正文

-本文摘自杨强教授在【Fintech x AI 高端研习班】上的分享 -
“我讲AlphaGo的时候本着两个目的,第一是给大家科普,让大家了解它的机制;第二是给大家泼冷水,告诉你们AlphaGo的成功其实非常难复制”
AlphaGo为我们带来了什么?
人工智能的成功应用主要在以下方面,而非所有:
第一个是语音,语音已经有很多年的历史了,但是引入深度学习以后,尤其近几年有了突破性的发展;第二是图像识别,比如人脸识别;第三是电商/推荐,像淘宝、京东这样的电商/推荐;第四是博弈,最典型的就是AlphaGo;第五是更深层次的对抗网络,基于博弈的思想,这个的应用就很多了,其中最引人瞩目的就是无人车。
人工智能第一次受到关注是97年的深蓝,当时是象棋领域战胜了世界冠军。象棋本来就是非常难的领域,我们展开一个棋盘,所有可能的布局总数大概是10的47次方,这是非常庞大的数字;但在用了IBM高性能计算以后有了显著的发展。
所以这一次应该说是几个事件的成功:第一个是高性能的计算,第二个运用了群体智能,让很多二流的国际象棋专家对这些节点进行评估,最后把他们的分数加以总结来战胜一个世界冠军,一共用了两百多个二流的人,它和今天的AlphaGo相比,最大的弱点就是没有机器学习的能力。
五年前人工智能领域出现了一个新名词,叫做“深度学习”。我们知道深度学习首先在图像上有比较直观的解释,我们输入一个图像,可以在图像上采集一些样本,这些样本会为我们带来一些特征。这些特征包括比较低级的一个个像素,像素上面所带的信息、颜色、亮度,我们可以将这些特征总结起来。
DeepMind是AlphaGo背后的团队,将“深度学习”与“强化学习”结合起来,把围棋的棋盘当作输入,另一端输出动作,需要往左还是往右,需要把棋子放在哪儿等等,就是需要一个深度学习网络实现这种对应,这些都是计算机可以自学的。
但是大家看出这个问题的弱点了吗?
围棋的情景和我们实际生活差距相当大,因为这是一个非常理想的世界,我们的规则非常清楚,边界也非常清楚,输赢会立马反映在上面,动作简单,一点不含糊。所以在这种封闭的领域、清楚的领域,优化目标可以写下来的领域,AlphaGo的算法是完全没有问题的。
AlphaGo里面有两个函数我要特别提一下,一个叫做“策略网络”,所谓“策略网络”就是告诉你在这里应该怎么走。策略网络中的“S”就是我们所说的状态,“A”是我们说的“Action”,“P”则是概率的意思,整体来说是“在这个状态下对方大概会走哪一步”,让你对对方有一个了解。我们如何进行训练呢?拿了三千万个比赛的棋盘来训练,看如果从这个状态出发,高手一般走哪一步,我们就可以学习下来。
其实无人车也是用这种方法,让它先在封闭的环境里学驾驶,学会了再出去开。特斯拉的意外就是一个反例,在特斯拉这个例子中,机器给车前面照了个相,判断前方是空的,系统就会反馈说前方的状态是有利的,可以往前走;如果前面是一堵墙,打分就会较低,系统会判断没有利。特斯拉就是出了一个错,系统判断前面是空旷的,以为是白色的白云,但实际上是白色的卡车,因此就撞上了,这就是因为训练不足。
第二个值得一提的算法,在AlphaGo去年的比赛里,因为计算能力有限,对每一个状态,即每一个“S”的估计还不够好,就加了一个新的算法叫做蒙特卡罗算法。 就是我在现有状态下让机器随机走棋,最后是输是赢给我一个反馈。
像这样快速走棋了N次之后,可以拿这些样本做一个抽样,这样就能很快告诉我这么走对我是好还是坏。这个会迅速得出结果,但是会非常不准,因为毕竟是在无限当中进行有限的抽样,所以去年AlphaGo还有一盘棋是输给李世石的。
到了今年大家知道master是60局全胜,这个月23日在乌镇和柯洁的比赛,我们做人工智能的觉得人类就没什么戏了。为什么呢?因为现在我们把这种随机过程全部替代掉了,所有训练都是通过强化学习来实现的,机器犯错的概率就大大降低了,据说现在的AlphaGo给去年的自己让四个子还能赢。
我们能从AlphaGo的成功中学到什么?
