,stride=1,padding="SAME")
sess=tf.Session()
sess.run(tf.global_variables_initializer())
print("Out:",sess.run(y))
print("Shape:",np.shape(sess.run(y)))
这是一个长为1000的一维向量,其特征只有一个最前面的1代表输入数据个数为1,卷积核心维度为 [3,1,2],3代表卷积核心大小,也就是前面所说的能覆盖多少数据点,1代表输入数据特征数量,2是输出数据特征数量,可以看到,对于第0个特征其卷积核心的权值为也就是求取均值,第二个卷积核心权值为1,也就是对三个数据进行相加,可以看下最终结果:
Out: [[[ 0.66666669 2. ]
[ 1. 3. ]
[ 1. 3. ]
...,
[ 1. 3. ]
[ 1. 3. ]
[ 0.66666669 2. ]]]
Shape: (1, 1000, 2)
可以看到,输出数据特征并没有什么违反直觉的地方,输出为两个特征,第一个特征为均值,第二个为相加,由于 padding 边界设置为“SAME”,也就是从第一个点开始作为输出点,这就使得超出部分的权值、数据赋为0。
当然在神经网络之中前面Variable是需要自适应的变化调整以提取特定数据的特征。
tensorflow 构建前馈神经网络
用 tensorflow 构建前馈神经网络总共分为三种方式:
第一种:直接构建
import tensorflow as tfdef conv1d_layer(input_tensor, kernel_size, feature=2, active_function="relu", name='conv1d'):
activ={"relu":tf.nn.relu,"sigmoid":tf.nn.sigmoid,"tanh":tf.nn.tanh} with tf.variable_scope(name):
shape = input_tensor.get_shape().as_list()
kernel = tf.get_variable('kernel',
