
Google TPU让“
脉动阵列
”(systolic array)这项“古老”的技术又回到大家的视野当中。短短几天,各种争论不绝于耳。其中有一个评论我比较喜欢,“
这次google tpu让像我这样的年轻后辈又有机会能重新认识systolic,也很有意思
”。是啊,还是让我们静下心来,重新认识一下“脉动阵列”这位老朋友吧。

Why systolic architectures?
要真正理解脉动阵列,首先要问的就是发明者的初衷。这正好也是1982年H. T. Kung论文的题目[1]。
对于为什么要设计这样的架构,作者给出了三个理由:
1. Simple and regular design
:可以说,
简单和规则
是脉动阵列的一个重要原则。而这样的设计主要是从“成本”的角度来考虑问题的。“
Cost-effectiveness has always been a chief concern in designing special-purpose systems; their cost must be low enough to justify their limited applicability
.
”换言之,由于一个专用系统往往是功能有限的,因此它的成本必须足够低才能克服这一劣势。这也是设计专用处理器的一个基本考虑。更进一步,作者把成本分成两部分:nonrecurring cost(设计 design) 和recurring cost(器件 parts)。器件成本对于专用设计和通用设计基本是一样的,因此决定性的是设计成本。而设计一个合理的架构(appropriate architectures)是降低设计成本的一个重要方法。Google的TPU可以说很好的证明了这一点。通过采用脉动阵列这个简单而规则的硬件架构,Google在很短的时间内完成了芯片的设计和实现。从另一个角度来说,硬件设计相对简单,尽量发挥软件的能力,也是非常适合Google的一种策略。
2. Concurrency and communication
:这一点主要强调并行性和通信的重要。由于这方面大家应该比较熟悉,这里不再赘述。
3. Balancing computation with I/O
:平衡运算和I/O,应该说是脉动阵列最重要的设计目标。对于这一点,作者用下面这幅图给出了很好的说明。
