
本周二(12月5日),在北京朝阳悠唐皇冠假日酒店召开的2017中国存储峰会上,张广彬和曾智强代表企事录技术服务公司发表了题为《网络存储“相对论》的演讲,分享了最近测试高性能存储和网络的一些实践。以下为演讲实录。
连续好几年在存储峰会的技术论坛上开场,以前讲的都比较概念趋势性一些。今天主要讲的不是概念,而是我们最近在一些新技术上的探索和实践。这一场将会由我和我的同事曾智强共同来完成,我先讲前面的这一部分。

我们企事录服务公司,主要致力于新技术、新产品的市场教育,手段通常是分析和测试。分析方面我和曾智强在几年前写过技术分析报告《
数据中心2013
》,率先提出“硬件重构+软件定义”的理念,并据此展开对前沿技术的解析,这几年行业确实在向着这个方向前进,我们也在这个方向上去践行理念,特别是指导我们的测试工作。这里列出了企事录与几家业内知名企业合作的联合实验室,本次的NVMeoF测试就主要在和青云合作的混合云实验室进行。
这个“相对论”当然只是取一下(爱因斯坦)相对论字面上的意思,网络和存储一定程度上是相对的概念,是可以互相替代的。十多年前听华中科技大学谢长生教授打过一个比喻——信息的传输,可以在空间维度,和时间维度上进行:比如烽火台,把敌人入侵的信号通过烽火台传递到很远的地方,这是在空间维度上的传输;另外一种在时间维度上的传输,比如刻一个碑,几百年甚至几千年以后,这个碑没有损坏,大家还是可以看到记录下来的信息。前者就是网络,后者就是存储,我觉得这个很有启发。

两者结合起来,就是网络存储?当然,我们也可以更抽象的想一想,譬如1968年上映的科幻电影《2001太空漫游》,里面有一个宇宙高智慧结晶的代表,就是黑石,有好事者演算过这个黑石可以存储多少数据,而它还能够自由移动,穿越时空,兼具网络和存储的特性。