(kernel_size, shape[-1], feature),
dtype=tf.float32,
initializer=tf.constant_initializer(0))
b = tf.get_variable('b',
[feature],
dtype=tf.float32,
initializer=tf.constant_initializer(0))
out = tf.nn.conv1d(input_tensor,
kernel,
stride=1,
padding='SAME') + b return activ[active_function](out)def full_layer(input_tensor, out_dim=2, active_function="relu"
, name='full'):
activ={"relu":tf.nn.relu,"sigmoid":tf.nn.sigmoid,"tanh":tf.nn.tanh} with tf.variable_scope(name):
shape = input_tensor.get_shape().as_list()
W = tf.get_variable('W',
(shape[1], out_dim),
dtype=tf.float32,
initializer=tf.constant_initializer(0))
b = tf.get_variable('b',
[out_dim],
dtype=tf.float32,
initializer=tf.constant_initializer(0))
out = tf.matmul(input_tensor,W) + b return activ[active_function](out)
上面是用 tensorflow 函数构建的全链接网络与卷积神经网络。函数调用过程可以使用:
net=full_layer(xx, featrue=2, active_function="relu", name="full_connect_1")
net=conv1d_layer(net,3, feature=2, active_function="relu", name="conv1d_1")
这样就构成了单一层神经网络的构建。
对于多层神经网络而言可以将输出数据进行进行卷积和全链接操作:
net = conv1d_layer(net, 3, feature=2, active_function="relu", name="conv1d_1")
net = conv1d_layer(net, 3, feature=2, active_function="relu", name="conv1d_2")
net=conv1d_layer(net, 3, feature=2, active_function="relu", name="conv1d_3")
当然每层的 name 要不同,否则会报错。
第二种:通过 contrib 高层次 API
前面用一些基本的 API 构建过程需要自行的去写一些函数,但是这个函数是可以通过 contrib 里面的函数去进行简单的构建的:
import tensorflow.contrib.slim as slim
net = slim.conv2d(net, 3, 1, scope='conv1d_1')
net = slim.flatten(net)
net = slim.flatten(net)
net = slim.fully_connected(net, 2,
activation_fn=tf.nn.relu,
scope='outes',
reuse=False)
可以看到通过 slim 高层次 api 实际上可以简化整个网络的构建过程。这里有个 reuse 参数,是复用参数。
通过 keras 构建神经网络
keras 其实是一个构建神经网络比较方便的函数库,其底层计算可以放到 tensorflow 之中:
from keras.layers import Input, Dense, Conv1D
net = Input(shape=(1000,1))
net = Conv1D(kernel_size=3,filters=1,padding="same")(net)
net=Activation("relu")(net)