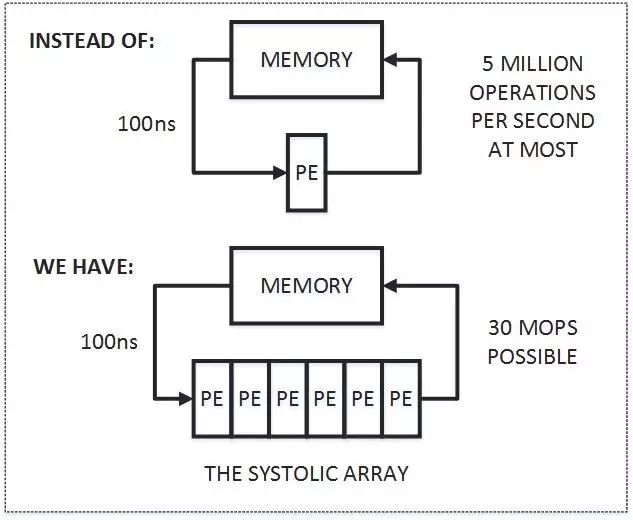
首先,图中上半部分是传统的计算系统的模型。一个处理单元(PE)从存储器(memory)读取数据,进行处理,然后再写回到存储器。这个系统的最大问题是:
数据存取的速度往往大大低于数据处理的速度
。因此,整个系统的处理能力(MOPS,每秒完成的操作)很大程度受限于访存的能力。这个问题也是多年来计算机体系结构研究的重要课题之一,可以说是推动处理器和存储器设计的一大动力。而脉动架构用了一个很简单的方法:
让数据尽量在处理单元中多流动一会儿
。
正如上图的下半部分所描述的,第一个数据首先进入第一个PE,经过处理以后被传递到下一个PE,同时第二个数据进入第一个PE。以此类推,当第一个数据到达最后一个PE,它已经被处理了多次。所以,脉动架构实际上是多次重用了输入数据。因此,它可以在
消耗较小的memory带宽的情况下实现较高的运算吞吐率
。
当然,脉动架构还有其它一些好处,比如模块化的设计容易扩展,简单和规则的数据和控制流程,使用简单并且均匀的单元(cell),避免了全局广播和扇入(fan-in),以及快速的响应时间(可能?)等等。