人工智能在AlphaGo上的应用显然成功了,那么像在教育领域、医疗领域是否能复制这种成功?我觉得是非常难的。
人工智能的成功首先得有高质量的大数据。AlphaGo是学习了三千万个棋盘,十多万个棋局,这些都是当时训练时使用的数据,那个时候还没有跟李世石对弈的实时数据做训练,因此前期收集的数据是非常关键的。
除此之外,如果前期用质量不太高的数据,比方说围棋一段以下的数据来计算,那样训练出来的效果是非常差的,所以对数据质量要求非常高。
还需要有明确的问题,也就是我们的“A(Action)”,在围棋中只有下棋、放子这样的动作,没有任何其它的东西,不像投资这么复杂。
另外还要有很好的获取特征的方式。比如说棋盘,要有专家参与进来,把每一个棋子周边的情况用所谓的“变量”表达出来,这些变量我们叫做特征。能产生这些变量需要专家,就像AlphaGo团队里的工程师基本都会下围棋。
以上我讲AlphaGo的时候本着两个目的,第一个给大家科普,告诉大家它在做什么,让大家了解它的机制;第二是给大家泼冷水,告诉你们AlphaGo的成功实际上非常难复制。
有记者常咱们中国媒体人,说AlphaGo意味着什么?我们这边说意味着人类要没有工作了,人类不需要存在了;再问AlphaGo的团队这些成功意味着什么?他们会答意味着计算机也会下围棋了,所以他们是很低调的。
我觉得这个题目是值得大家总结的,尤其是现在人工智能膨胀的过程中,大家一定要保持清醒的头脑。
“我们知道吴恩达刚刚离开,很大的原因是拿不到数据资源、业务资源,这种人又有抱负,当然会选择离开,那么我们该如何管理这个事?”
我们要建立一个机器学习模型,首先得有一个目标。这里面分成两类,一类是商业目标,人工智能虽然可以用这么多的方面,流程自动化、客服等等,但一定要明确最终目标是什么,是要倍增收益,把地盘扩大,还是要把最后的费用减少。
第二,知道要增加收益或减少费用后,你需要把它量化成数学公式,我们往往管这个叫做优化函数。比方说哪些任务可以用自动化带来价值,完成这个自动化过程本身需要费用,这个费用是不是值得花?这是需要顾及的。
第二个是否要引入第三方外援?不是每个人都要从头开始做AI,要想从最底层的数据、网络、工具、应用,云全部完成,这个恐怕也只有BAT可以做,但我们没必要每一个公司、每一个team都做这些事;还有一个人工智能系统往往需要持续支撑,这个支撑往往很昂贵,我们是否能承担的起,要评估自己的人力资源、资金、数据是不是够用。
第三,咨询业务方和数据拥有方。我在华为、腾讯都做过,知道很多大公司都有部门墙,部门之间几乎是不沟通的,因此这个数据往往是以孤岛的形式存在的。而今天的人工智能,尤其深度学习、强化学习,这两大工具都非常依赖于数据。即使我们购买了数据,如何清洗和整合数据又是第二个问题,数据结构化的过程是非常昂贵的,往往需要很多人工。
第四个就是AI团队建设。如果我们有AI团队,这个团队和业务团队是不能分开的,它一定要有明确的责任,要有一个技术接口人、管理人员、数据的责任人、系统整合的责任人,都要非常明确,要有一个完整的KPI。
我们拿百度举例,我们知道吴恩达刚刚离开,很大的原因是拿不到数据资源、业务资源,这种人又有抱负,当然会选择离开,那么我们该如何管理这个事?我们要从一开始就明确这个团队的目标是什么,也就是KPI。
第五点,AI的项目需要各种各样的规划,和一般的软件没有区别,我觉得把AI和其他软件工程区分开始错误的。
深度学习
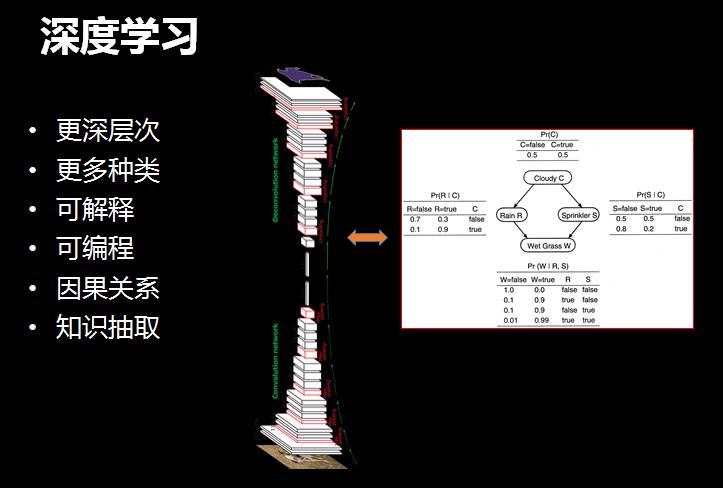
深度学习特别要命的一点,就是它的结构是一个黑箱。经过几千万个样本训练以后,完全没有办法解释。什么叫做“解释”呢?一旦有错我可以知道是哪里出了错,应该调整哪个地方,但我无从得知。