当然本章以天 tensorflow 为主,所以这里keras仅供了解。其实现起来比 tensorflow 相对简单。
循环神经网络
循环神经网络构建起来相对于前馈神经网络来说比较麻烦,当然最麻烦的是其训练过程。
前面说到全链接网络的过程为:

而循环神经网络与上一步的输入相关,其实只是乘以了一个上一步的矩阵:
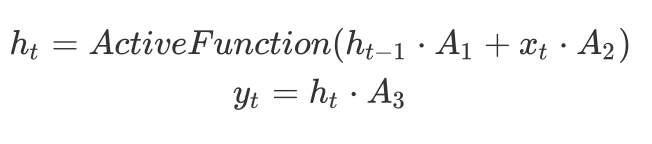
这就是一个最简单的循环神经网络,在此之上可以构建多层的神经网络,定义
y_t
与
x_t
之间的关系为:
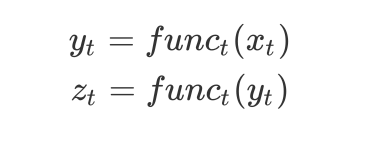
这是构建的多层的循环神经网络。其他的循环神经网络结构是在其上进行的修改。只是参数更多,比如 LSTM。LSTM 输入中加入了一个C矩阵用于保存记忆。
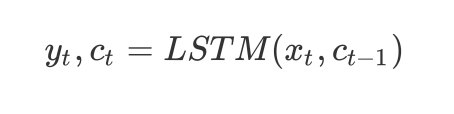
tensorflow 构建循环神经网络
上面说到一个循环神经网络的层可以通过如下的函数构建:
cell = tf.contrib.rnn.BasicLSTMCell(
hidden_size, forget_bias=0.0, state_is_tuple=True,
reuse=not is_training)
多层卷积神经网络构建:
cell = tf.contrib.rnn.MultiRNNCell(
[cell for _ in range(num_layers)], state_is_tuple=True)
前面说到循环神经网络的数据输入是一步一步输入的,因此这里在进行数据输入的过程中也需要一步一步的进行数据的输入:
for time_step in range(num_steps): if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
这里有两个地方需要解释,第一个是 reuse 的问题,因为在第0步之后的变量与前面的变量都是复用的,因此这里需要将其改变为复用模式。
第二个是 state,这个 state 是 LSTM 神经网络结构所特有的,其目的在于保存“记忆”,而记忆量的多少则随着神经网络任务变化而自适应的变化,因此称之为“长短记忆”,这时 cell_output 作为输出就可以用于后续处理了。