十多年前的网络存储,跟现在不一样,专有的存储硬件架构,专有的存储网络(Fibre Channel)。但从使用的角度,通过网络去访问,其实跟访问本地的硬盘,看起来没什么区别。现在我们讲软件定义存储(SDS)和超融合(HCI),软件定义存储的主流是分布式的,在通用服务器上,分布到多个节点来运行,用服务器集群来提供服务。存储和计算分离的场景,两个集群之间的网络显然是可见的,使用和部署的时候可以明显感受到。而超融合,把计算和存储放到了一起,计算看起来访问的是本地存储资源,但实际上也可能是通过网络跨节点访问,它的网络不是很明显,但实际上各个节点之间,也是通过网络才成为一个整体。
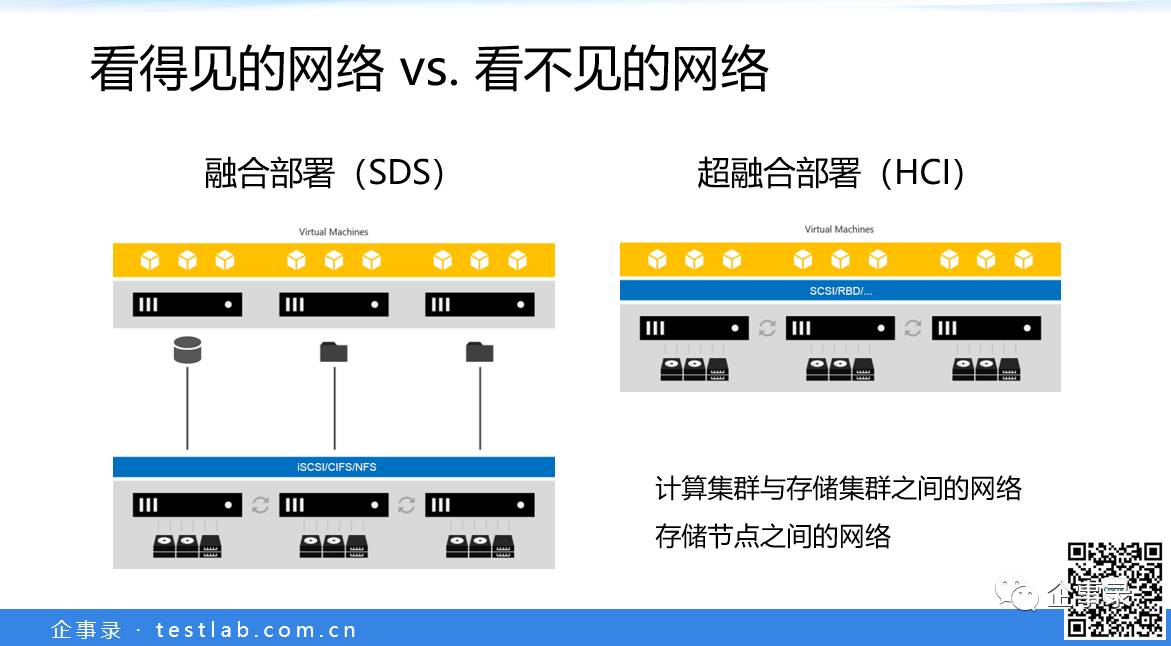
超融合是这几年企业级市场上很火的一个概念,我在去年的存储峰会上也讲过
《超融合架构的“逆流”?》(存储峰会演讲实录)
。超融合当然有很多的优点,最大的优点就是部署简单,这对大型企业,和中小型企业都是适用的。但是,超融合架构更多的适用于中小规模的部署。具体的例子如微软的Azure Stack,微软混合云蓝图中私有云的部分,与Cisco、华为、联想、Dell、HPE的服务器硬件,整合成软硬件一体的解决方案交付。一个集群最少4个节点,最多可以达到12个节点,下一步16个节点,这是典型的超融合部署。
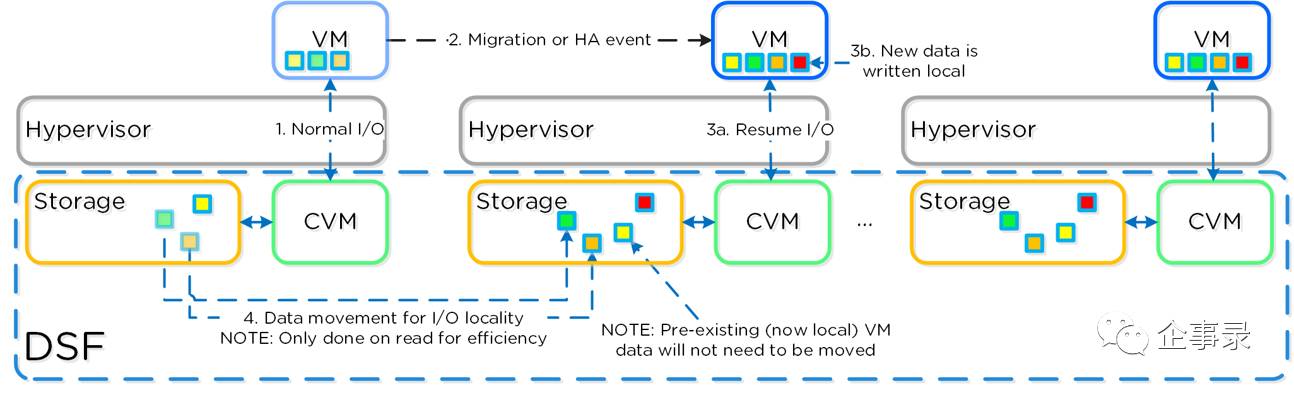
超融合部署的另外一个优势是,利用计算和存储一体的特点,可以把计算节点经常访问的数据,就近放在所在的节点本地,尽量避免跨网络访问。这在网络状况不太好的时候,有很好的效果。如图所示,超融合市场的开创者Nutanix就提供这个功能。
公有云上也有类似的例子,譬如阿里云的第一代块存储是2010年做的,当时阿里云尚处于起步阶段,用的网络还是千兆以太网,就利用超融合的部署方式,来降低网络性能的不利影响。
我们后面也会提到,现在高速的存储,譬如NVMe和3D XPoint这种低延迟存储的出现,存储性能大幅提升以后,网络性能如果跟不上来的话,可以用类似的数据本地化的方法,譬如微软的S2D(Storage Spaces Direct),或者VMware vSAN,都有计划加入数据本地化的功能。