总结起来,脉动架构有几个特征:1. 由多个同构的PE构成,可以是一维或二维,串行、阵列或树的结构(现在我们看到的更多的是阵列形式);2. PE功能相对简单,系统通过实现大量PE并行来提高运算的效率;3. PE只能向相邻的PE发送数据(在一些二维结构中,也可能有对角线方向的数据通道)。数据采用流水线的方式向“下游”流动,直到流出最后的PE。
到这里不难看出,脉动架构是一种很特殊的设计,结构简单,实现成本低。但它灵活性较差,只适合特定运算。而作者认为,卷积运算是展示脉动架构特点的理想应用,因此在文章中用了很大篇幅介绍了脉动架构实现卷积运算的方法。
首先看看作者对卷积运算的定义:
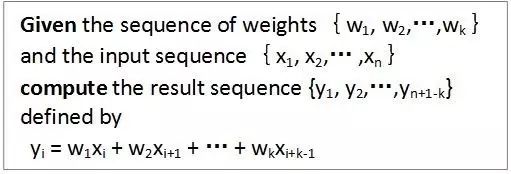
下面是作者给出的一种方法
(
broadcast inputs, move results, weights stay
)
:
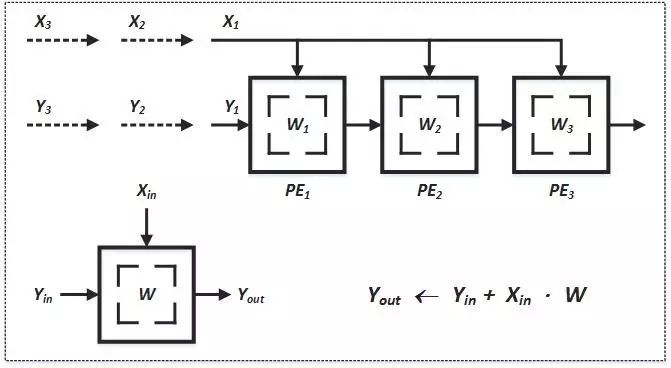
在这个例子中,X值广播到各个运算单元,W值预先存储在PE中并保持不动,而部分结果Y采用脉动的方式在PE阵列间向右传递(初始值为零)。不难看出,经过三个时刻,最右边的PE的输出就是X和W两个序列的卷积运算的第一个结果,这之后就会不断输出Y值。