可以看到RNN的构建过程相比于前馈神经网络而言是比较复杂的,这其中最关键的是因为其输入是“一步一步”的进行输入的。
神经网络参数选取
这一节内容的话就比较多了,而且有很多“玄学”的感觉,因为参数的选取都带有一定的主观的因素。
自由参数数量与过拟合问题
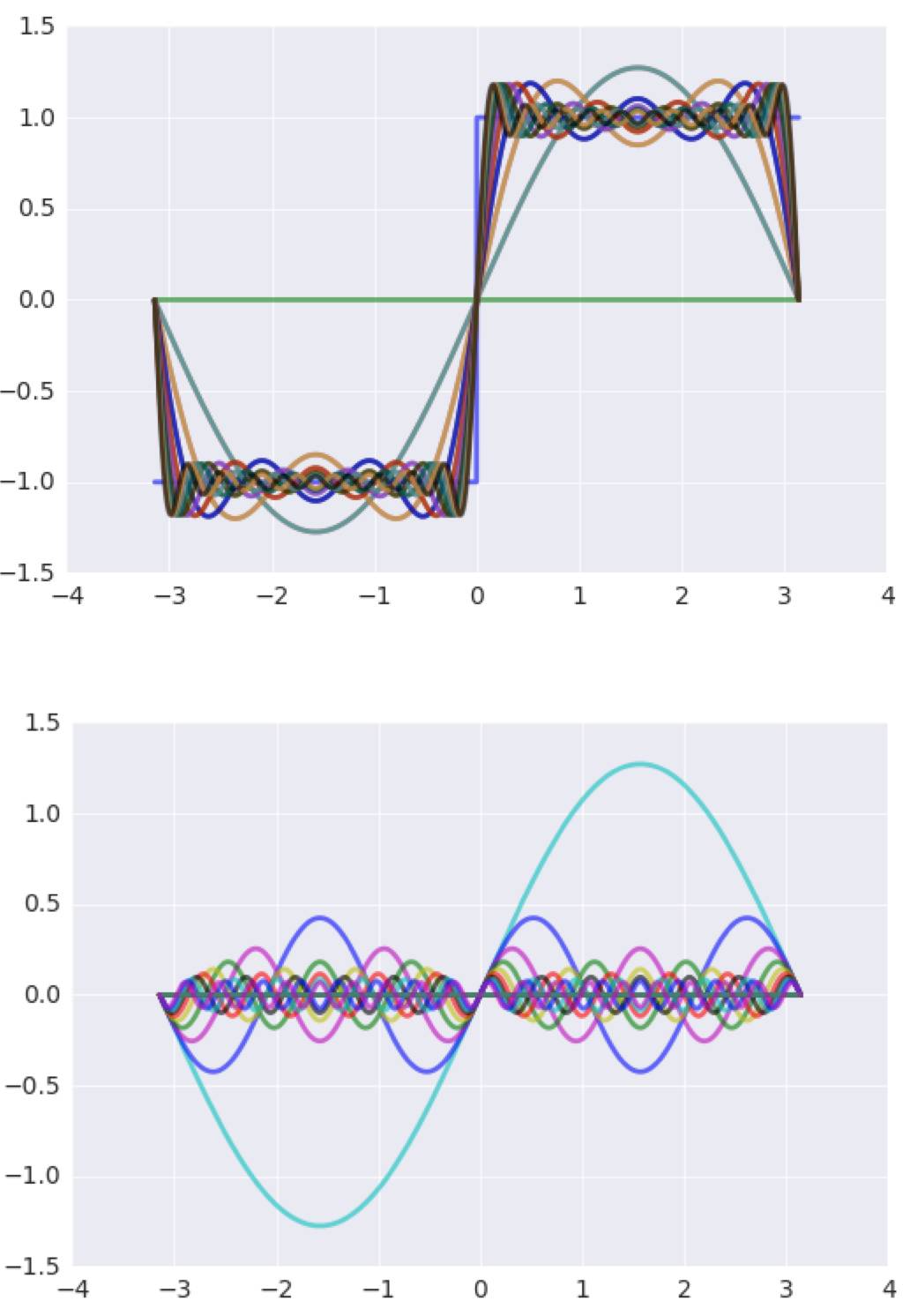
第一个问题就是参数数量,参数数量的增多会引起一个较大的问题就是过拟合问题,用曲线拟合的方式来了解:
import tensorflow as tfimport numpy as N = 6x = tf.placeholder(dtype=tf.float32,shape=[1,None])
y = tf.placeholder(dtype=tf.float32,shape=[1
,None])
comp = []for itr in range(N):
comp.append(tf.pow(x, itr))
x_v = tf.concat(comp,axis=0)A = tf.Variable(tf.zeros([1, N]))
y_new = tf.matmul(A, x_v)loss = tf.reduce_sum(tf.square(y-y_new))train_step = tf.train.GradientDescentOptimizer(0.0005).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())for itr in range(90000):
sess.run(train_step,
feed_dict={x:np.array([[-1, 0, 0.5773502691896258, 1, 1.5, 2]]),
y:np.array([[0, 0, -0.3849, 0, 1.875, 4]])})
print(sess.run(A.value()))import matplotlib.pyplot as pltimport matplotlib as mpl