刚才说到阿里云,实际上超融合架构在大型云计算环境下的一个问题,就是计算和存储资源紧耦合的方式不够灵活。譬如阿里云上线了一个集群,可能计算资源很快卖空了,但存储资源还剩很多,那这就是很不经济的一种做法。所以
阿里云从第二代块存储技术开始,就采用了计算和存储分离的方式
,包括到现在的第三代也是采用分离部署的方式。
另一个例子是AWS的EBS。EBS主要为EC2计算实例服务,AWS有很多类型的EC2实例,C开头的是计算优化的实例,前不久推出了最新一代的C5实例。AWS起步比较早,其虚拟化采用的是Xen,但是最新的一代C5转向了KVM。上周的
re:Invent 2017大会
上,AWS为了介绍C5,把以前几代实例的计算和存储架构都大致回顾了一下。
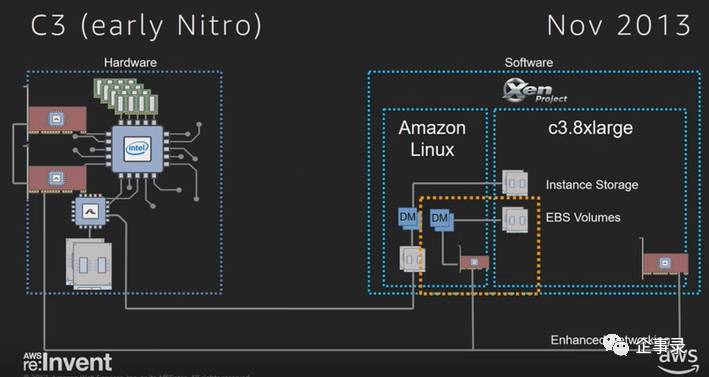
这张是C3实例的架构图,左边是硬件架构,右边是软件架构,画出了对应的映射关系。很多IaaS公有云的实例都有本地存储的选项,本地存储的问题在于,其就在实例(通常是VM)所在的物理主机上,如果云主机重启或迁移,本地存储的数据就会丢失。所以本地存储虽然快,但并不被视为持久化存储。持久化的块存储,于AWS就是EBS(Elastic Block Storage,弹性块存储),黄色的虚线框里就是EBS,是一个共享的存储,通过网络访问。从图上的架构可以看到,存储和网络一样,通过网络来访问。这就可以看到C3实例在存储架构上的问题:存储的流量和网络的流量,没有有效的区隔,所以存储的性能可能无法保证。
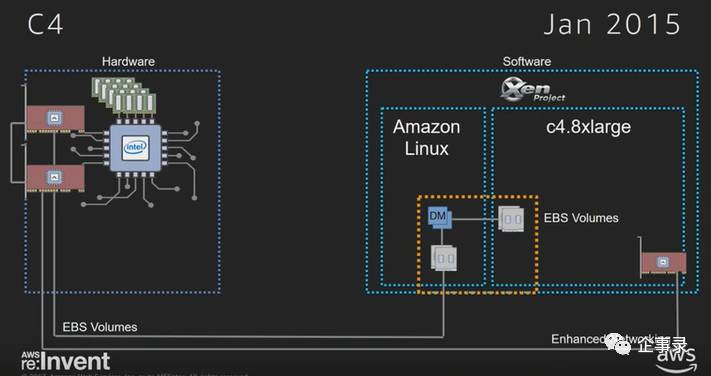
从2013年底到2015年初,过了一年多,AWS升级到了C4实例。黄色虚线框里还是EBS,注意存储的访问路径,已经和网络区隔开了,所以C4实例的EBS存储,性能和QoS有保证。这也说明了网络和存储的一些联系:有时候存储的变化,实际上是网络的变化。
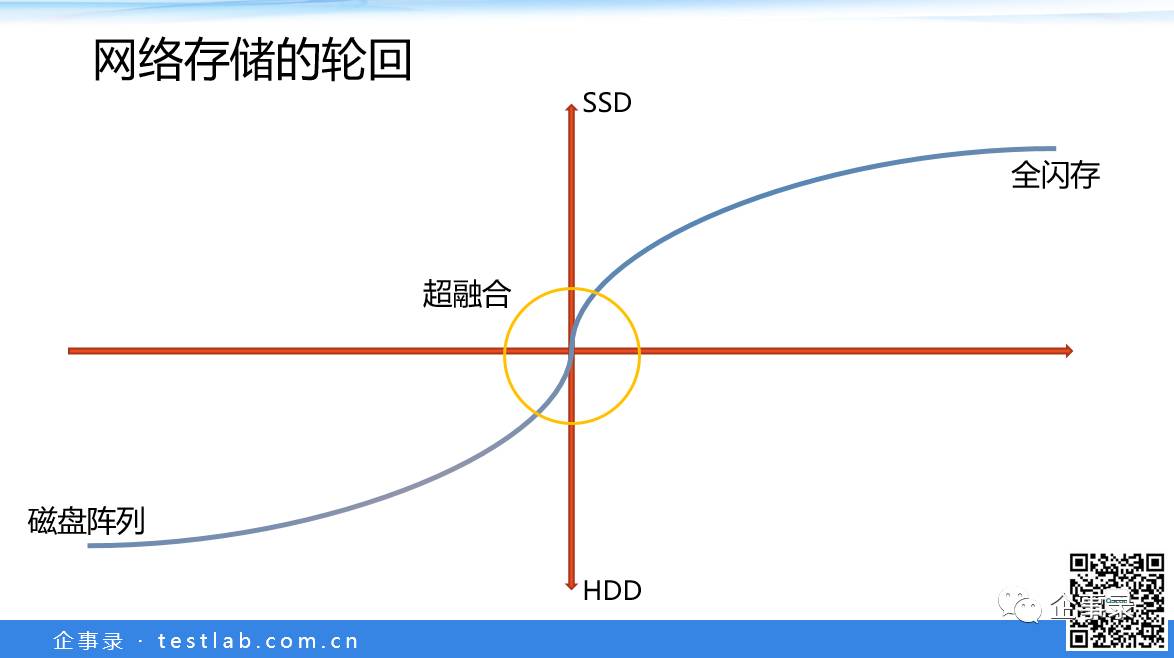