所以AlphaGo就出了这样一件事,当时4:1输给李世石关键一步,它想知道哪一个地方出了问题,因为这肯定是深度学习在估算棋盘时出了一个严重错误,但没有办法回溯,如果当时再比赛一次还会出现同样的错误,因为没有办法纠正。
那么什么叫做“白箱”,什么叫做“可解释的模型”呢?因果关系的模型就是可解释的,比如医生知道给病人吃了这个药后病人有多大机率会康复,这就是因果关系。因果关系的流派在人工智能领域确实存在,叫做贝叶斯流派,但目前没有特别靠谱的自动学习的算法。
目前在很多领域,如果一个模型给出了结论,但不知道为什么会给出这个结论,往往该领域是不会允许你使用这个模型的,因此“因果关系”非常重要。所以“深度学习”领域需要有更多种类、需要是可解释的、可编程的。
第二个是我们所说的迁移学习。所谓“迁移学习”就是给出一个已经训练好的领域模型,这个模型可能对应一个神经网络,那么我们能不能从中抽象出比较高层的逻辑知识,如果有了这个知识,就可以比较容易地把高层知识逻辑迁移到新的领域。
比方说“舆情”,比方说我们在微博上可以看一些人的评论和留言,我们知道这些留言是正面还是负面的,对于新出的电影或者一个事件就有正面、负面的判断。
我们如果在这个领域训练出了模型,能不能迁移到一个新的领域,比如对图书、股票、股价、公司也做这种预测?所以这种迁移是很有用的。迁移的目的就是我们不用做很多的标注、不用花费很多建模费用,就可以把已有模型迁移到新的领域。
还有一种学习叫做表示学习,在自然语言处理的领域也经历了革命性的转化。现在机器通过大量文本学习一个新的“表达”,可以判断这个词出现的场景、它和周边的字是什么关系——我们建立起一个字及其周边常见字的“朋友圈”,通过学习来发现同义词,而不是通过人来告诉机器。
这个表达学习的过程叫做“机器阅读”,把每一个词中字的“朋友圈”都表达出来,比如说贾宝玉和谁最好,机器模型可以自动回答,而且非常准。我们有了机器阅读,就可以产生一个新的表达,比如说可以做一个《红楼梦》的摘要。
然后我们说Echo学习系统的一问一答,现在可以做得很准,其一就是因为Echo有一个很强的硬件系统,可以被智能唤醒,知道这个是在对着它讲话还是在对着别人;然后将软硬件相结合,把软件的优点发挥出来。
另一点就是Echo的使用场景非常清楚,它的目标是一个有限的垂直领域,而不是一上来就做一个通用的对话系统,这也是我们需要借鉴的。
我再说一下人工智能未来的几个方向,在基础计算结构有两方面,一方面是芯片的研究,像英伟达做的GPU,谷歌做的TPU,虽然不知道什么时候商业化,但据说是非常牛的人工智能芯片。另外一个,过去我们在网络的传输层还没有特别适合深度学习的网络研究,现在有了,如果在网络层做优化就能把深度学习加速到四五倍这样的水平,这将是网络传输层的革命。
最后做一个总结,深度学习可以做很多研究——强化学习可以和迁移学习相结合做很多个性化的任务完成对话,智能规划等等。迁移学习可以帮助完成知识的高层表达、跨领域的知识,还有小数据的学习。还有如何能够进行信息抽取,把自然语言这种非结构化数据表达出来,能够进行自动问答、对话系统,包括摘要的自动建立,算法加速,人工智能的工程化。
进一步了解研习班背景,请戳:金融大佬与顶尖AI专家聚首,他们都谈了些什么? | Fintech x AI 高端研习班后记
后续我们还将持续发布导师分享干货及采访视频,敬请关注“通联数据”官方公众号。
通联数据(DataYes)是由金融和高科技资深专家发起,万向集团投资成立的金融科技公司。致力于将人工智能、大数据、云计算等信息技术和专业的投资理念相结合,打造国际领先的、具有革命意义的金融服务平台。