mpl.style.use('seaborn-darkgrid')
lin = np.array([np.linspace(-1, 2, 100)])
ly =sess.run(y_new, feed_dict={x: lin})
plt.plot(lin[0], ly[0])
plt.scatter([-1, 0, 0.5773502691896258, 1, 1.5, 2],
[0, 0, -0.3849, 0, 1.875, 4])
plt.show()
来看下输出图形:
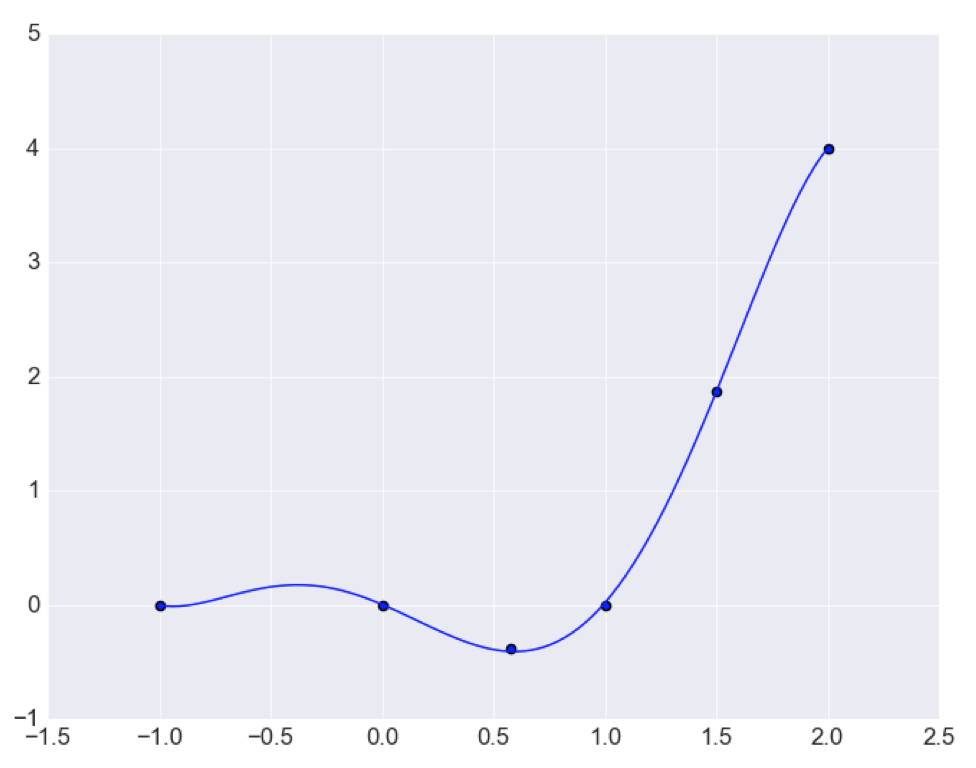
可以看到曲线完美的通过了每一个点,但是这种情况可能并非是一个“好”的结果,因为其对于训练数据拟合过于好了,对于训练集以外的数据可能预测效果并不理想。将函数取值范围从-5到5再来绘制图形:
import matplotlib.pyplot as pltimport matplotlib as mpl
mpl.style.use('seaborn-darkgrid')
lin = np.array([np.linspace(-5, 5, 100)])
ly =sess.run(y_new, feed_dict={x: lin})
plt.plot(lin[0], ly[0])
plt.scatter([-1, 0, 0.5773502691896258, 1, 1.5, 2],
[0, 0, -0.3849, 0, 1.875, 4])
plt.show()
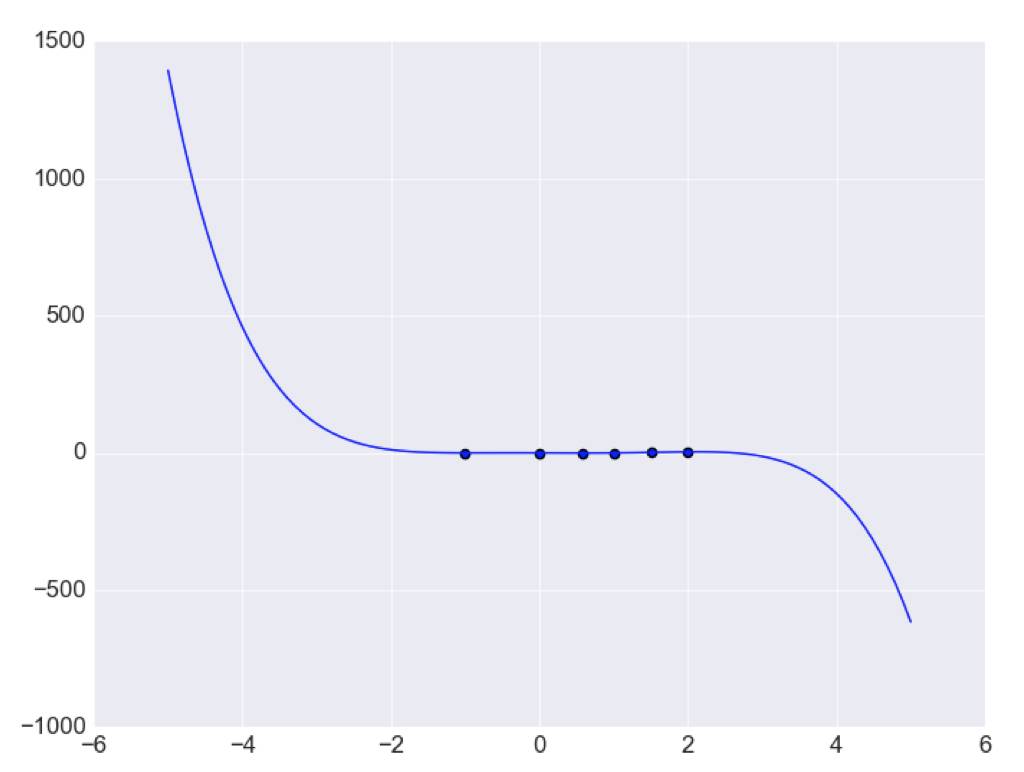
在训练数据之外曲线变形比较大,这会影响对于曲线的拟合效果。另一方面来说也就是对于数据的预测效果不理想。在这里如果减少参数数量:
N=3
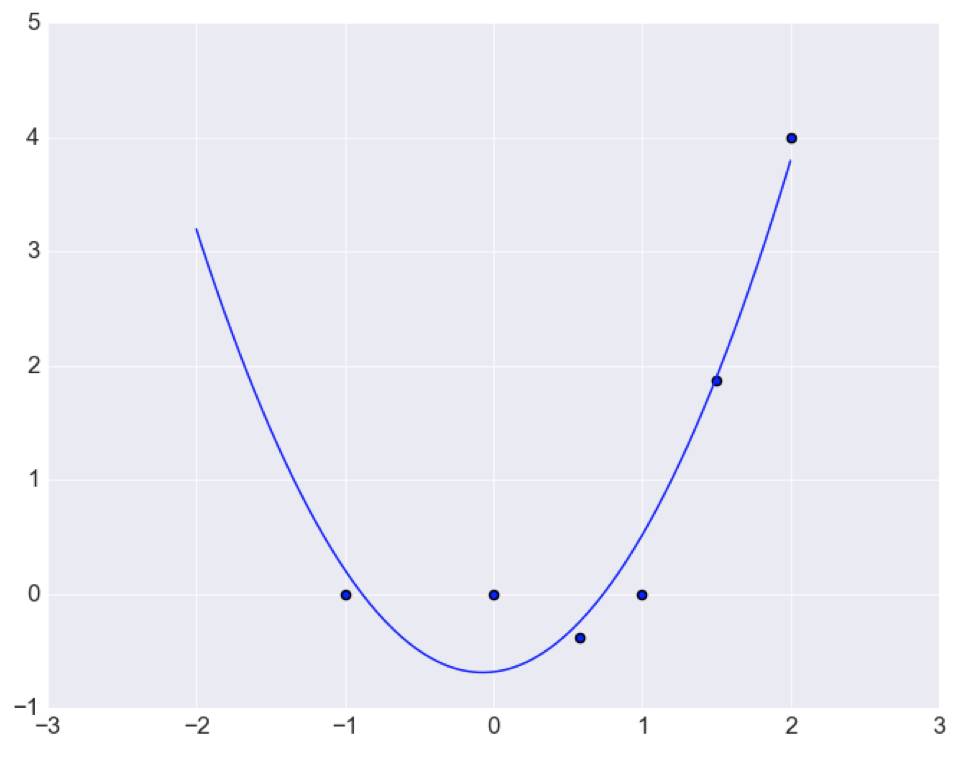
此时可能并未通过每一个点,但是所用的自由参数个数只有三个,但是对于可能的数据分布形式:
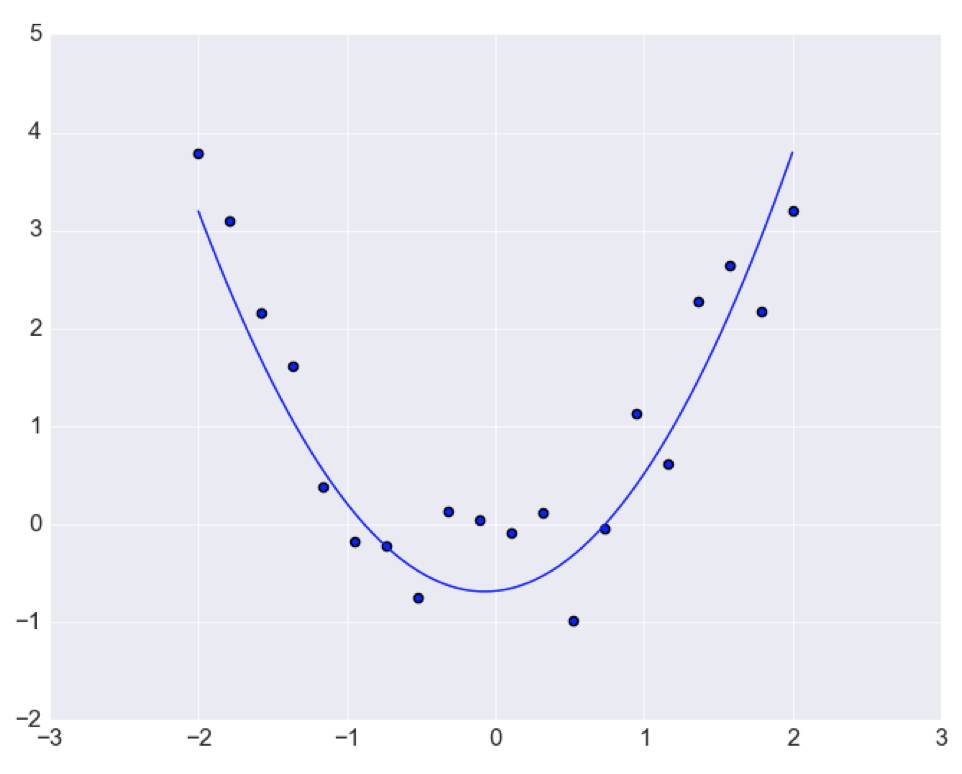
现在用‘二次曲线’可以对数据进行更好的预测,因此