这是我画的一个图,横轴是时间线,纵轴是SSD或HDD(硬盘)的大致数量。可以看到这是一个发展的曲线,左下角的是已经发生的事情。我们原来为什么会有磁盘阵列?因为硬盘性能太差了,所以要把很多硬盘堆在一起,形成磁盘阵列提供更高的性能(有时是更大的容量)。随着SSD的逐渐发展,刚开始用SSD给硬盘当缓存,使用服务器内置存储,SSD加HDD组成缓存或分层的方案,还可以是纯SSD(全闪存),就可以满足应用的需求。
由于SSD的加入提高了存储的性能,服务器本地的存储就能满足所承载应用的存储性能需求,所以我们可以做成超融合的方案。这个黄色的圆圈的意思是,前几年到未来几年的这个时间区域内,服务器内置存储可以用超融合的方案,一个服务器有10几20几个硬盘或SSD(SSD+HDD或者全闪)。
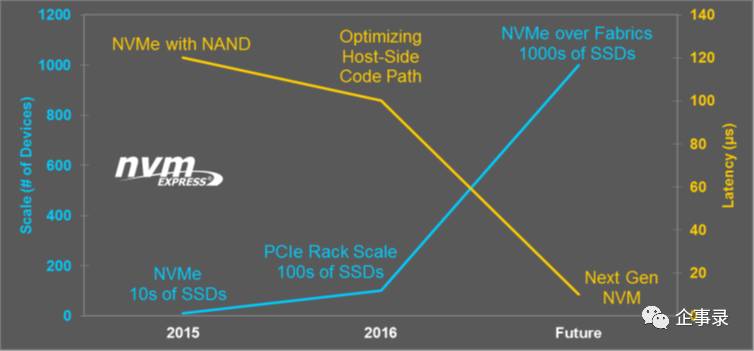
但是,随着NVMe SSD逐渐普及,以及服务器本身能支持的SSD数量进一步增加,可能又会往另外一个方向变化:一台服务器装满了SSD以后,本地的计算能力(运行的应用负载)已经不能完全发挥SSD的全部性能,所以又要把SSD放到单独设备里面,把存储独立出来,供很多主机访问,还有更高的灵活性。所以往右上角发展,比如说几百片闪存放在一起,甚至将来有可能会上千个闪存放在一起。就像这张NVMe over Fabrics(NVMeoF)规划的远景,将来可以支持千个级别的SSD。NVMe over Fabrics现在已经走向了一些原型阶段,或者是有一些产品出来了。
NVMe over Fabrics要解决的是,计算和存储分离了以后,距离没有产生美,带来的却是带宽和延迟上的挑战。怎么解决这个挑战,接下来的这一部分,有请我们企事录负责测试的合伙人曾智强来讲一讲这方面的情况。
大家好,我是曾智强,我在企事录主要负责(新)技术、产品及解决方案的评估和验证。闪存的出现,确实加大了对存储网络的挑战。业内已经开始着手解决网络的问题,比如NVMe over Fabrics,我们也对NVMeoF做了一些探索和尝试,取得一些成果,今天就给大家分享一下企事录在NVMe over Fabrics方面获得的一些实践经验。