文中还给出了其它几种实现卷积的方式,如
broadcast inputs, move weights, results stay;fan-in results, move inputs, weights stay
。这几种都算作“
(Semi-) systolic convolution arrays with global data communication
”。另外还有一大类是“
(Pure-) systolic convolution arrays without global data communication
”,包括
results stay, inputs and weights move in opposite directions;results stay, inputs and weights move in the same direction but at different speeds;weights stay, inputs and results move in opposite direction;weights stay, inputs and results move in the same direction but at different speeds
。建议大家好好看看,还是挺有启发的。
那么二维的脉动阵列如何做矩阵相乘呢?下面这个例子比较清楚。A和B都是3x3矩阵,T表示时刻。
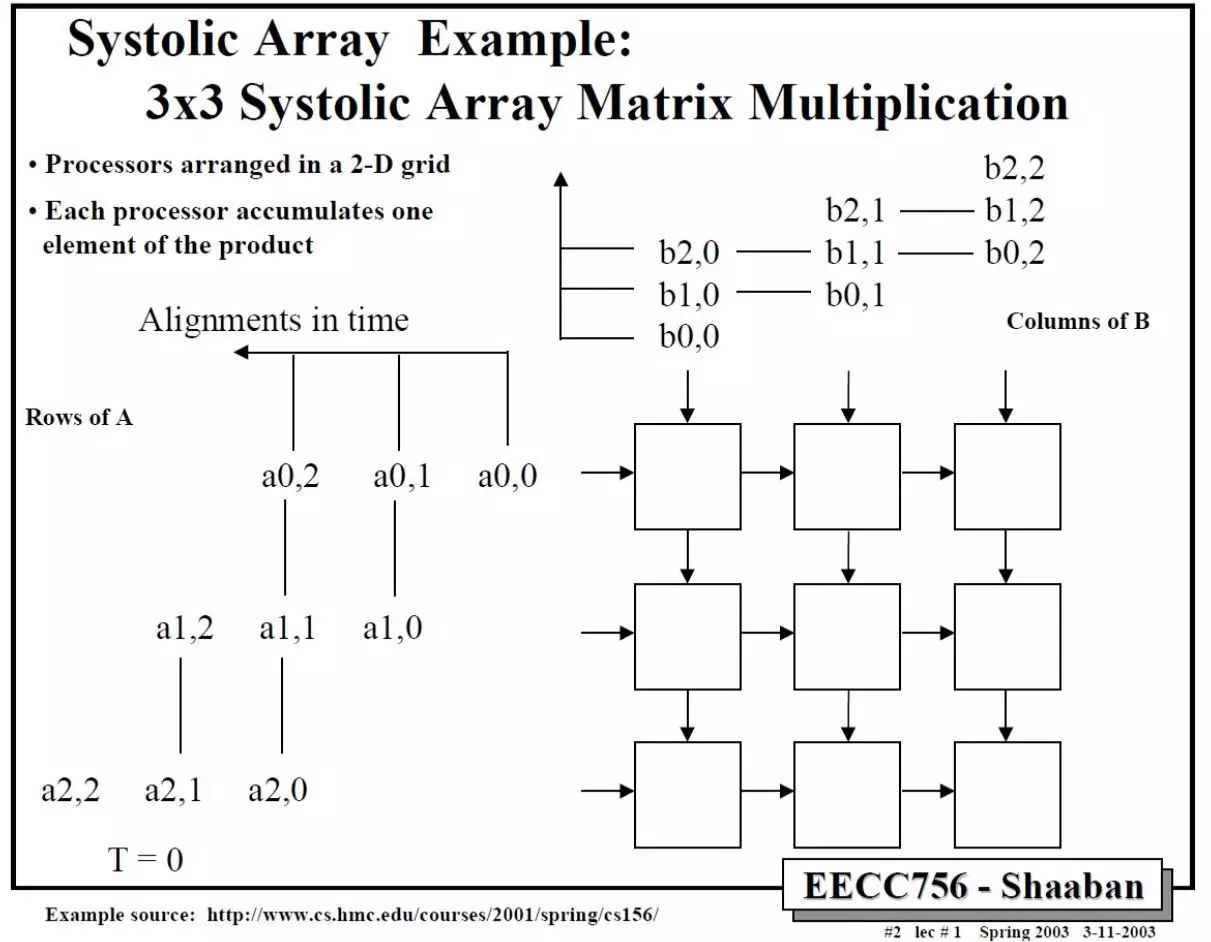
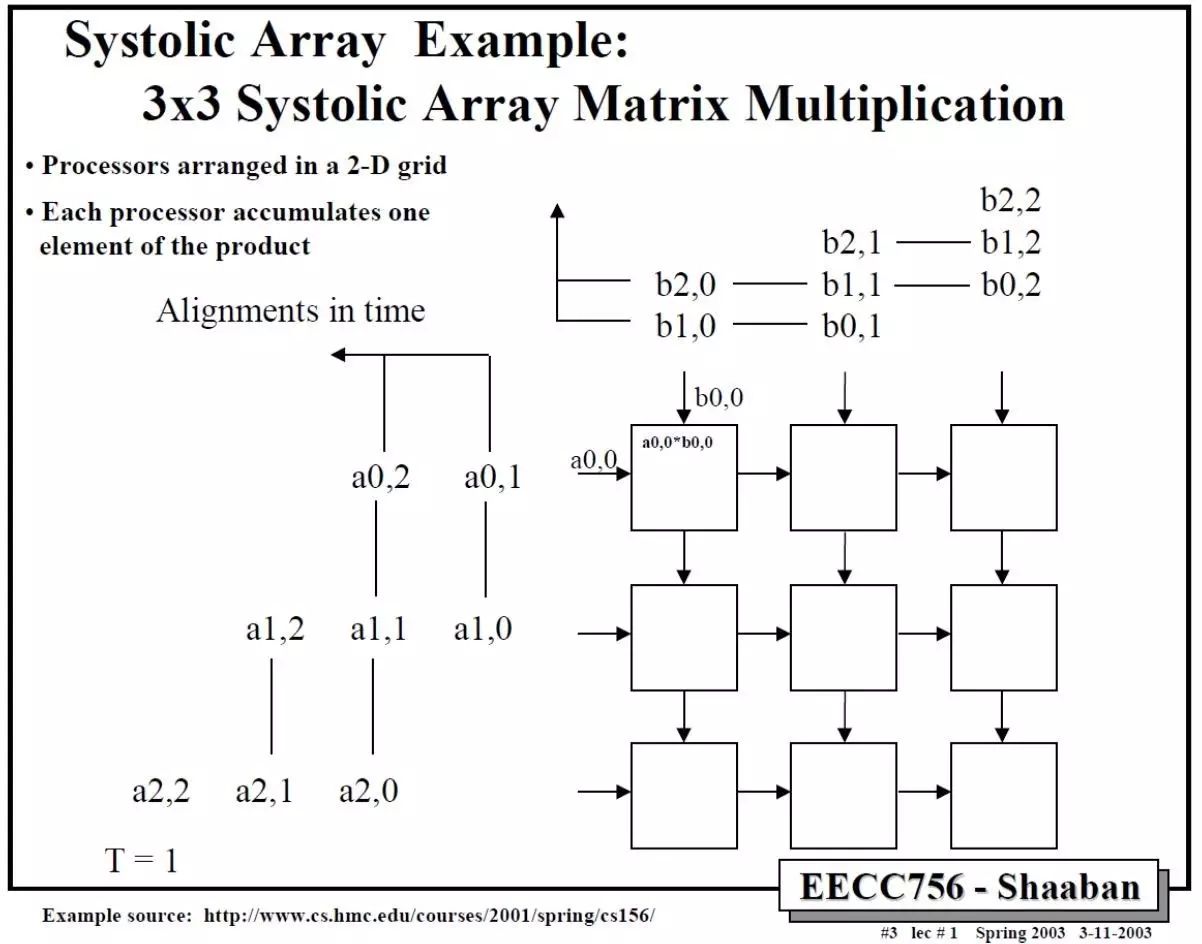
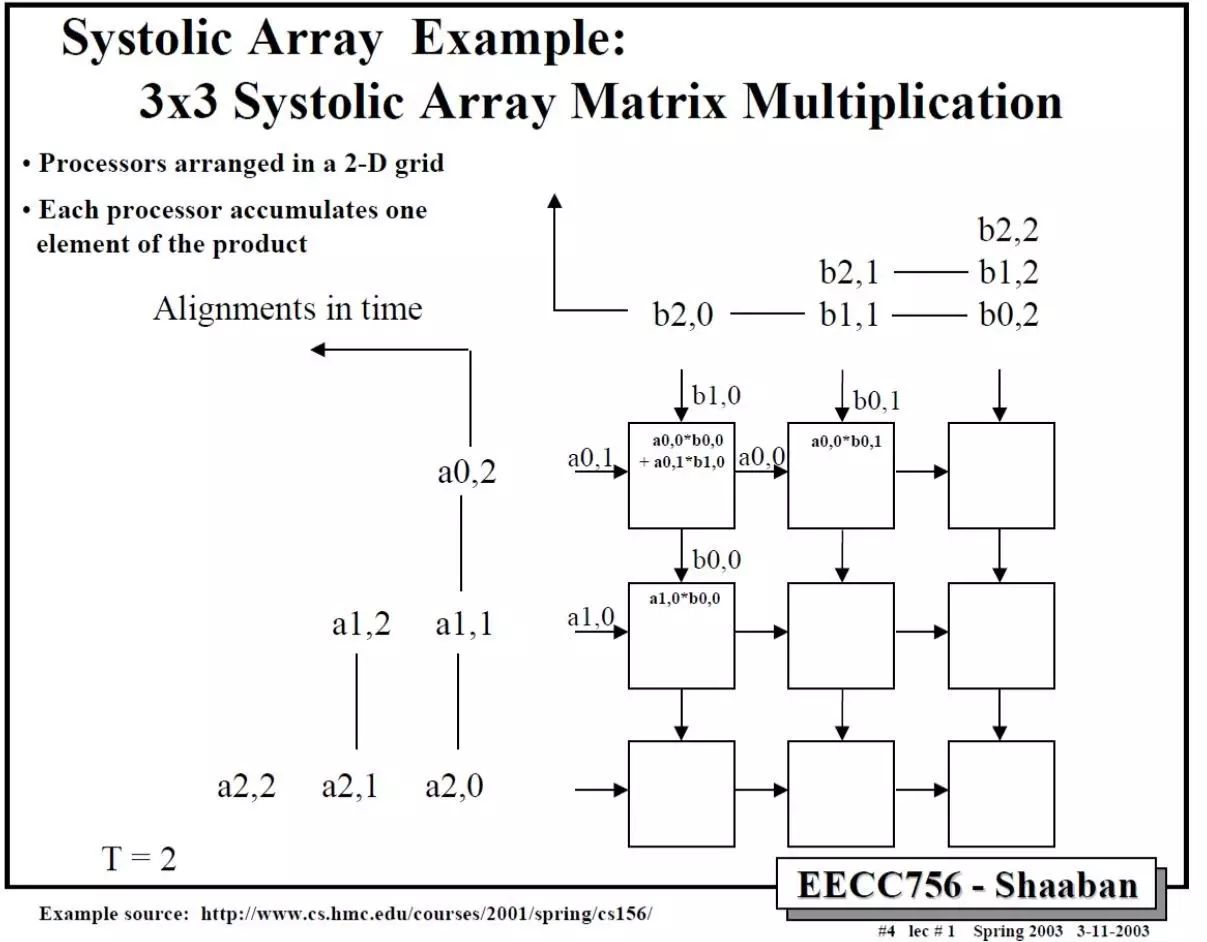
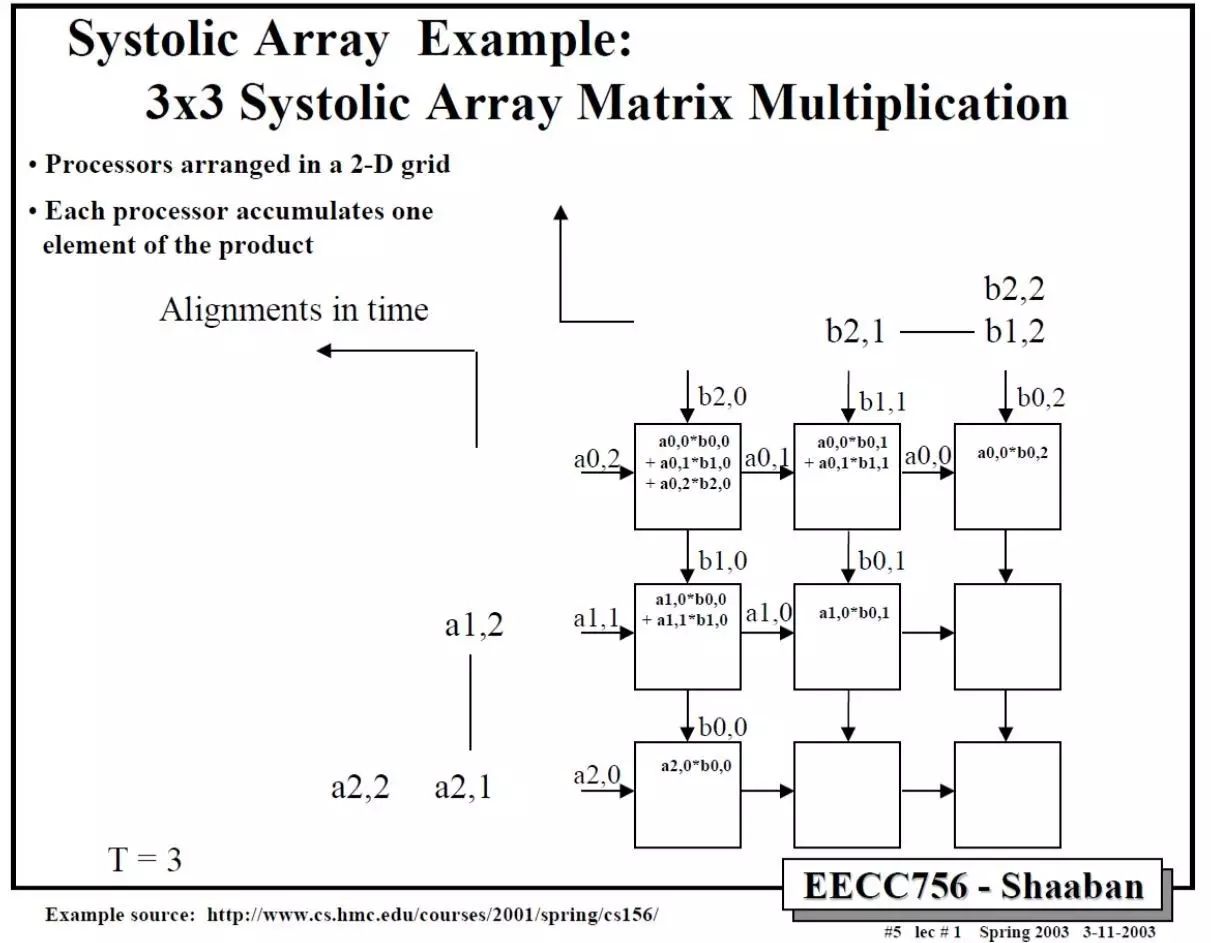
依此类推,中间省略几步,可以得到最后结果。
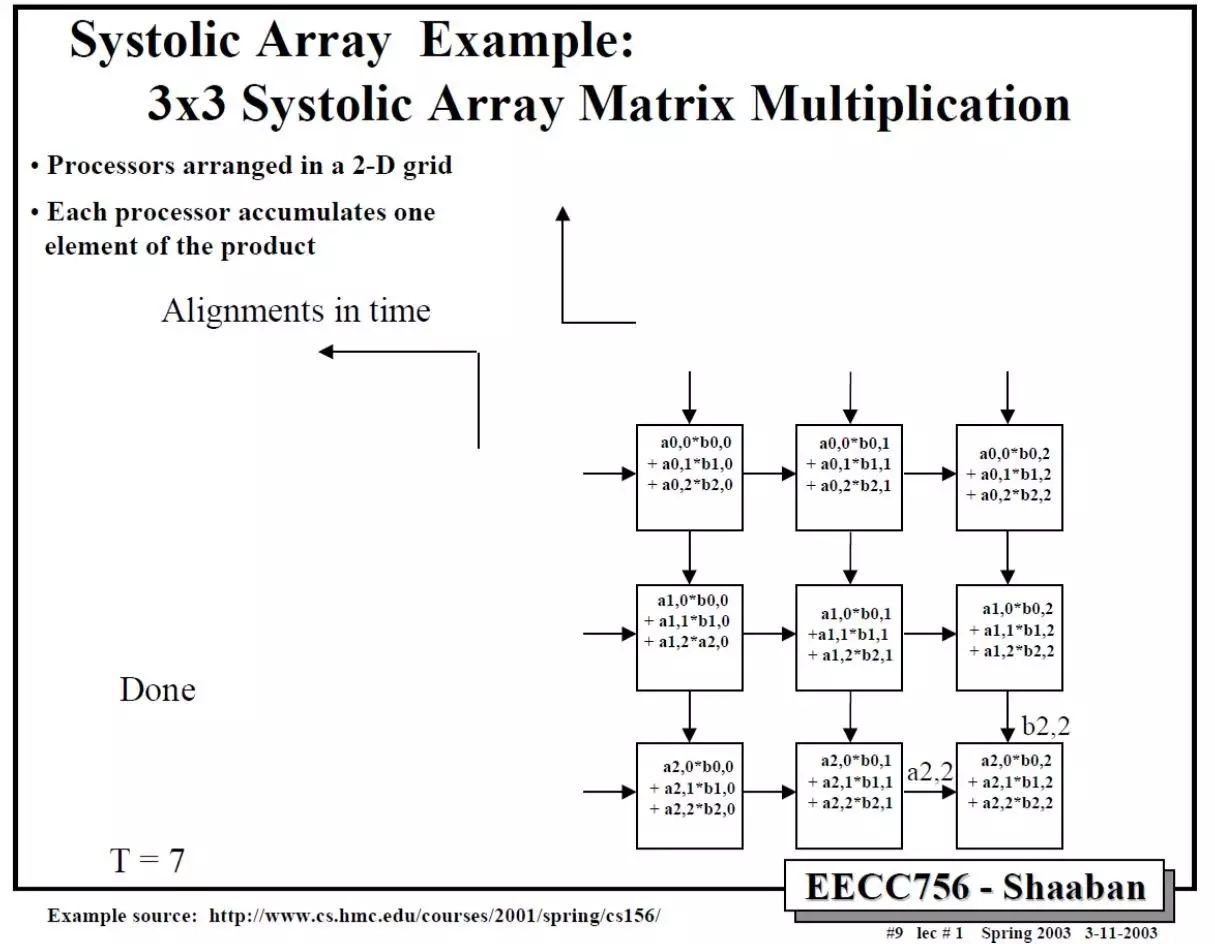
这里值得注意的是,要实现正确的矩阵运算,数据进入脉动阵列需要调整好形式,并且按照一定的顺序。这就
需要对原始的矩阵进行一些reformat
,这也增加了额外的操作。在后面对Google TPU的讨论中,我们可以更清楚的看到这一问题。
除了卷积运算,作者在文章中还说明的脉动架构适合的其它运算,主要包括信号和图像处理(signal and image processing),矩阵算术(matrix arithmetic)和一些非数值型应用(non-numeric application)。不过,由于脉动架构的灵活性较差,加之当时半导体技术的限制,它在被发明之后并没有得到广泛的应用。
时至今日,在我们设计Deep Learning处理器的时候,面对的一个主要矛盾仍然是I/O和处理不平衡的问题。这种不平衡既体现在速度上,也体现在功耗上。而一种减少I/O操作的思路 “…discuss how dataflows can increase data reuse from low cost memories in the memory hierarchy”[2],和脉动架构的方法是类似的。而另一方面,深度神经网络中大量使用了卷积运算和矩阵运算,这正好也是是脉动架构的优势。所以,在很多DL处理器中我们都可以看到脉动架构的影子(虽然有或多或少的变化和改进)。而Google TPU的设计更是让脉动阵列成了大家关注的焦点。