解决过拟合问题最根本的问题就是增加训练集数量
。
BATCHSIZE
这个是一次输入多少数据用于训练的问题,下面的梯度方向是基于二维曲面拟合的 LMS 方法所言的,可以看到:
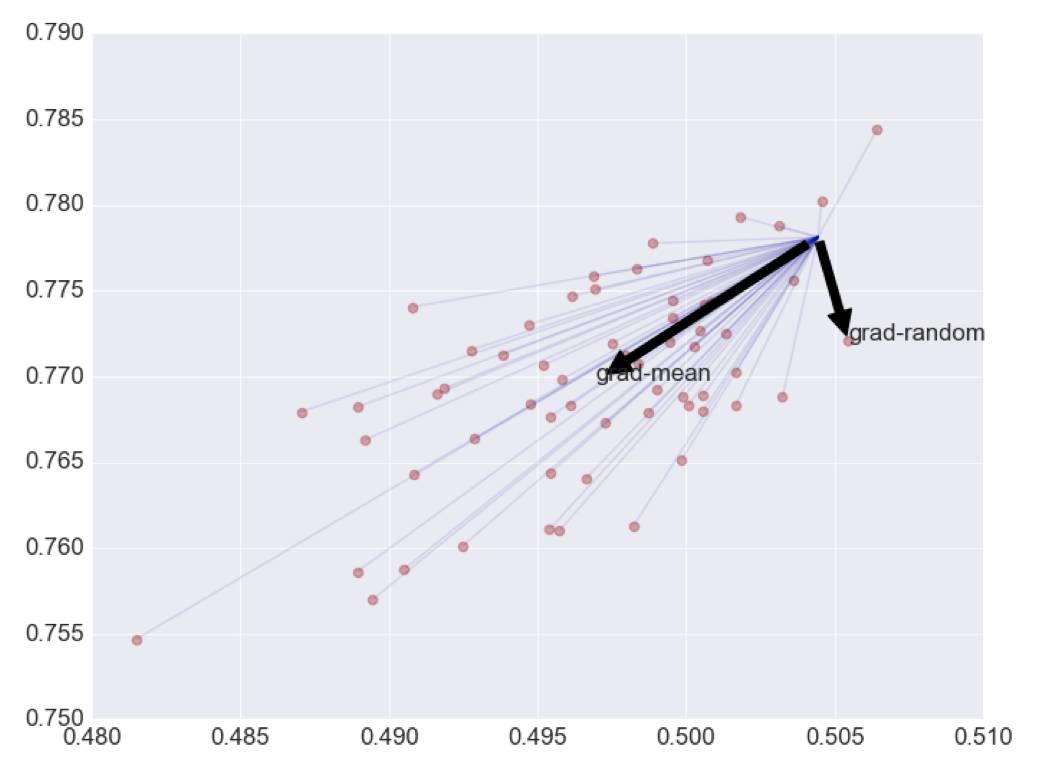
随机梯度带有一定的随机性,虽然按照概率角度来说是可以收敛的,但是显然通过60个数据进行梯度的估计所带来的方向预测更加准确,因此 BATCHSIZE 存在的一个意义就是进行更好的梯度方向的预测。
当然如果用整个训练集来估计梯度方向的话是更好的。但是这里面临一个效率和内存的问题。
这里用17层 Inception 网络来做个表格,实验机器就是E3非 GPU 版本:
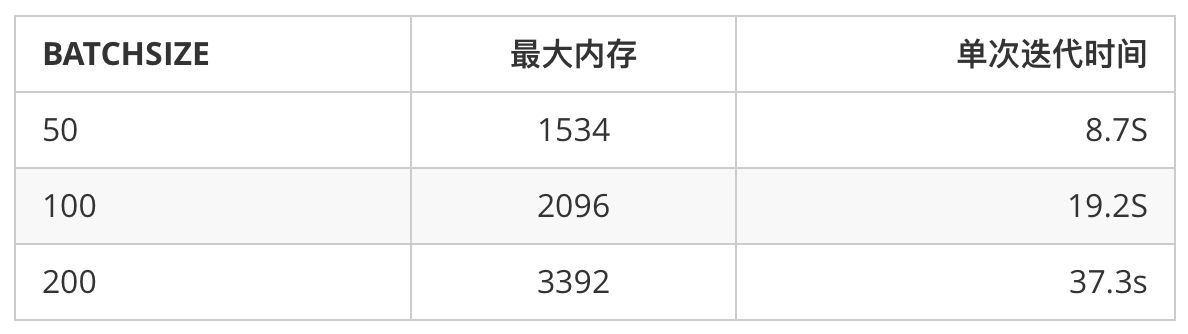
梯度参数我想这个表格已经能说明问题了,虽然可以更好的估计梯度方向,但是计算时间和内存的消耗是呈线性增长的。
梯度参数
梯度参数的选取总的来说对于迭代的影响是比大的,过大的梯度参数会使得迭代发散:
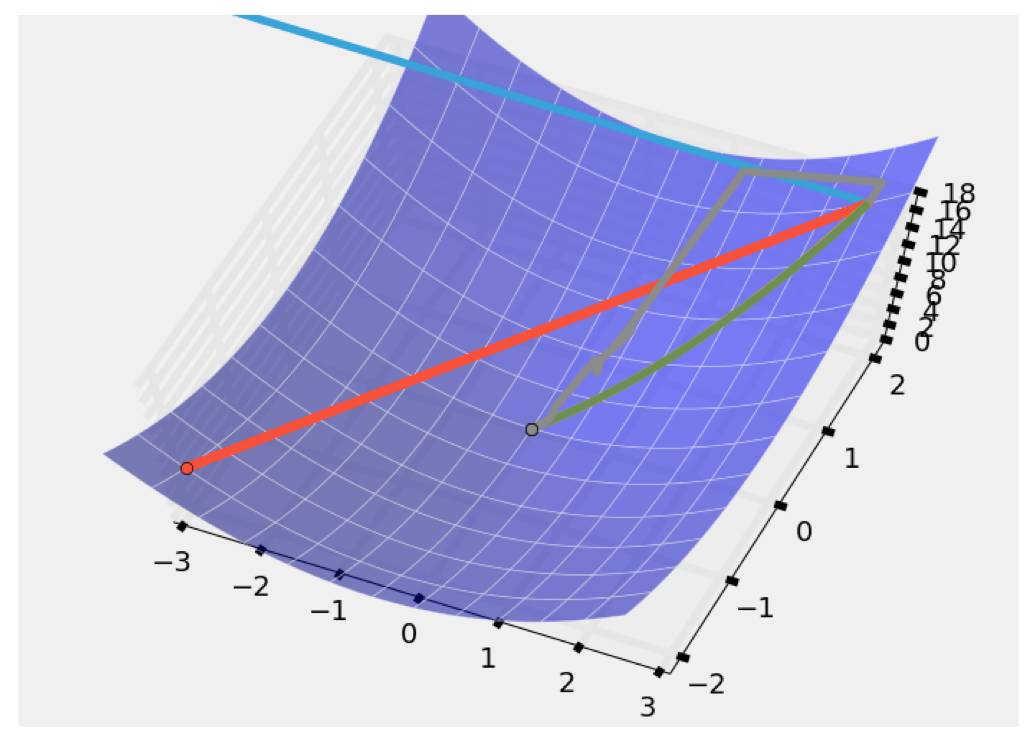
那个蓝线,在计算过程中不仅没有逐渐减少反而越来越大,想理解发散过程比较简单:
train_step = tf.train.GradientDescentOptimizer(500).minimize(loss)
把曲线拟合的梯度参数选为500,我这里选择的是0.5来观察 loss 函数:

这个发散是呈指数增加的,很快就超出机器的数值边界。
比较大的梯度参数可以参考上面那个图的红线,在两个点之间不停震荡。而过小的梯度参数会使得收敛缓慢。比如狠心一些将梯度参数选为
tf.train.GradientDescentOptimizer(5e-15)
这时:
收敛过程变得极为缓慢,或者说基本没有变化。
理智的做法梯度步长随着迭代不断的减少。
BATCHNORM 层
前面说过 BP 算法中一个过程就是乘以矩阵:
有兴趣参考文章
(
https://zhuanlan.zhihu.com/p/26352342
)
但随着层数增多所乘的矩阵也在不断的增多,那么就会遇到梯度消失的问题,就像鸡汤说的每天忘记百分之一,一百天后就剩下37%了,这是一个指数的问题,BP 算法也是如此,因此引入了 BATCHNORM 层,以解决上述问题。 tensorflow 中有相应的代码:
tf.contrib.layers.batch_norm
形象化
一般在讨论纯理论问题的时候很多人都有个很不好的习惯就是找一个物理映射,这种物理映射可以帮助理解问题,但是可能会在之后的学习中并不如直接的数学理解更有帮助。
那么再来看下整个的循环神经网络的结构:
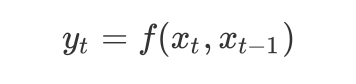
或者
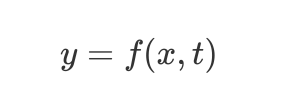
这种形式的问题在包含乘法操作的情况下称之为非线性问题。可能用一个比较广为人知的词就是混沌,RNN 和 CNN 网络均可以对混沌吸引子进行重建。
下面这个是一个典型的混沌吸引子:
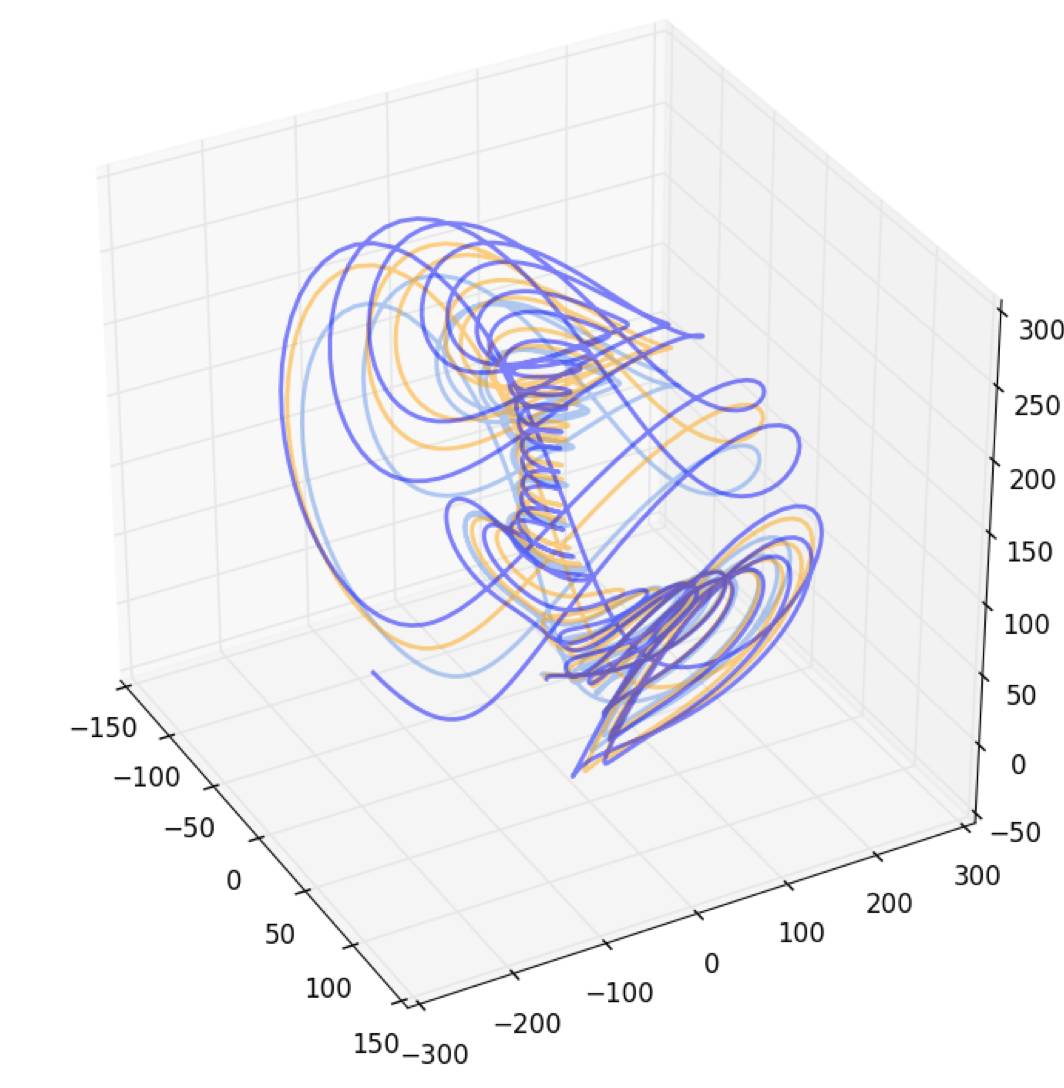
方程描述:
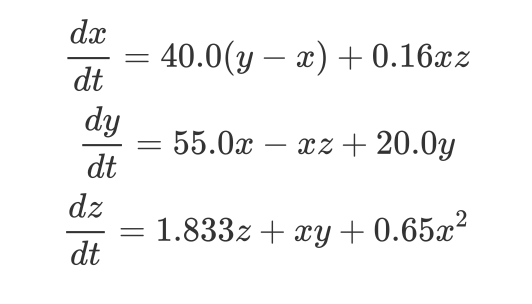
那么数值求解上述方程的过程实际上就是类似于 RNN 的过程。
那么三体运动方程实际上也是一个非线性方程的问题,并且三体运动并非是完全不可预测的。
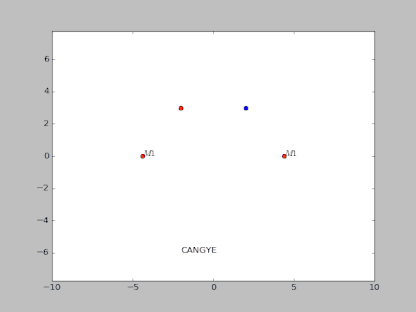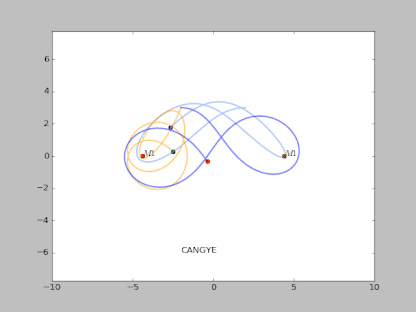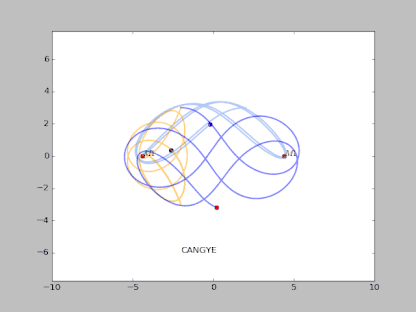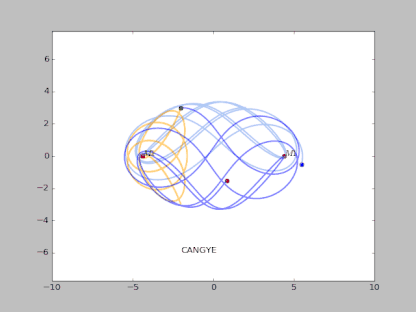
很多时候其表现出概率的特征,这是可以通过统计分析得到的。
有兴趣的,可以参考数值模拟过程用神经网络重建吸引子。
近期热文
《
当我说要做大数据工程师时他们都笑我,直到三个月后……
》
《
当年校招时,我就死在了这个问题上...
》
《
如何成为一个 IT 界的女装大佬?
》
《
技术学到多厉害,才能顺利进入BAT?
》
《
细化到每一步操作的 Jenkins + Django 完整实战
》
彩蛋

「
阅读原文
」了解更多知识





